 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReST meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent
Dec 15, 2023Answering complex natural language questions often necessitates multi-step reasoning and integrating external information. Several systems have combined knowledge retrieval with a large language model (LLM) to answer such questions. These systems, however, suffer from various failure cases, and we cannot directly train them end-to-end to fix such failures, as interaction with external knowledge is non-differentiable. To address these deficiencies, we define a ReAct-style LLM agent with the ability to reason and act upon external knowledge. We further refine the agent through a ReST-like method that iteratively trains on previous trajectories, employing growing-batch reinforcement learning with AI feedback for continuous self-improvement and self-distillation. Starting from a prompted large model and after just two iterations of the algorithm, we can produce a fine-tuned small model that achieves comparable performance on challenging compositional question-answering benchmarks with two orders of magnitude fewer parameters.
Hierarchical reinforcement learning with natural language subgoals
Sep 20, 2023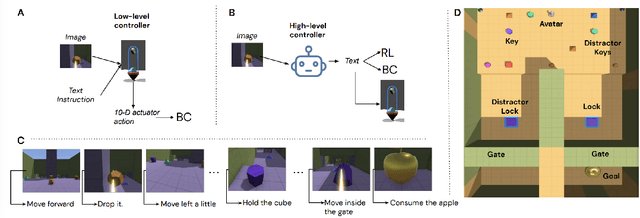
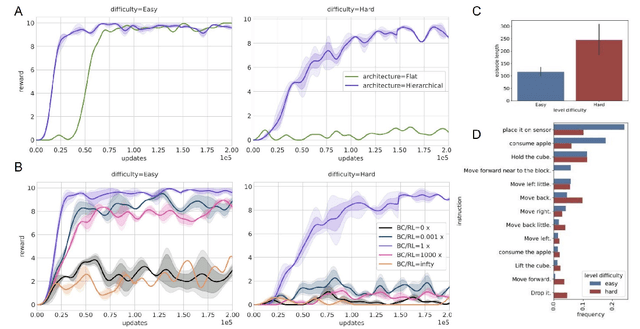
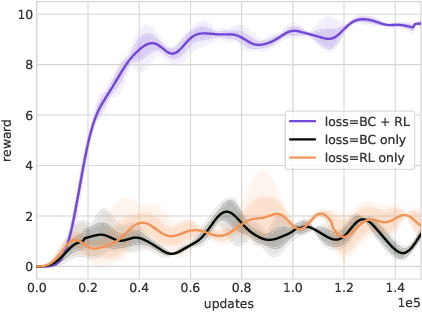
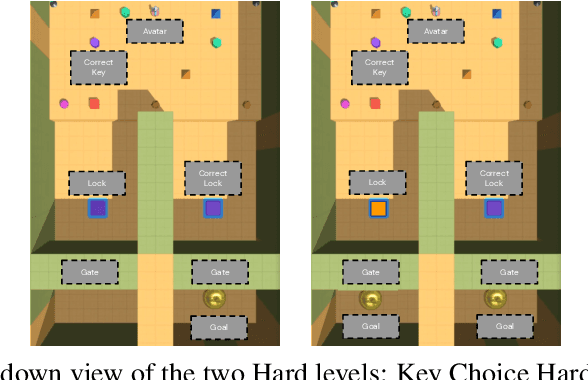
Hierarchical reinforcement learning has been a compelling approach for achieving goal directed behavior over long sequences of actions. However, it has been challenging to implement in realistic or open-ended environments. A main challenge has been to find the right space of sub-goals over which to instantiate a hierarchy. We present a novel approach where we use data from humans solving these tasks to softly supervise the goal space for a set of long range tasks in a 3D embodied environment. In particular, we use unconstrained natural language to parameterize this space. This has two advantages: first, it is easy to generate this data from naive human participants; second, it is flexible enough to represent a vast range of sub-goals in human-relevant tasks. Our approach outperforms agents that clone expert behavior on these tasks, as well as HRL from scratch without this supervised sub-goal space. Our work presents a novel approach to combining human expert supervision with the benefits and flexibility of reinforcement learning.
