 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning When to Plan: Efficiently Allocating Test-Time Compute for LLM Agents
Sep 03, 2025Training large language models (LLMs) to reason via reinforcement learning (RL) significantly improves their problem-solving capabilities. In agentic settings, existing methods like ReAct prompt LLMs to explicitly plan before every action; however, we demonstrate that always planning is computationally expensive and degrades performance on long-horizon tasks, while never planning further limits performance. To address this, we introduce a conceptual framework formalizing dynamic planning for LLM agents, enabling them to flexibly decide when to allocate test-time compute for planning. We propose a simple two-stage training pipeline: (1) supervised fine-tuning on diverse synthetic data to prime models for dynamic planning, and (2) RL to refine this capability in long-horizon environments. Experiments on the Crafter environment show that dynamic planning agents trained with this approach are more sample-efficient and consistently achieve more complex objectives. Additionally, we demonstrate that these agents can be effectively steered by human-written plans, surpassing their independent capabilities. To our knowledge, this work is the first to explore training LLM agents for dynamic test-time compute allocation in sequential decision-making tasks, paving the way for more efficient, adaptive, and controllable agentic systems.
BALROG: Benchmarking Agentic LLM and VLM Reasoning On Games
Nov 20, 2024



Large Language Models (LLMs) and Vision Language Models (VLMs) possess extensive knowledge and exhibit promising reasoning abilities; however, they still struggle to perform well in complex, dynamic environments. Real-world tasks require handling intricate interactions, advanced spatial reasoning, long-term planning, and continuous exploration of new strategies-areas in which we lack effective methodologies for comprehensively evaluating these capabilities. To address this gap, we introduce BALROG, a novel benchmark designed to assess the agentic capabilities of LLMs and VLMs through a diverse set of challenging games. Our benchmark incorporates a range of existing reinforcement learning environments with varying levels of difficulty, including tasks that are solvable by non-expert humans in seconds to extremely challenging ones that may take years to master (e.g., the NetHack Learning Environment). We devise fine-grained metrics to measure performance and conduct an extensive evaluation of several popular open-source and closed-source LLMs and VLMs. Our findings indicate that while current models achieve partial success in the easier games, they struggle significantly with more challenging tasks. Notably, we observe severe deficiencies in vision-based decision-making, as models perform worse when visual representations of the environments are provided. We release BALROG as an open and user-friendly benchmark to facilitate future research and development in the agentic community.
Training Language Models on Synthetic Edit Sequences Improves Code Synthesis
Oct 03, 2024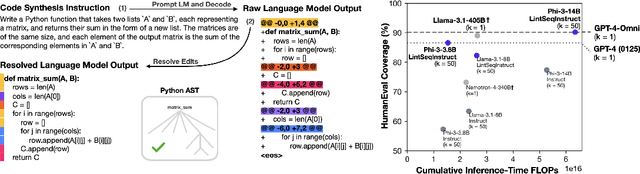

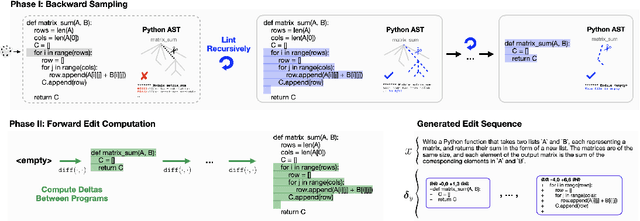
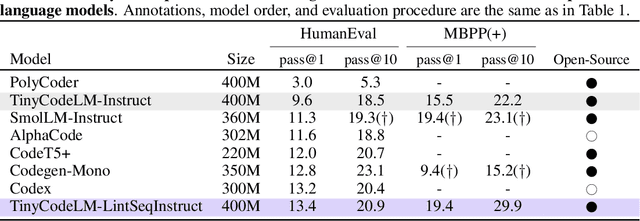
