 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaintBench: Deterministic Evaluation of Precise Visual Editing
May 29, 2026While current multimodal models are proficient at open-ended visual editing, executing precise single-answer edits remains an important obstacle. To probe this challenge, we introduce PaintBench, a dynamically scalable benchmark targeting 20 fundamental precise visual editing operations across four categories: geometric transformation, structural manipulation, color change, and symbolic reasoning. Procedural generation with configurable complexity enables an effectively infinite, contamination-resistant evaluation suite, and deterministic pixel-level evaluation eliminates reliance on bias-prone judge models. Across 11 image editing models, we find overall low performance, with the current highest-performing industry leader scoring only 17.1% (mIoU). Task decomposition reveals especially challenging operation types (geometric transformation, most structural manipulation, formula-based color change) and model-specific specializations. Fine-grained benchmark diagnostics further show performance degradations induced by scene variations in object count, background complexity, color scheme, and edit-region size. To test generalization of PaintBench scores to applied task performance, we create a procedural, deterministic evaluation for data visualization editing (TinyGrafixBench) and find strong linear correlation with PaintBench scores ($R^2 = 0.91$, $p < 0.001$). Altogether, PaintBench provides a rigorous foundation for measuring and driving progress in precise multimodal visual editing.
Beyond Language Modeling: An Exploration of Multimodal Pretraining
Mar 03, 2026The visual world offers a critical axis for advancing foundation models beyond language. Despite growing interest in this direction, the design space for native multimodal models remains opaque. We provide empirical clarity through controlled, from-scratch pretraining experiments, isolating the factors that govern multimodal pretraining without interference from language pretraining. We adopt the Transfusion framework, using next-token prediction for language and diffusion for vision, to train on diverse data including text, video, image-text pairs, and even action-conditioned video. Our experiments yield four key insights: (i) Representation Autoencoder (RAE) provides an optimal unified visual representation by excelling at both visual understanding and generation; (ii) visual and language data are complementary and yield synergy for downstream capabilities; (iii) unified multimodal pretraining leads naturally to world modeling, with capabilities emerging from general training; and (iv) Mixture-of-Experts (MoE) enables efficient and effective multimodal scaling while naturally inducing modality specialization. Through IsoFLOP analysis, we compute scaling laws for both modalities and uncover a scaling asymmetry: vision is significantly more data-hungry than language. We demonstrate that the MoE architecture harmonizes this scaling asymmetry by providing the high model capacity required by language while accommodating the data-intensive nature of vision, paving the way for truly unified multimodal models.
Scaling Text-to-Image Diffusion Transformers with Representation Autoencoders
Jan 22, 2026Representation Autoencoders (RAEs) have shown distinct advantages in diffusion modeling on ImageNet by training in high-dimensional semantic latent spaces. In this work, we investigate whether this framework can scale to large-scale, freeform text-to-image (T2I) generation. We first scale RAE decoders on the frozen representation encoder (SigLIP-2) beyond ImageNet by training on web, synthetic, and text-rendering data, finding that while scale improves general fidelity, targeted data composition is essential for specific domains like text. We then rigorously stress-test the RAE design choices originally proposed for ImageNet. Our analysis reveals that scaling simplifies the framework: while dimension-dependent noise scheduling remains critical, architectural complexities such as wide diffusion heads and noise-augmented decoding offer negligible benefits at scale Building on this simplified framework, we conduct a controlled comparison of RAE against the state-of-the-art FLUX VAE across diffusion transformer scales from 0.5B to 9.8B parameters. RAEs consistently outperform VAEs during pretraining across all model scales. Further, during finetuning on high-quality datasets, VAE-based models catastrophically overfit after 64 epochs, while RAE models remain stable through 256 epochs and achieve consistently better performance. Across all experiments, RAE-based diffusion models demonstrate faster convergence and better generation quality, establishing RAEs as a simpler and stronger foundation than VAEs for large-scale T2I generation. Additionally, because both visual understanding and generation can operate in a shared representation space, the multimodal model can directly reason over generated latents, opening new possibilities for unified models.
SIMS-V: Simulated Instruction-Tuning for Spatial Video Understanding
Nov 06, 2025Despite impressive high-level video comprehension, multimodal language models struggle with spatial reasoning across time and space. While current spatial training approaches rely on real-world video data, obtaining diverse footage with precise spatial annotations remains a bottleneck. To alleviate this bottleneck, we present SIMS-V -- a systematic data-generation framework that leverages the privileged information of 3D simulators to create spatially-rich video training data for multimodal language models. Using this framework, we investigate which properties of simulated data drive effective real-world transfer through systematic ablations of question types, mixes, and scales. We identify a minimal set of three question categories (metric measurement, perspective-dependent reasoning, and temporal tracking) that prove most effective for developing transferable spatial intelligence, outperforming comprehensive coverage despite using fewer question types. These insights enable highly efficient training: our 7B-parameter video LLM fine-tuned on just 25K simulated examples outperforms the larger 72B baseline and achieves competitive performance with proprietary models on rigorous real-world spatial reasoning benchmarks. Our approach demonstrates robust generalization, maintaining performance on general video understanding while showing substantial improvements on embodied and real-world spatial tasks.
