 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Based Models for Text
Apr 06, 2020
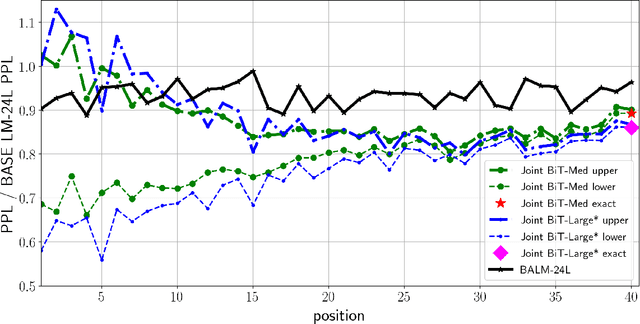

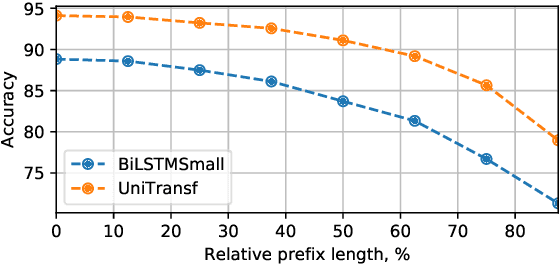
Current large-scale auto-regressive language models display impressive fluency and can generate convincing text. In this work we start by asking the question: Can the generations of these models be reliably distinguished from real text by statistical discriminators? We find experimentally that the answer is affirmative when we have access to the training data for the model, and guardedly affirmative even if we do not. This suggests that the auto-regressive models can be improved by incorporating the (globally normalized) discriminators into the generative process. We give a formalism for this using the Energy-Based Model framework, and show that it indeed improves the results of the generative models, measured both in terms of perplexity and in terms of human evaluation.
PyTorch: An Imperative Style, High-Performance Deep Learning Library
Dec 03, 2019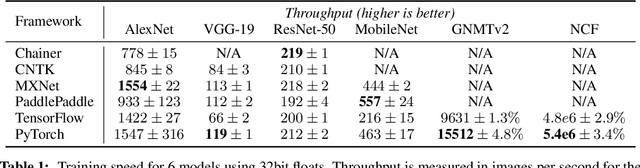

Deep learning frameworks have often focused on either usability or speed, but not both. PyTorch is a machine learning library that shows that these two goals are in fact compatible: it provides an imperative and Pythonic programming style that supports code as a model, makes debugging easy and is consistent with other popular scientific computing libraries, while remaining efficient and supporting hardware accelerators such as GPUs. In this paper, we detail the principles that drove the implementation of PyTorch and how they are reflected in its architecture. We emphasize that every aspect of PyTorch is a regular Python program under the full control of its user. We also explain how the careful and pragmatic implementation of the key components of its runtime enables them to work together to achieve compelling performance. We demonstrate the efficiency of individual subsystems, as well as the overall speed of PyTorch on several common benchmarks.
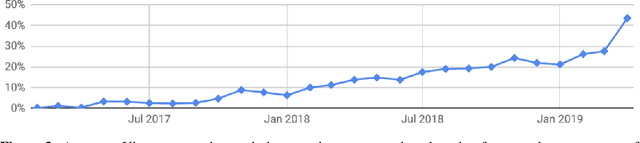
Real or Fake? Learning to Discriminate Machine from Human Generated Text
Jun 07, 2019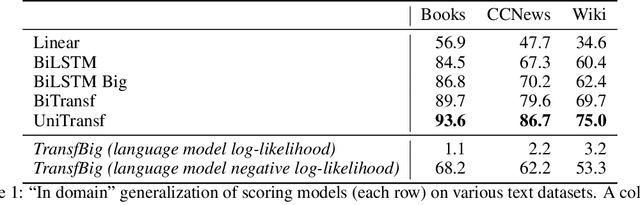
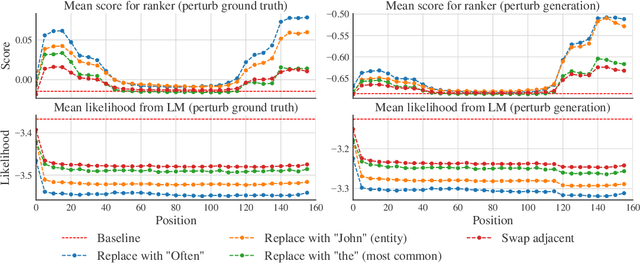
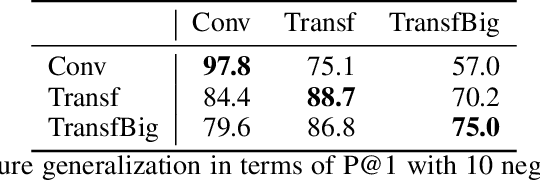
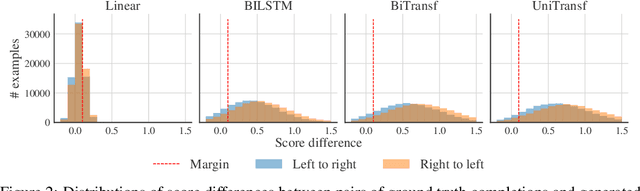
Recent advances in generative modeling of text have demonstrated remarkable improvements in terms of fluency and coherency. In this work we investigate to which extent a machine can discriminate real from machine generated text. This is important in itself for automatic detection of computer generated stories, but can also serve as a tool for further improving text generation. We show that learning a dedicated scoring function to discriminate between real and fake text achieves higher precision than employing the likelihood of a generative model. The scoring functions generalize to other generators than those used for training as long as these generators have comparable model complexity and are trained on similar datasets.
fairseq: A Fast, Extensible Toolkit for Sequence Modeling
Apr 01, 2019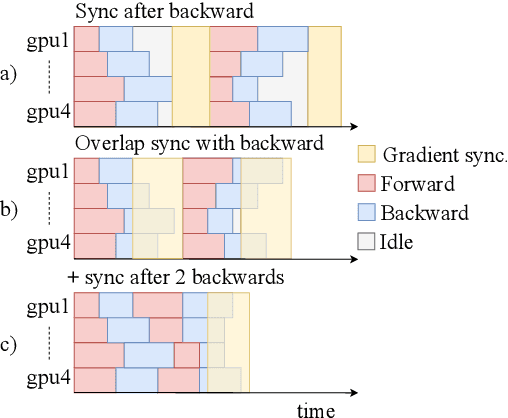