Software engineers mainly write code by editing existing programs. In contrast, large language models (LLMs) autoregressively synthesize programs in a single pass. One explanation for this is the scarcity of open-sourced edit data. While high-quality instruction data for code synthesis is already scarce, high-quality edit data is even scarcer. To fill this gap, we develop a synthetic data generation algorithm called LintSeq. This algorithm refactors existing code into a sequence of code edits by using a linter to procedurally sample across the error-free insertions that can be used to sequentially write programs. It outputs edit sequences as text strings consisting of consecutive program diffs. To test LintSeq, we use it to refactor a dataset of instruction + program pairs into instruction + program-diff-sequence tuples. Then, we instruction finetune a series of smaller LLMs ranging from 2.6B to 14B parameters on both the re-factored and original versions of this dataset, comparing zero-shot performance on code synthesis benchmarks. We show that during repeated sampling, edit sequence finetuned models produce more diverse programs than baselines. This results in better inference-time scaling for benchmark coverage as a function of samples, i.e. the fraction of problems "pass@k" solved by any attempt given "k" tries. For example, on HumanEval pass@50, small LLMs finetuned on synthetic edit sequences are competitive with GPT-4 and outperform models finetuned on the baseline dataset by +20% (+/-3%) in absolute score. Finally, we also pretrain our own tiny LMs for code understanding. We show that finetuning tiny models on synthetic code edits results in state-of-the-art code synthesis for the on-device model class. Our 150M parameter edit sequence LM matches or outperforms code models with twice as many parameters, both with and without repeated sampling, including Codex and AlphaCode.
diff History for Long-Context Language Agents
Dec 12, 2023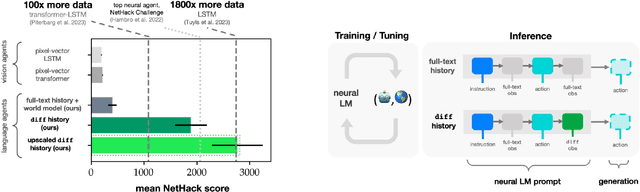
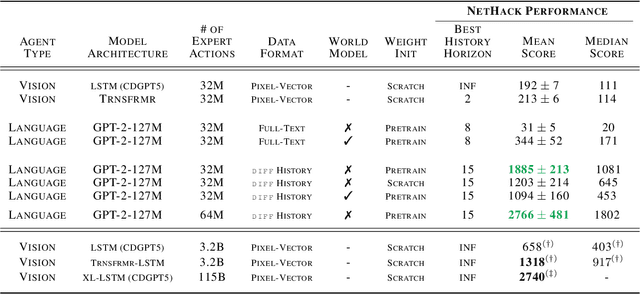
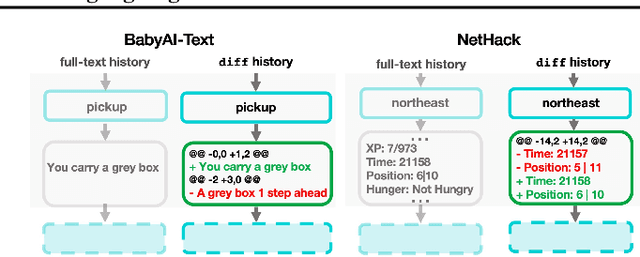
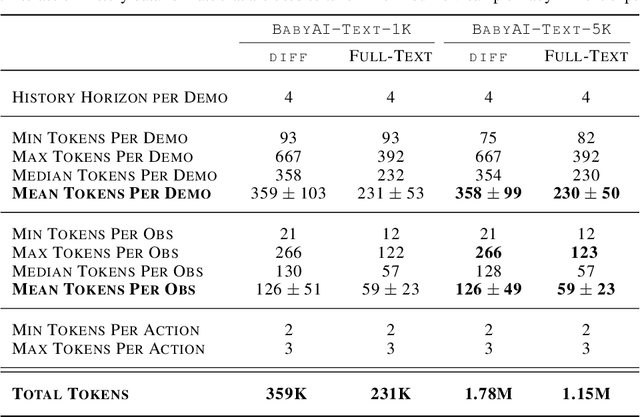
Language Models (LMs) offer an exciting solution for general-purpose embodied control. However, a key technical issue arises when using an LM-based controller: environment observations must be converted to text, which coupled with history, leads to prohibitively large textual prompts. As a result, prior work in LM agents is limited to restricted domains with either small observation size or minimal needs for interaction history. In this paper, we introduce a simple and highly effective solution to these issues. We exploit the fact that consecutive text observations have high similarity and propose to compress them via the Unix diff command. We demonstrate our approach in NetHack, a complex rogue-like video game, that requires long-horizon reasoning for decision-making and is far from solved, particularly for neural agents. Diff history offers an average of 4x increase in the length of the text-based interaction history available to the LM. This observational compression along with the benefits of abstraction yields a 7x improvement in game score on held-out environment instances over state-of-the-art baselines. It also outperforms prior agents that use visual observations by over 40%.