Melting Pot 2.0
Dec 13, 2022Multi-agent artificial intelligence research promises a path to develop intelligent technologies that are more human-like and more human-compatible than those produced by "solipsistic" approaches, which do not consider interactions between agents. Melting Pot is a research tool developed to facilitate work on multi-agent artificial intelligence, and provides an evaluation protocol that measures generalization to novel social partners in a set of canonical test scenarios. Each scenario pairs a physical environment (a "substrate") with a reference set of co-players (a "background population"), to create a social situation with substantial interdependence between the individuals involved. For instance, some scenarios were inspired by institutional-economics-based accounts of natural resource management and public-good-provision dilemmas. Others were inspired by considerations from evolutionary biology, game theory, and artificial life. Melting Pot aims to cover a maximally diverse set of interdependencies and incentives. It includes the commonly-studied extreme cases of perfectly-competitive (zero-sum) motivations and perfectly-cooperative (shared-reward) motivations, but does not stop with them. As in real-life, a clear majority of scenarios in Melting Pot have mixed incentives. They are neither purely competitive nor purely cooperative and thus demand successful agents be able to navigate the resulting ambiguity. Here we describe Melting Pot 2.0, which revises and expands on Melting Pot. We also introduce support for scenarios with asymmetric roles, and explain how to integrate them into the evaluation protocol. This report also contains: (1) details of all substrates and scenarios; (2) a complete description of all baseline algorithms and results. Our intention is for it to serve as a reference for researchers using Melting Pot 2.0.
Hidden Agenda: a Social Deduction Game with Diverse Learned Equilibria
Jan 05, 2022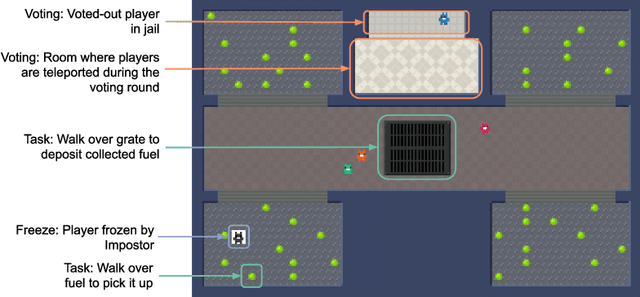

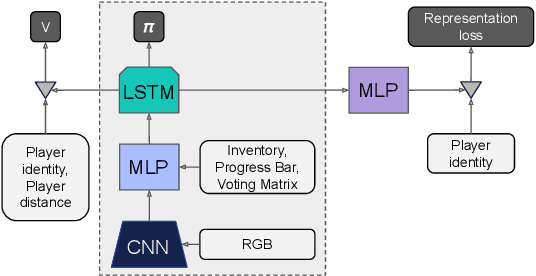
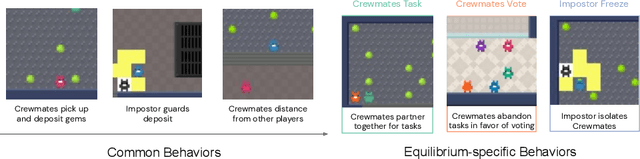
A key challenge in the study of multiagent cooperation is the need for individual agents not only to cooperate effectively, but to decide with whom to cooperate. This is particularly critical in situations when other agents have hidden, possibly misaligned motivations and goals. Social deduction games offer an avenue to study how individuals might learn to synthesize potentially unreliable information about others, and elucidate their true motivations. In this work, we present Hidden Agenda, a two-team social deduction game that provides a 2D environment for studying learning agents in scenarios of unknown team alignment. The environment admits a rich set of strategies for both teams. Reinforcement learning agents trained in Hidden Agenda show that agents can learn a variety of behaviors, including partnering and voting without need for communication in natural language.
