 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort-Context Dominance: How Much Local Context Natural Language Actually Needs?
Dec 08, 2025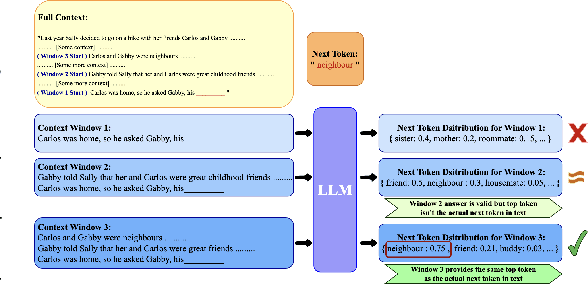
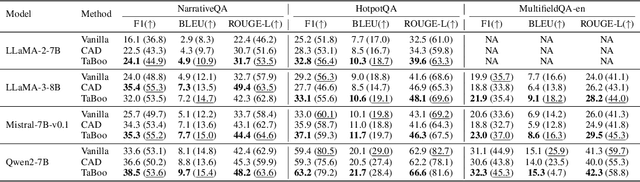
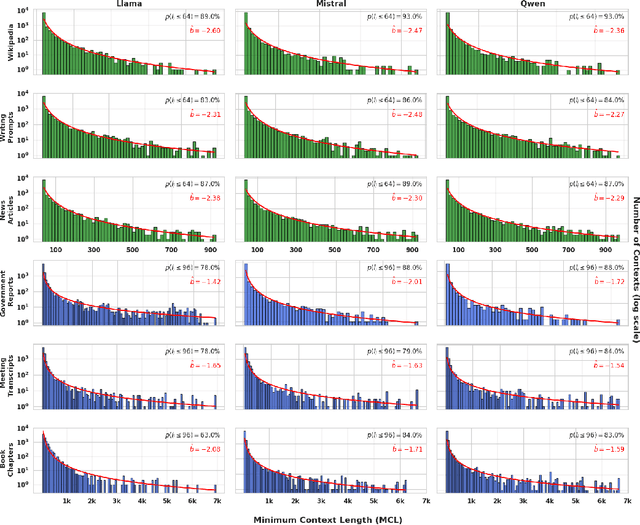

We investigate the short-context dominance hypothesis: that for most sequences, a small local prefix suffices to predict their next tokens. Using large language models as statistical oracles, we measure the minimum context length (MCL) needed to reproduce accurate full-context predictions across datasets with sequences of varying lengths. For sequences with 1-7k tokens from long-context documents, we consistently find that 75-80% require only the last 96 tokens at most. Given the dominance of short-context tokens, we then ask whether it is possible to detect challenging long-context sequences for which a short local prefix does not suffice for prediction. We introduce a practical proxy to MCL, called Distributionally Aware MCL (DaMCL), that does not require knowledge of the actual next-token and is compatible with sampling strategies beyond greedy decoding. Our experiments validate that simple thresholding of the metric defining DaMCL achieves high performance in detecting long vs. short context sequences. Finally, to counter the bias that short-context dominance induces in LLM output distributions, we develop an intuitive decoding algorithm that leverages our detector to identify and boost tokens that are long-range-relevant. Across Q&A tasks and model architectures, we confirm that mitigating the bias improves performance.
Continuous Chain of Thought Enables Parallel Exploration and Reasoning
May 29, 2025Current language models generate chain-of-thought traces by autoregressively sampling tokens from a finite vocabulary. While this discrete sampling has achieved remarkable success, conducting chain-of-thought with continuously-valued tokens (CoT2) offers a richer and more expressive alternative. Our work examines the benefits of CoT2 through logical reasoning tasks that inherently require search capabilities and provide optimization and exploration methods for CoT2. Theoretically, we show that CoT2 allows the model to track multiple traces in parallel and quantify its benefits for inference efficiency. Notably, one layer transformer equipped with CoT2 can provably solve the combinatorial "subset sum problem" given sufficient embedding dimension. These insights lead to a novel and effective supervision strategy where we match the softmax outputs to the empirical token distributions of a set of target traces. Complementing this, we introduce sampling strategies that unlock policy optimization and self-improvement for CoT2. Our first strategy samples and composes $K$ discrete tokens at each decoding step to control the level of parallelism, and reduces to standard CoT when $K=1$. Our second strategy relies on continuous exploration over the probability simplex. Experiments confirm that policy optimization with CoT2 indeed improves the performance of the model beyond its initial discrete or continuous supervision.