NetHack is Hard to Hack
May 30, 2023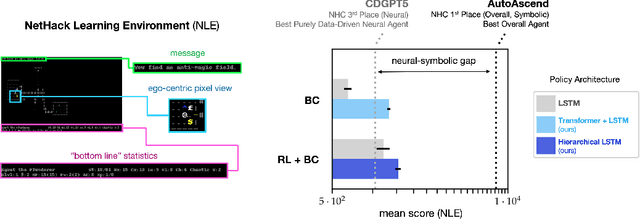
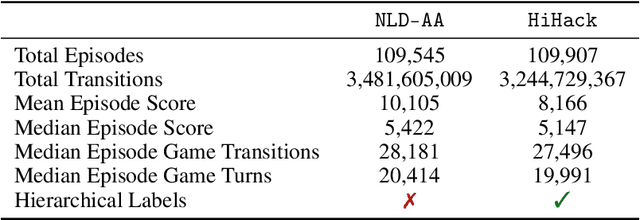
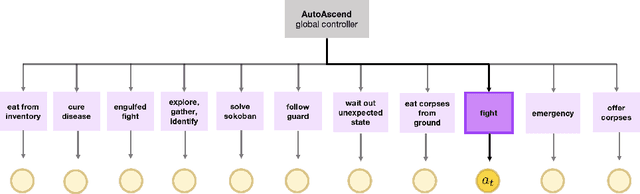
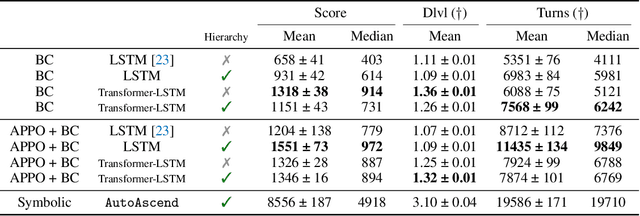
Neural policy learning methods have achieved remarkable results in various control problems, ranging from Atari games to simulated locomotion. However, these methods struggle in long-horizon tasks, especially in open-ended environments with multi-modal observations, such as the popular dungeon-crawler game, NetHack. Intriguingly, the NeurIPS 2021 NetHack Challenge revealed that symbolic agents outperformed neural approaches by over four times in median game score. In this paper, we delve into the reasons behind this performance gap and present an extensive study on neural policy learning for NetHack. To conduct this study, we analyze the winning symbolic agent, extending its codebase to track internal strategy selection in order to generate one of the largest available demonstration datasets. Utilizing this dataset, we examine (i) the advantages of an action hierarchy; (ii) enhancements in neural architecture; and (iii) the integration of reinforcement learning with imitation learning. Our investigations produce a state-of-the-art neural agent that surpasses previous fully neural policies by 127% in offline settings and 25% in online settings on median game score. However, we also demonstrate that mere scaling is insufficient to bridge the performance gap with the best symbolic models or even the top human players.