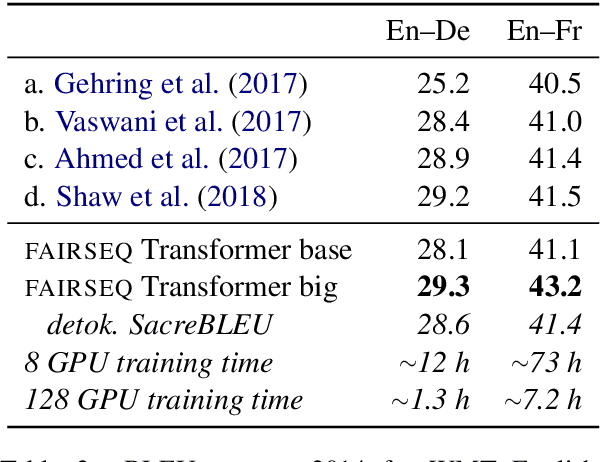
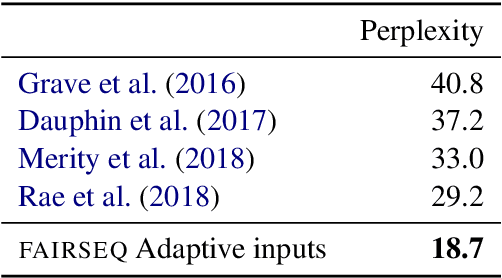
fairseq is an open-source sequence modeling toolkit that allows researchers and developers to train custom models for translation, summarization, language modeling, and other text generation tasks. The toolkit is based on PyTorch and supports distributed training across multiple GPUs and machines. We also support fast mixed-precision training and inference on modern GPUs. A demo video can be found at https://www.youtube.com/watch?v=OtgDdWtHvto
Deep Counterfactual Regret Minimization
Nov 01, 2018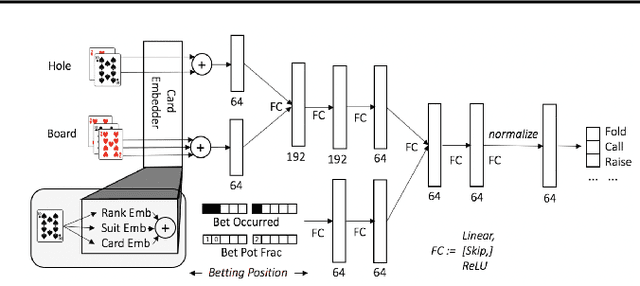