Gating is Weighting: Understanding Gated Linear Attention through In-context Learning
Apr 06, 2025Linear attention methods offer a compelling alternative to softmax attention due to their efficiency in recurrent decoding. Recent research has focused on enhancing standard linear attention by incorporating gating while retaining its computational benefits. Such Gated Linear Attention (GLA) architectures include competitive models such as Mamba and RWKV. In this work, we investigate the in-context learning capabilities of the GLA model and make the following contributions. We show that a multilayer GLA can implement a general class of Weighted Preconditioned Gradient Descent (WPGD) algorithms with data-dependent weights. These weights are induced by the gating mechanism and the input, enabling the model to control the contribution of individual tokens to prediction. To further understand the mechanics of this weighting, we introduce a novel data model with multitask prompts and characterize the optimization landscape of learning a WPGD algorithm. Under mild conditions, we establish the existence and uniqueness (up to scaling) of a global minimum, corresponding to a unique WPGD solution. Finally, we translate these findings to explore the optimization landscape of GLA and shed light on how gating facilitates context-aware learning and when it is provably better than vanilla linear attention.
Universal Model Routing for Efficient LLM Inference
Feb 12, 2025



Large language models' significant advances in capabilities are accompanied by significant increases in inference costs. Model routing is a simple technique for reducing inference cost, wherein one maintains a pool of candidate LLMs, and learns to route each prompt to the smallest feasible LLM. Existing works focus on learning a router for a fixed pool of LLMs. In this paper, we consider the problem of dynamic routing, where new, previously unobserved LLMs are available at test time. We propose a new approach to this problem that relies on representing each LLM as a feature vector, derived based on predictions on a set of representative prompts. Based on this, we detail two effective strategies, relying on cluster-based routing and a learned cluster map respectively. We prove that these strategies are estimates of a theoretically optimal routing rule, and provide an excess risk bound to quantify their errors. Experiments on a range of public benchmarks show the effectiveness of the proposed strategies in routing amongst more than 30 unseen LLMs.
A Little Help Goes a Long Way: Efficient LLM Training by Leveraging Small LMs
Oct 24, 2024
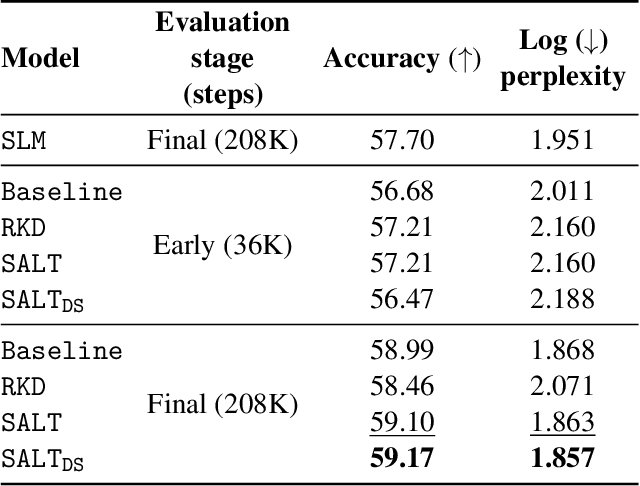

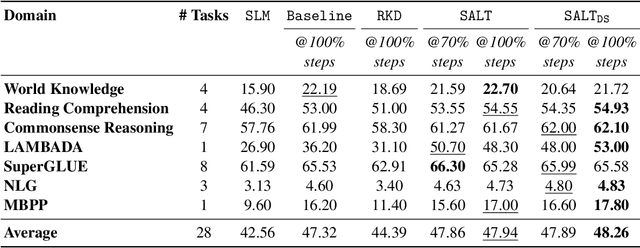
A primary challenge in large language model (LLM) development is their onerous pre-training cost. Typically, such pre-training involves optimizing a self-supervised objective (such as next-token prediction) over a large corpus. This paper explores a promising paradigm to improve LLM pre-training efficiency and quality by suitably leveraging a small language model (SLM). In particular, this paradigm relies on an SLM to both (1) provide soft labels as additional training supervision, and (2) select a small subset of valuable ("informative" and "hard") training examples. Put together, this enables an effective transfer of the SLM's predictive distribution to the LLM, while prioritizing specific regions of the training data distribution. Empirically, this leads to reduced LLM training time compared to standard training, while improving the overall quality. Theoretically, we develop a statistical framework to systematically study the utility of SLMs in enabling efficient training of high-quality LLMs. In particular, our framework characterizes how the SLM's seemingly low-quality supervision can enhance the training of a much more capable LLM. Furthermore, it also highlights the need for an adaptive utilization of such supervision, by striking a balance between the bias and variance introduced by the SLM-provided soft labels. We corroborate our theoretical framework by improving the pre-training of an LLM with 2.8B parameters by utilizing a smaller LM with 1.5B parameters on the Pile dataset.
