 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReST meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent
Dec 15, 2023Answering complex natural language questions often necessitates multi-step reasoning and integrating external information. Several systems have combined knowledge retrieval with a large language model (LLM) to answer such questions. These systems, however, suffer from various failure cases, and we cannot directly train them end-to-end to fix such failures, as interaction with external knowledge is non-differentiable. To address these deficiencies, we define a ReAct-style LLM agent with the ability to reason and act upon external knowledge. We further refine the agent through a ReST-like method that iteratively trains on previous trajectories, employing growing-batch reinforcement learning with AI feedback for continuous self-improvement and self-distillation. Starting from a prompted large model and after just two iterations of the algorithm, we can produce a fine-tuned small model that achieves comparable performance on challenging compositional question-answering benchmarks with two orders of magnitude fewer parameters.
Large Language Models with Controllable Working Memory
Nov 09, 2022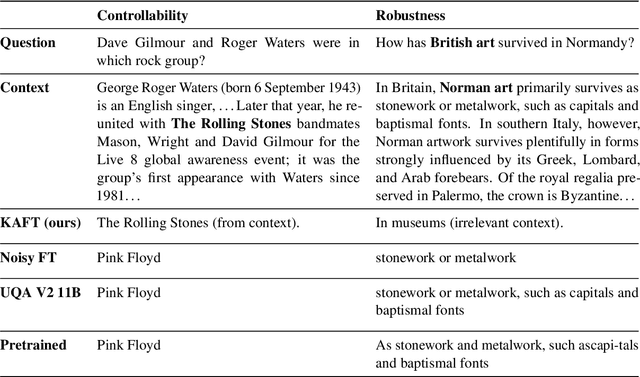
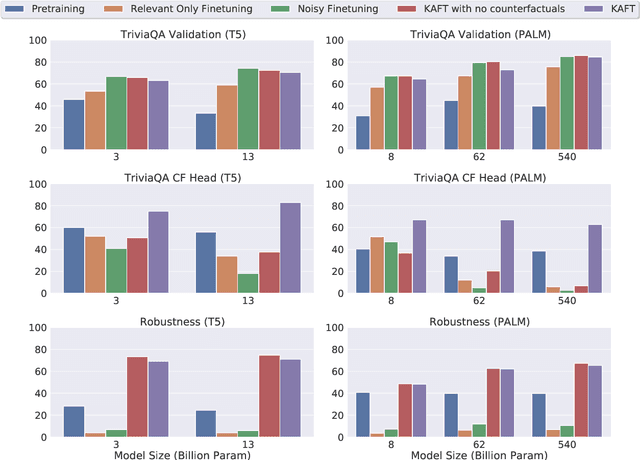

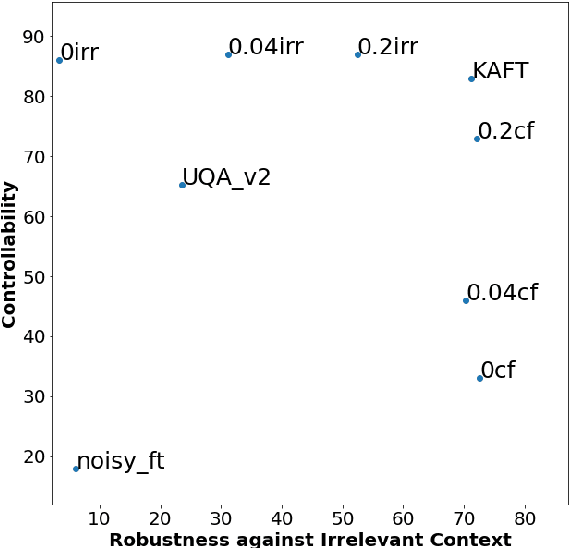
Large language models (LLMs) have led to a series of breakthroughs in natural language processing (NLP), owing to their excellent understanding and generation abilities. Remarkably, what further sets these models apart is the massive amounts of world knowledge they internalize during pretraining. While many downstream applications provide the model with an informational context to aid its performance on the underlying task, how the model's world knowledge interacts with the factual information presented in the context remains under explored. As a desirable behavior, an LLM should give precedence to the context whenever it contains task-relevant information that conflicts with the model's memorized knowledge. This enables model predictions to be grounded in the context, which can then be used to update or correct specific model predictions without frequent retraining. By contrast, when the context is irrelevant to the task, the model should ignore it and fall back on its internal knowledge. In this paper, we undertake a first joint study of the aforementioned two properties, namely controllability and robustness, in the context of LLMs. We demonstrate that state-of-the-art T5 and PaLM (both pretrained and finetuned) could exhibit poor controllability and robustness, which do not scale with increasing model size. As a solution, we propose a novel method - Knowledge Aware FineTuning (KAFT) - to strengthen both controllability and robustness by incorporating counterfactual and irrelevant contexts to standard supervised datasets. Our comprehensive evaluation showcases the utility of KAFT across model architectures and sizes.