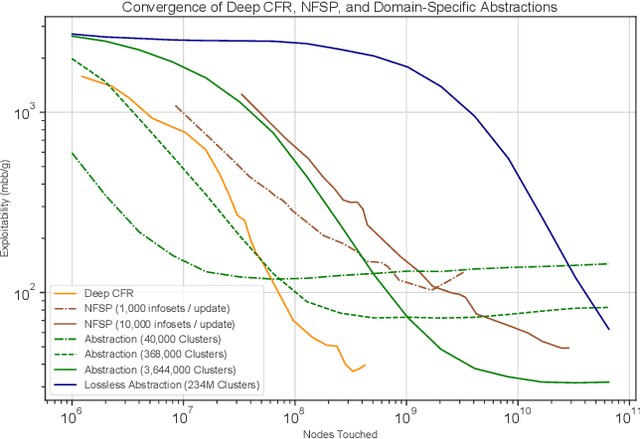
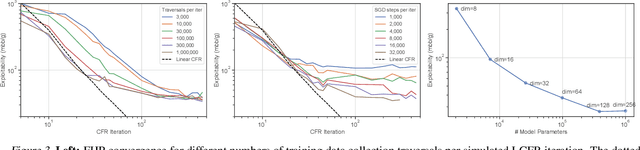
Counterfactual Regret Minimization (CFR) is the leading algorithm for solving large imperfect-information games. It iteratively traverses the game tree in order to converge to a Nash equilibrium. In order to deal with extremely large games, CFR typically uses domain-specific heuristics to simplify the target game in a process known as abstraction. This simplified game is solved with tabular CFR, and its solution is mapped back to the full game. This paper introduces Deep Counterfactual Regret Minimization (Deep CFR), a form of CFR that obviates the need for abstraction by instead using deep neural networks to approximate the behavior of CFR in the full game. We show that Deep CFR is principled and achieves strong performance in the benchmark game of heads-up no-limit Texas hold'em poker. This is the first successful use of function approximation in CFR for large games.
Hard Mixtures of Experts for Large Scale Weakly Supervised Vision
Apr 20, 2017
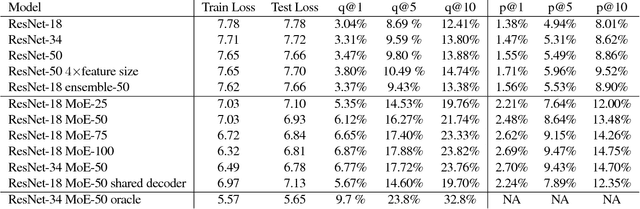

Training convolutional networks (CNN's) that fit on a single GPU with minibatch stochastic gradient descent has become effective in practice. However, there is still no effective method for training large CNN's that do not fit in the memory of a few GPU cards, or for parallelizing CNN training. In this work we show that a simple hard mixture of experts model can be efficiently trained to good effect on large scale hashtag (multilabel) prediction tasks. Mixture of experts models are not new (Jacobs et. al. 1991, Collobert et. al. 2003), but in the past, researchers have had to devise sophisticated methods to deal with data fragmentation. We show empirically that modern weakly supervised data sets are large enough to support naive partitioning schemes where each data point is assigned to a single expert. Because the experts are independent, training them in parallel is easy, and evaluation is cheap for the size of the model. Furthermore, we show that we can use a single decoding layer for all the experts, allowing a unified feature embedding space. We demonstrate that it is feasible (and in fact relatively painless) to train far larger models than could be practically trained with standard CNN architectures, and that the extra capacity can be well used on current datasets.
Semi-Supervised Learning with Context-Conditional Generative Adversarial Networks
Nov 19, 2016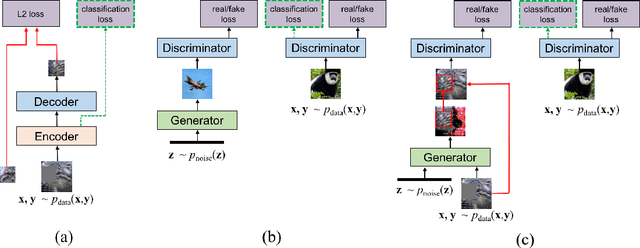