A Statistical Framework for Data-dependent Retrieval-Augmented Models
Aug 27, 2024Modern ML systems increasingly augment input instances with additional relevant information to enhance final prediction. Despite growing interest in such retrieval-augmented models, their fundamental properties and training are not well understood. We propose a statistical framework to study such models with two components: 1) a {\em retriever} to identify the relevant information out of a large corpus via a data-dependent metric; and 2) a {\em predictor} that consumes the input instances along with the retrieved information to make the final predictions. We present a principled method for end-to-end training of both components and draw connections with various training approaches in the literature. Furthermore, we establish excess risk bounds for retrieval-augmented models while delineating the contributions of both retriever and predictor towards the model performance. We validate the utility of our proposed training methods along with the key takeaways from our statistical analysis on open domain question answering task where retrieval augmentation is important.
Analysis of Plan-based Retrieval for Grounded Text Generation
Aug 20, 2024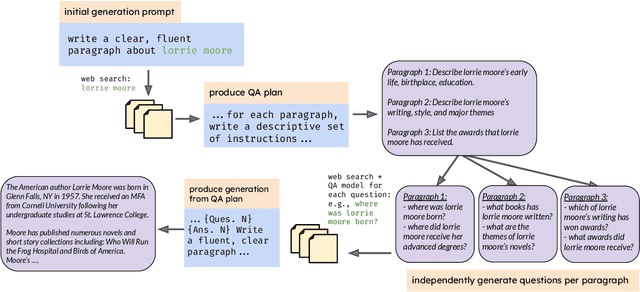
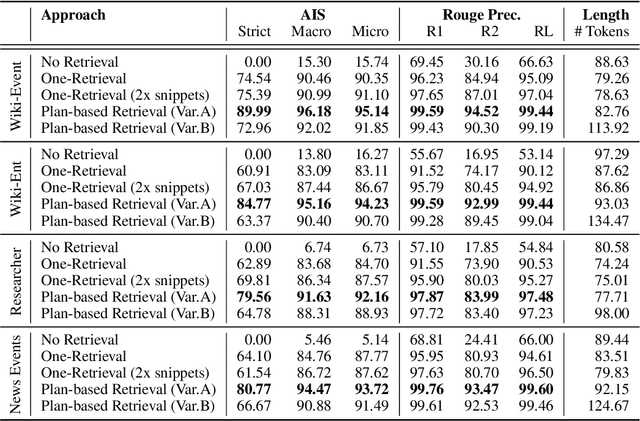

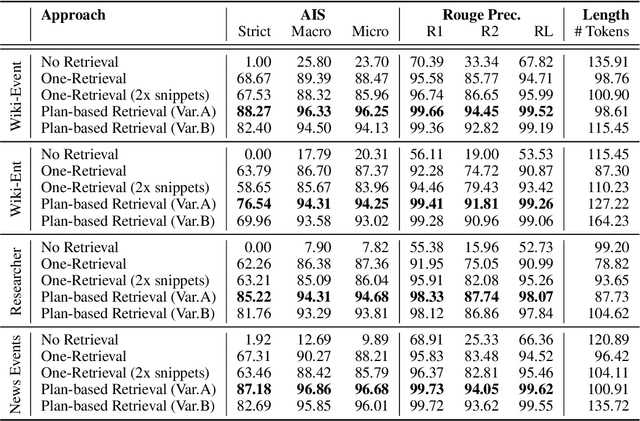
In text generation, hallucinations refer to the generation of seemingly coherent text that contradicts established knowledge. One compelling hypothesis is that hallucinations occur when a language model is given a generation task outside its parametric knowledge (due to rarity, recency, domain, etc.). A common strategy to address this limitation is to infuse the language models with retrieval mechanisms, providing the model with relevant knowledge for the task. In this paper, we leverage the planning capabilities of instruction-tuned LLMs and analyze how planning can be used to guide retrieval to further reduce the frequency of hallucinations. We empirically evaluate several variations of our proposed approach on long-form text generation tasks. By improving the coverage of relevant facts, plan-guided retrieval and generation can produce more informative responses while providing a higher rate of attribution to source documents.