Preserving In-Context Learning ability in Large Language Model Fine-tuning
Nov 01, 2022Pretrained large language models (LLMs) are strong in-context learners that are able to perform few-shot learning without changing model parameters. However, as we show, fine-tuning an LLM on any specific task generally destroys its in-context ability. We discover an important cause of this loss, format specialization, where the model overfits to the format of the fine-tuned task and is unable to output anything beyond this format. We further show that format specialization happens at the beginning of fine-tuning. To solve this problem, we propose Prompt Tuning with MOdel Tuning (ProMoT), a simple yet effective two-stage fine-tuning framework that preserves in-context abilities of the pretrained model. ProMoT first trains a soft prompt for the fine-tuning target task, and then fine-tunes the model itself with this soft prompt attached. ProMoT offloads task-specific formats into the soft prompt that can be removed when doing other in-context tasks. We fine-tune mT5 XXL with ProMoT on natural language inference (NLI) and English-French translation and evaluate the in-context abilities of the resulting models on 8 different NLP tasks. ProMoT achieves similar performance on the fine-tuned tasks compared with vanilla fine-tuning, but with much less reduction of in-context learning performances across the board. More importantly, ProMoT shows remarkable generalization ability on tasks that have different formats, e.g. fine-tuning on a NLI binary classification task improves the model's in-context ability to do summarization (+0.53 Rouge-2 score compared to the pretrained model), making ProMoT a promising method to build general purpose capabilities such as grounding and reasoning into LLMs with small but high quality datasets. When extended to sequential or multi-task training, ProMoT can achieve even better out-of-domain generalization performance.
Large Models are Parsimonious Learners: Activation Sparsity in Trained Transformers
Oct 12, 2022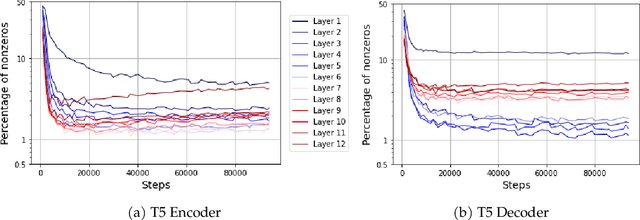

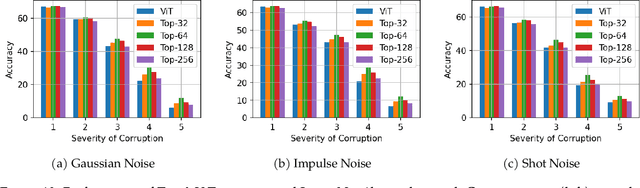
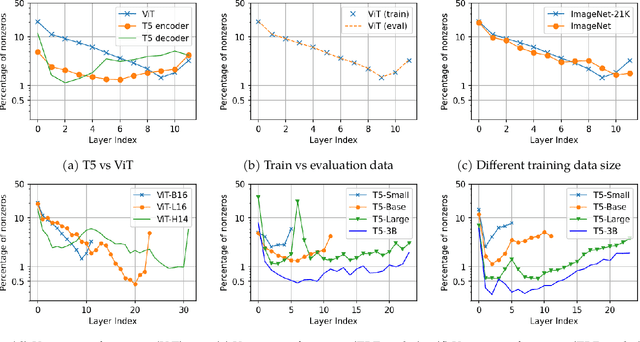