TinyFedTL: Federated Transfer Learning on Tiny Devices
Oct 03, 2021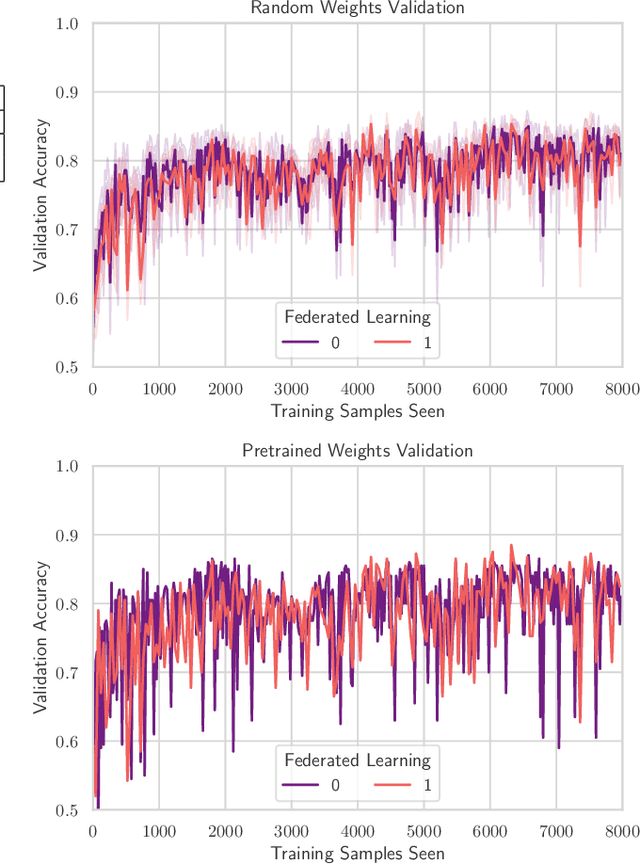
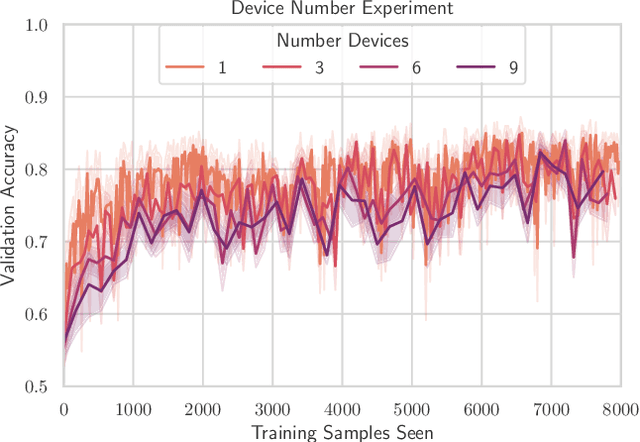
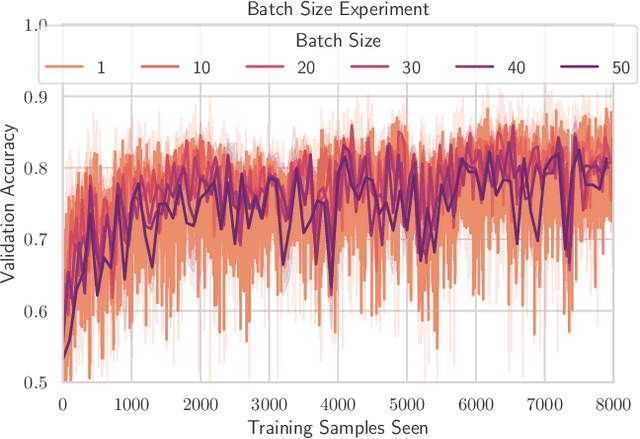
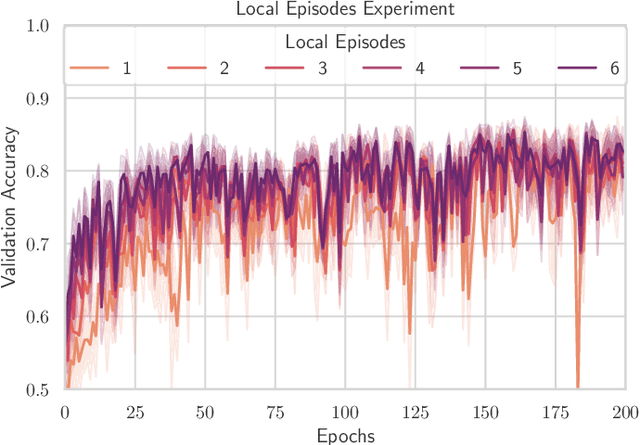
TinyML has rose to popularity in an era where data is everywhere. However, the data that is in most demand is subject to strict privacy and security guarantees. In addition, the deployment of TinyML hardware in the real world has significant memory and communication constraints that traditional ML fails to address. In light of these challenges, we present TinyFedTL, the first implementation of federated transfer learning on a resource-constrained microcontroller.