Fine-grained Analysis of In-context Linear Estimation: Data, Architecture, and Beyond
Jul 13, 2024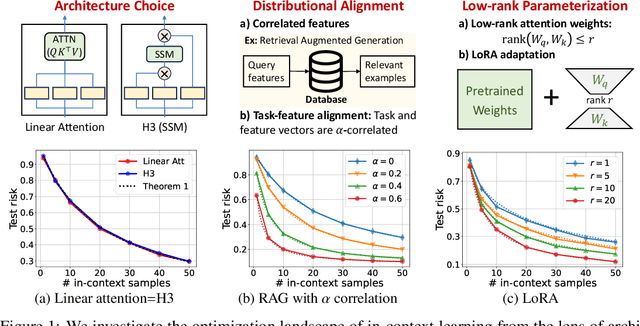
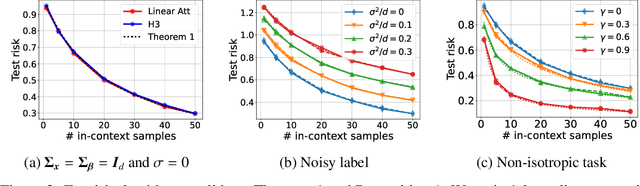
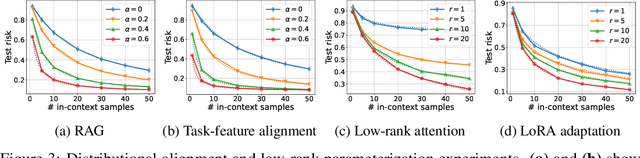
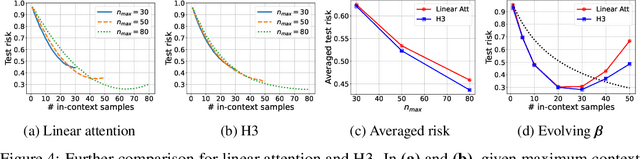
Recent research has shown that Transformers with linear attention are capable of in-context learning (ICL) by implementing a linear estimator through gradient descent steps. However, the existing results on the optimization landscape apply under stylized settings where task and feature vectors are assumed to be IID and the attention weights are fully parameterized. In this work, we develop a stronger characterization of the optimization and generalization landscape of ICL through contributions on architectures, low-rank parameterization, and correlated designs: (1) We study the landscape of 1-layer linear attention and 1-layer H3, a state-space model. Under a suitable correlated design assumption, we prove that both implement 1-step preconditioned gradient descent. We show that thanks to its native convolution filters, H3 also has the advantage of implementing sample weighting and outperforming linear attention in suitable settings. (2) By studying correlated designs, we provide new risk bounds for retrieval augmented generation (RAG) and task-feature alignment which reveal how ICL sample complexity benefits from distributional alignment. (3) We derive the optimal risk for low-rank parameterized attention weights in terms of covariance spectrum. Through this, we also shed light on how LoRA can adapt to a new distribution by capturing the shift between task covariances. Experimental results corroborate our theoretical findings. Overall, this work explores the optimization and risk landscape of ICL in practically meaningful settings and contributes to a more thorough understanding of its mechanics.
Efficient Document Ranking with Learnable Late Interactions
Jun 25, 2024



Cross-Encoder (CE) and Dual-Encoder (DE) models are two fundamental approaches for query-document relevance in information retrieval. To predict relevance, CE models use joint query-document embeddings, while DE models maintain factorized query and document embeddings; usually, the former has higher quality while the latter benefits from lower latency. Recently, late-interaction models have been proposed to realize more favorable latency-quality tradeoffs, by using a DE structure followed by a lightweight scorer based on query and document token embeddings. However, these lightweight scorers are often hand-crafted, and there is no understanding of their approximation power; further, such scorers require access to individual document token embeddings, which imposes an increased latency and storage burden. In this paper, we propose novel learnable late-interaction models (LITE) that resolve these issues. Theoretically, we prove that LITE is a universal approximator of continuous scoring functions, even for relatively small embedding dimension. Empirically, LITE outperforms previous late-interaction models such as ColBERT on both in-domain and zero-shot re-ranking tasks. For instance, experiments on MS MARCO passage re-ranking show that LITE not only yields a model with better generalization, but also lowers latency and requires 0.25x storage compared to ColBERT.
Cascade-Aware Training of Language Models
May 29, 2024



Reducing serving cost and latency is a fundamental concern for the deployment of language models (LMs) in business applications. To address this, cascades of LMs offer an effective solution that conditionally employ smaller models for simpler queries. Cascaded systems are typically built with independently trained models, neglecting the advantages of considering inference-time interactions of the cascaded LMs during training. In this paper, we present cascade-aware training(CAT), an approach to optimizing the overall quality-cost performance tradeoff of a cascade of LMs. We achieve inference-time benefits by training the small LM with awareness of its place in a cascade and downstream capabilities. We demonstrate the value of the proposed method with over 60 LM tasks of the SuperGLUE, WMT22, and FLAN2021 datasets.