This paper studies the curious phenomenon for machine learning models with Transformer architectures that their activation maps are sparse. By activation map we refer to the intermediate output of the multi-layer perceptrons (MLPs) after a ReLU activation function, and by "sparse" we mean that on average very few entries (e.g., 3.0% for T5-Base and 6.3% for ViT-B16) are nonzero for each input to MLP. Moreover, larger Transformers with more layers and wider MLP hidden dimensions are sparser as measured by the percentage of nonzero entries. Through extensive experiments we demonstrate that the emergence of sparsity is a prevalent phenomenon that occurs for both natural language processing and vision tasks, on both training and evaluation data, for Transformers of various configurations, at layers of all depth levels, as well as for other architectures including MLP-mixers and 2-layer MLPs. We show that sparsity also emerges using training datasets with random labels, or with random inputs, or with infinite amount of data, demonstrating that sparsity is not a result of a specific family of datasets. We discuss how sparsity immediately implies a way to significantly reduce the FLOP count and improve efficiency for Transformers. Moreover, we demonstrate perhaps surprisingly that enforcing an even sparser activation via Top-k thresholding with a small value of k brings a collection of desired but missing properties for Transformers, namely less sensitivity to noisy training data, more robustness to input corruptions, and better calibration for their prediction confidence.
Understanding Robustness of Transformers for Image Classification
Mar 26, 2021
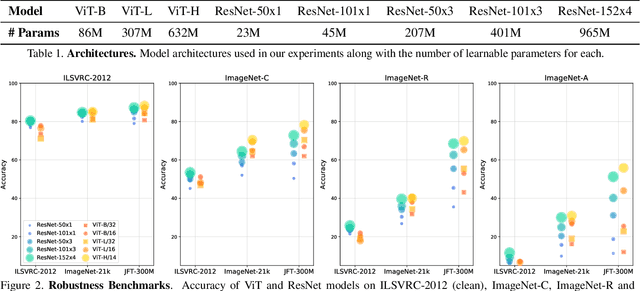
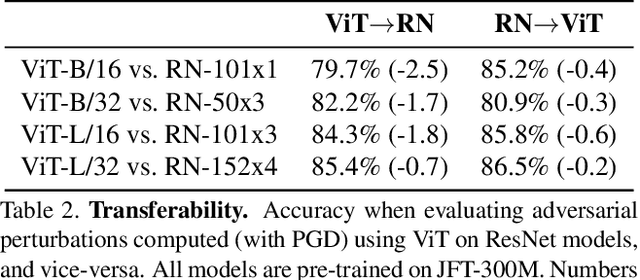
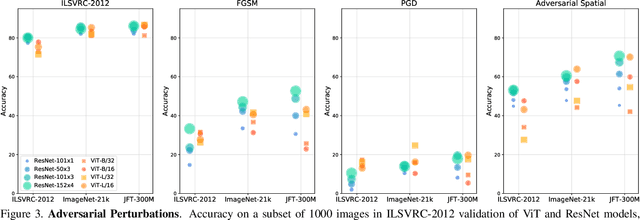
Deep Convolutional Neural Networks (CNNs) have long been the architecture of choice for computer vision tasks. Recently, Transformer-based architectures like Vision Transformer (ViT) have matched or even surpassed ResNets for image classification. However, details of the Transformer architecture -- such as the use of non-overlapping patches -- lead one to wonder whether these networks are as robust. In this paper, we perform an extensive study of a variety of different measures of robustness of ViT models and compare the findings to ResNet baselines. We investigate robustness to input perturbations as well as robustness to model perturbations. We find that when pre-trained with a sufficient amount of data, ViT models are at least as robust as the ResNet counterparts on a broad range of perturbations. We also find that Transformers are robust to the removal of almost any single layer, and that while activations from later layers are highly correlated with each other, they nevertheless play an important role in classification.