FedCD: Improving Performance in non-IID Federated Learning
Jun 22, 2020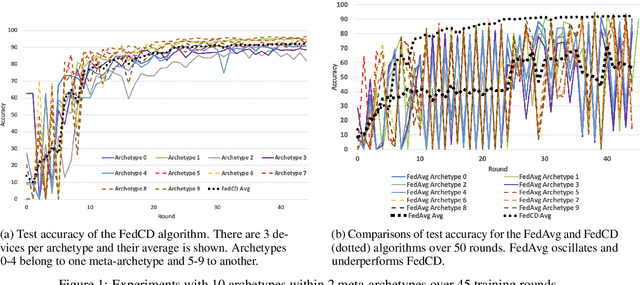
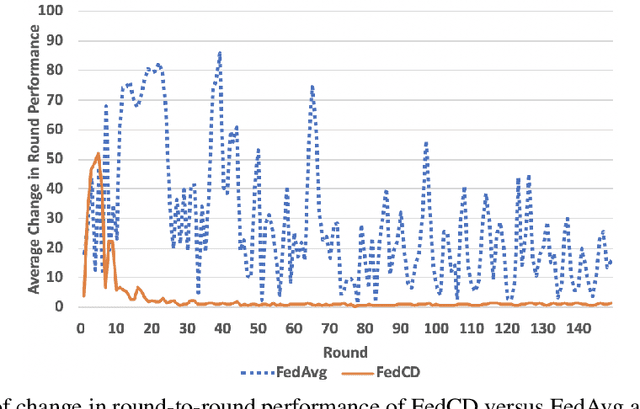
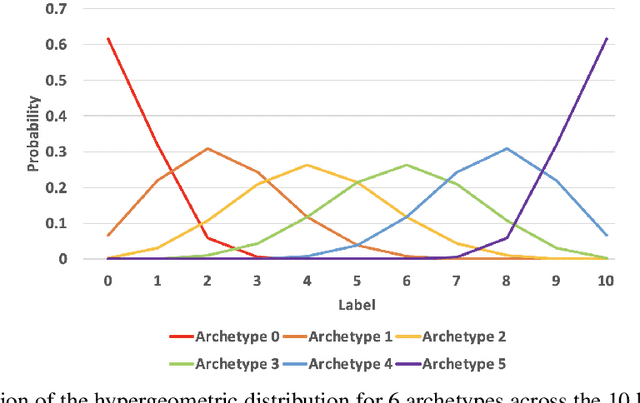
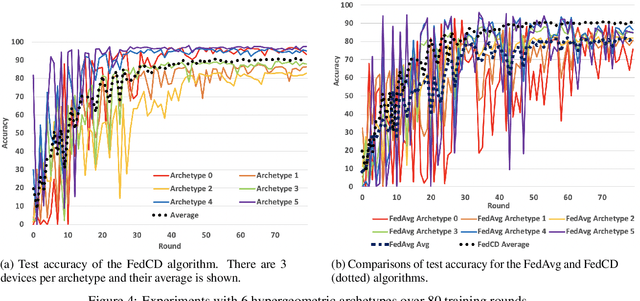
Federated learning has been widely applied to enable decentralized devices, which each have their own local data, to learn a shared model. However, learning from real-world data can be challenging, as it is rarely identically and independently distributed (IID) across edge devices (a key assumption for current high-performing and low-bandwidth algorithms). We present a novel approach, FedCD, which clones and deletes models to dynamically group devices with similar data. Experiments on the CIFAR-10 dataset show that FedCD achieves higher accuracy and faster convergence compared to a FedAvg baseline on non-IID data while incurring minimal computation, communication, and storage overheads.