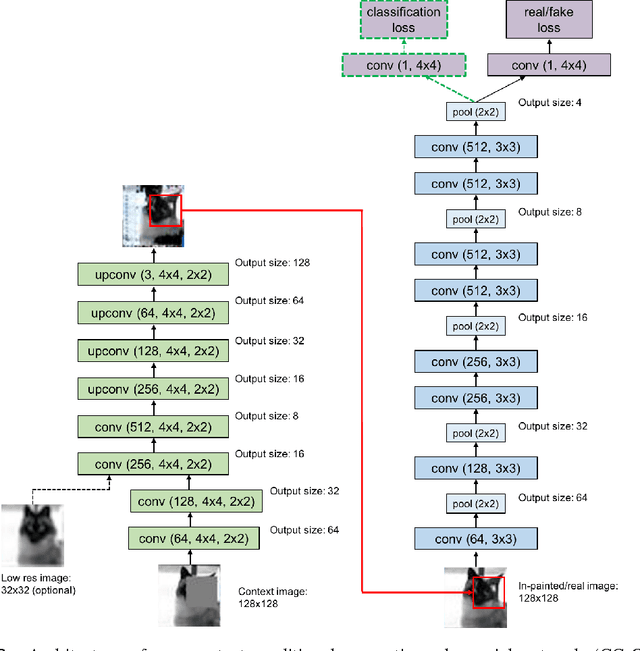

We introduce a simple semi-supervised learning approach for images based on in-painting using an adversarial loss. Images with random patches removed are presented to a generator whose task is to fill in the hole, based on the surrounding pixels. The in-painted images are then presented to a discriminator network that judges if they are real (unaltered training images) or not. This task acts as a regularizer for standard supervised training of the discriminator. Using our approach we are able to directly train large VGG-style networks in a semi-supervised fashion. We evaluate on STL-10 and PASCAL datasets, where our approach obtains performance comparable or superior to existing methods.
A MultiPath Network for Object Detection
Aug 08, 2016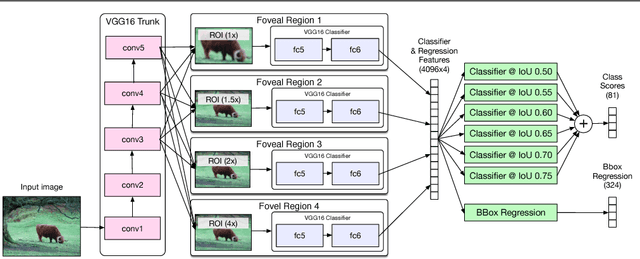



The recent COCO object detection dataset presents several new challenges for object detection. In particular, it contains objects at a broad range of scales, less prototypical images, and requires more precise localization. To address these challenges, we test three modifications to the standard Fast R-CNN object detector: (1) skip connections that give the detector access to features at multiple network layers, (2) a foveal structure to exploit object context at multiple object resolutions, and (3) an integral loss function and corresponding network adjustment that improve localization. The result of these modifications is that information can flow along multiple paths in our network, including through features from multiple network layers and from multiple object views. We refer to our modified classifier as a "MultiPath" network. We couple our MultiPath network with DeepMask object proposals, which are well suited for localization and small objects, and adapt our pipeline to predict segmentation masks in addition to bounding boxes. The combined system improves results over the baseline Fast R-CNN detector with Selective Search by 66% overall and by 4x on small objects. It placed second in both the COCO 2015 detection and segmentation challenges.
Learning Physical Intuition of Block Towers by Example
Mar 03, 2016
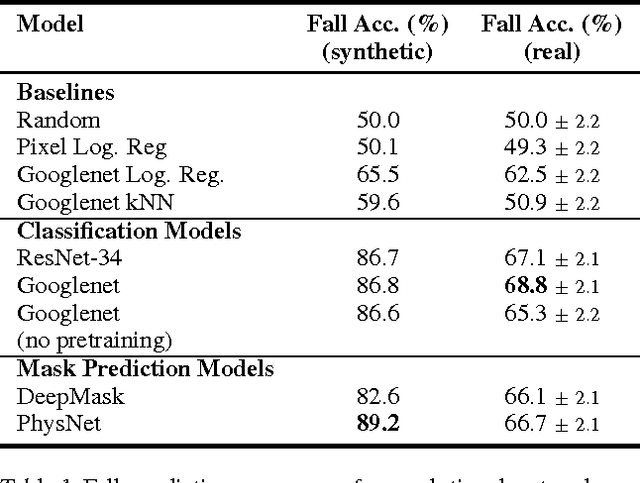
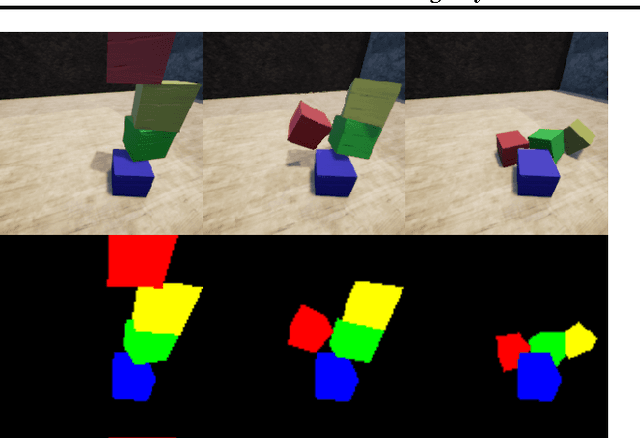

Wooden blocks are a common toy for infants, allowing them to develop motor skills and gain intuition about the physical behavior of the world. In this paper, we explore the ability of deep feed-forward models to learn such intuitive physics. Using a 3D game engine, we create small towers of wooden blocks whose stability is randomized and render them collapsing (or remaining upright). This data allows us to train large convolutional network models which can accurately predict the outcome, as well as estimating the block trajectories. The models are also able to generalize in two important ways: (i) to new physical scenarios, e.g. towers with an additional block and (ii) to images of real wooden blocks, where it obtains a performance comparable to human subjects.