Modifying Memories in Transformer Models
Dec 01, 2020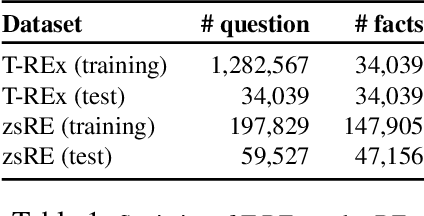

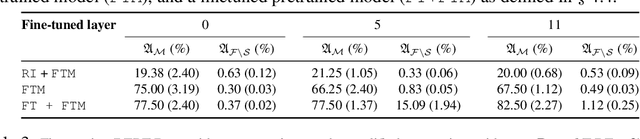
Large Transformer models have achieved impressive performance in many natural language tasks. In particular, Transformer based language models have been shown to have great capabilities in encoding factual knowledge in their vast amount of parameters. While the tasks of improving the memorization and generalization of Transformers have been widely studied, it is not well known how to make transformers forget specific old facts and memorize new ones. In this paper, we propose a new task of \emph{explicitly modifying specific factual knowledge in Transformer models while ensuring the model performance does not degrade on the unmodified facts}. This task is useful in many scenarios, such as updating stale knowledge, protecting privacy, and eliminating unintended biases stored in the models. We benchmarked several approaches that provide natural baseline performances on this task. This leads to the discovery of key components of a Transformer model that are especially effective for knowledge modifications. The work also provides insights into the role that different training phases (such as pretraining and fine-tuning) play towards memorization and knowledge modification.
FedMD: Heterogenous Federated Learning via Model Distillation
Oct 08, 2019
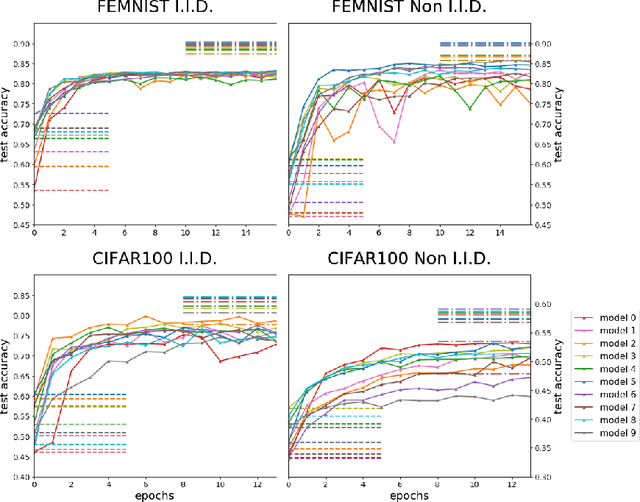
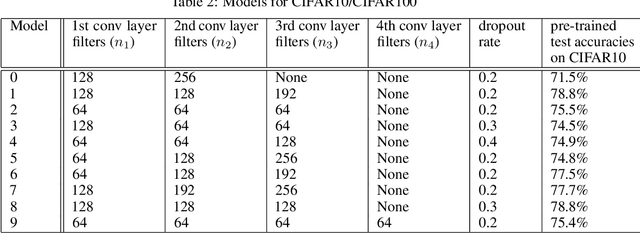
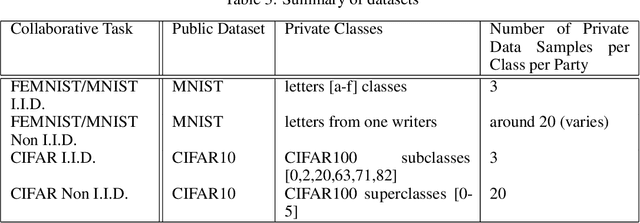
Federated learning enables the creation of a powerful centralized model without compromising data privacy of multiple participants. While successful, it does not incorporate the case where each participant independently designs its own model. Due to intellectual property concerns and heterogeneous nature of tasks and data, this is a widespread requirement in applications of federated learning to areas such as health care and AI as a service. In this work, we use transfer learning and knowledge distillation to develop a universal framework that enables federated learning when each agent owns not only their private data, but also uniquely designed models. We test our framework on the MNIST/FEMNIST dataset and the CIFAR10/CIFAR100 dataset and observe fast improvement across all participating models. With 10 distinct participants, the final test accuracy of each model on average receives a 20% gain on top of what's possible without collaboration and is only a few percent lower than the performance each model would have obtained if all private datasets were pooled and made directly available for all participants.