FedFMC: Sequential Efficient Federated Learning on Non-iid Data
Jun 19, 2020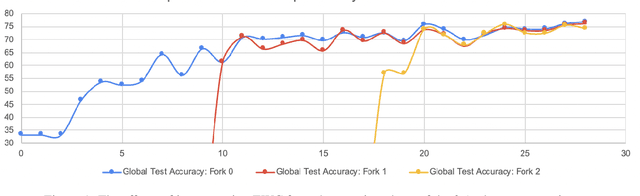
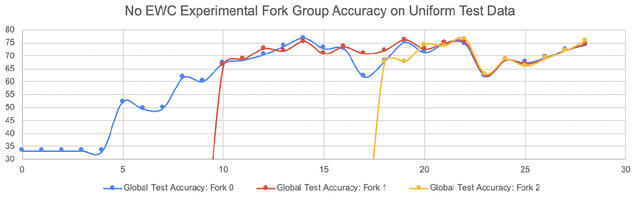
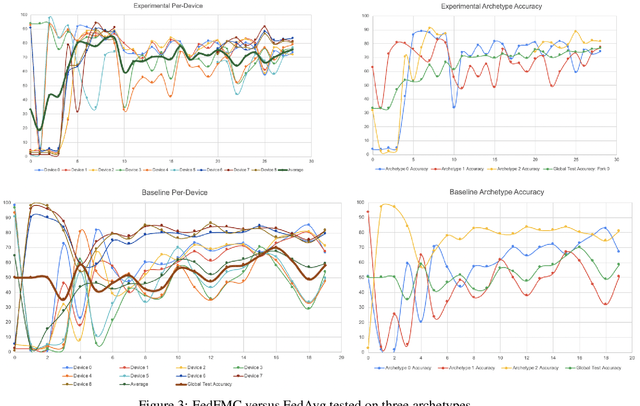
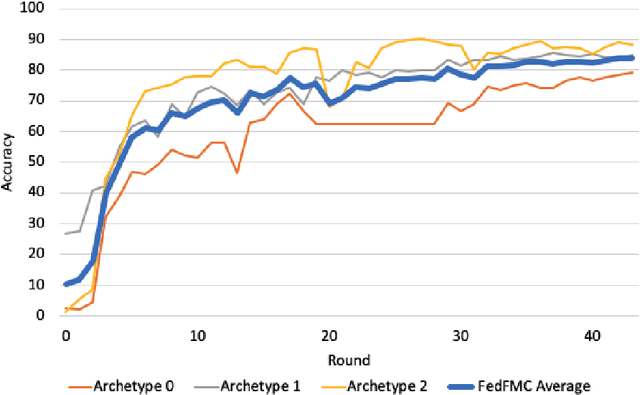
As a mechanism for devices to update a global model without sharing data, federated learning bridges the tension between the need for data and respect for privacy. However, classic FL methods like Federated Averaging struggle with non-iid data, a prevalent situation in the real world. Previous solutions are sub-optimal as they either employ a small shared global subset of data or greater number of models with increased communication costs. We propose FedFMC (Fork-Merge-Consolidate), a method that dynamically forks devices into updating different global models then merges and consolidates separate models into one. We first show the soundness of FedFMC on simple datasets, then run several experiments comparing against baseline approaches. These experiments show that FedFMC substantially improves upon earlier approaches to non-iid data in the federated learning context without using a globally shared subset of data nor increase communication costs.