Benchmark Designers Should "Train on the Test Set" to Expose Exploitable Non-Visual Shortcuts
Nov 06, 2025Robust benchmarks are crucial for evaluating Multimodal Large Language Models (MLLMs). Yet we find that models can ace many multimodal benchmarks without strong visual understanding, instead exploiting biases, linguistic priors, and superficial patterns. This is especially problematic for vision-centric benchmarks that are meant to require visual inputs. We adopt a diagnostic principle for benchmark design: if a benchmark can be gamed, it will be. Designers should therefore try to ``game'' their own benchmarks first, using diagnostic and debiasing procedures to systematically identify and mitigate non-visual biases. Effective diagnosis requires directly ``training on the test set'' -- probing the released test set for its intrinsic, exploitable patterns. We operationalize this standard with two components. First, we diagnose benchmark susceptibility using a ``Test-set Stress-Test'' (TsT) methodology. Our primary diagnostic tool involves fine-tuning a powerful Large Language Model via $k$-fold cross-validation on exclusively the non-visual, textual inputs of the test set to reveal shortcut performance and assign each sample a bias score $s(x)$. We complement this with a lightweight Random Forest-based diagnostic operating on hand-crafted features for fast, interpretable auditing. Second, we debias benchmarks by filtering high-bias samples using an ``Iterative Bias Pruning'' (IBP) procedure. Applying this framework to four benchmarks -- VSI-Bench, CV-Bench, MMMU, and VideoMME -- we uncover pervasive non-visual biases. As a case study, we apply our full framework to create VSI-Bench-Debiased, demonstrating reduced non-visual solvability and a wider vision-blind performance gap than the original.
Cambrian-S: Towards Spatial Supersensing in Video
Nov 06, 2025We argue that progress in true multimodal intelligence calls for a shift from reactive, task-driven systems and brute-force long context towards a broader paradigm of supersensing. We frame spatial supersensing as four stages beyond linguistic-only understanding: semantic perception (naming what is seen), streaming event cognition (maintaining memory across continuous experiences), implicit 3D spatial cognition (inferring the world behind pixels), and predictive world modeling (creating internal models that filter and organize information). Current benchmarks largely test only the early stages, offering narrow coverage of spatial cognition and rarely challenging models in ways that require true world modeling. To drive progress in spatial supersensing, we present VSI-SUPER, a two-part benchmark: VSR (long-horizon visual spatial recall) and VSC (continual visual spatial counting). These tasks require arbitrarily long video inputs yet are resistant to brute-force context expansion. We then test data scaling limits by curating VSI-590K and training Cambrian-S, achieving +30% absolute improvement on VSI-Bench without sacrificing general capabilities. Yet performance on VSI-SUPER remains limited, indicating that scale alone is insufficient for spatial supersensing. We propose predictive sensing as a path forward, presenting a proof-of-concept in which a self-supervised next-latent-frame predictor leverages surprise (prediction error) to drive memory and event segmentation. On VSI-SUPER, this approach substantially outperforms leading proprietary baselines, showing that spatial supersensing requires models that not only see but also anticipate, select, and organize experience.
KL-Regularized Reinforcement Learning is Designed to Mode Collapse
Oct 23, 2025It is commonly believed that optimizing the reverse KL divergence results in "mode seeking", while optimizing forward KL results in "mass covering", with the latter being preferred if the goal is to sample from multiple diverse modes. We show -- mathematically and empirically -- that this intuition does not necessarily transfer well to doing reinforcement learning with reverse/forward KL regularization (e.g. as commonly used with language models). Instead, the choice of reverse/forward KL determines the family of optimal target distributions, parameterized by the regularization coefficient. Mode coverage depends primarily on other factors, such as regularization strength, and relative scales between rewards and reference probabilities. Further, we show commonly used settings such as low regularization strength and equal verifiable rewards tend to specify unimodal target distributions, meaning the optimization objective is, by construction, non-diverse. We leverage these insights to construct a simple, scalable, and theoretically justified algorithm. It makes minimal changes to reward magnitudes, yet optimizes for a target distribution which puts high probability over all high-quality sampling modes. In experiments, this simple modification works to post-train both Large Language Models and Chemical Language Models to have higher solution quality and diversity, without any external signals of diversity, and works with both forward and reverse KL when using either naively fails.
Language Agents Mirror Human Causal Reasoning Biases. How Can We Help Them Think Like Scientists?
May 14, 2025Language model (LM) agents are increasingly used as autonomous decision-makers who need to actively gather information to guide their decisions. A crucial cognitive skill for such agents is the efficient exploration and understanding of the causal structure of the world -- key to robust, scientifically grounded reasoning. Yet, it remains unclear whether LMs possess this capability or exhibit systematic biases leading to erroneous conclusions. In this work, we examine LMs' ability to explore and infer causal relationships, using the well-established "Blicket Test" paradigm from developmental psychology. We find that LMs reliably infer the common, intuitive disjunctive causal relationships but systematically struggle with the unusual, yet equally (or sometimes even more) evidenced conjunctive ones. This "disjunctive bias" persists across model families, sizes, and prompting strategies, and performance further declines as task complexity increases. Interestingly, an analogous bias appears in human adults, suggesting that LMs may have inherited deep-seated reasoning heuristics from their training data. To this end, we quantify similarities between LMs and humans, finding that LMs exhibit adult-like inference profiles (but not children-like). Finally, we propose a test-time sampling method which explicitly samples and eliminates hypotheses about causal relationships from the LM. This scalable approach significantly reduces the disjunctive bias and moves LMs closer to the goal of scientific, causally rigorous reasoning.
BALROG: Benchmarking Agentic LLM and VLM Reasoning On Games
Nov 20, 2024



Large Language Models (LLMs) and Vision Language Models (VLMs) possess extensive knowledge and exhibit promising reasoning abilities; however, they still struggle to perform well in complex, dynamic environments. Real-world tasks require handling intricate interactions, advanced spatial reasoning, long-term planning, and continuous exploration of new strategies-areas in which we lack effective methodologies for comprehensively evaluating these capabilities. To address this gap, we introduce BALROG, a novel benchmark designed to assess the agentic capabilities of LLMs and VLMs through a diverse set of challenging games. Our benchmark incorporates a range of existing reinforcement learning environments with varying levels of difficulty, including tasks that are solvable by non-expert humans in seconds to extremely challenging ones that may take years to master (e.g., the NetHack Learning Environment). We devise fine-grained metrics to measure performance and conduct an extensive evaluation of several popular open-source and closed-source LLMs and VLMs. Our findings indicate that while current models achieve partial success in the easier games, they struggle significantly with more challenging tasks. Notably, we observe severe deficiencies in vision-based decision-making, as models perform worse when visual representations of the environments are provided. We release BALROG as an open and user-friendly benchmark to facilitate future research and development in the agentic community.
Training Language Models on Synthetic Edit Sequences Improves Code Synthesis
Oct 03, 2024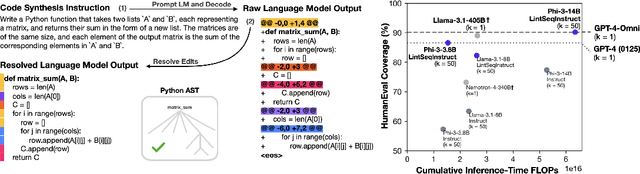

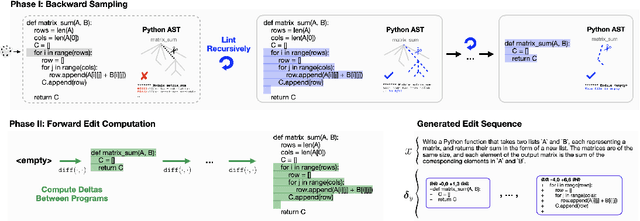
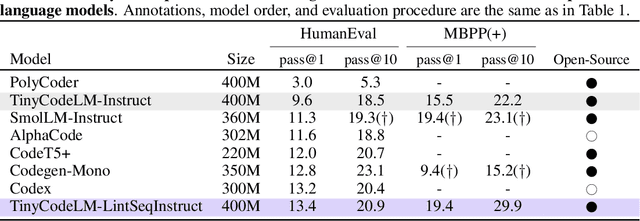
Software engineers mainly write code by editing existing programs. In contrast, large language models (LLMs) autoregressively synthesize programs in a single pass. One explanation for this is the scarcity of open-sourced edit data. While high-quality instruction data for code synthesis is already scarce, high-quality edit data is even scarcer. To fill this gap, we develop a synthetic data generation algorithm called LintSeq. This algorithm refactors existing code into a sequence of code edits by using a linter to procedurally sample across the error-free insertions that can be used to sequentially write programs. It outputs edit sequences as text strings consisting of consecutive program diffs. To test LintSeq, we use it to refactor a dataset of instruction + program pairs into instruction + program-diff-sequence tuples. Then, we instruction finetune a series of smaller LLMs ranging from 2.6B to 14B parameters on both the re-factored and original versions of this dataset, comparing zero-shot performance on code synthesis benchmarks. We show that during repeated sampling, edit sequence finetuned models produce more diverse programs than baselines. This results in better inference-time scaling for benchmark coverage as a function of samples, i.e. the fraction of problems "pass@k" solved by any attempt given "k" tries. For example, on HumanEval pass@50, small LLMs finetuned on synthetic edit sequences are competitive with GPT-4 and outperform models finetuned on the baseline dataset by +20% (+/-3%) in absolute score. Finally, we also pretrain our own tiny LMs for code understanding. We show that finetuning tiny models on synthetic code edits results in state-of-the-art code synthesis for the on-device model class. Our 150M parameter edit sequence LM matches or outperforms code models with twice as many parameters, both with and without repeated sampling, including Codex and AlphaCode.