 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Little Help Goes a Long Way: Efficient LLM Training by Leveraging Small LMs
Oct 24, 2024
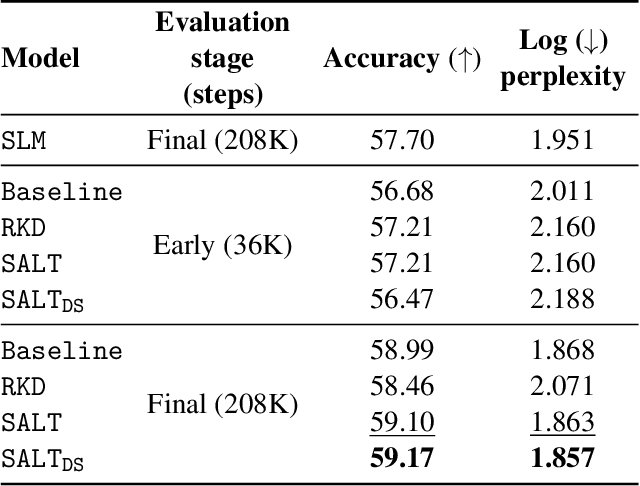

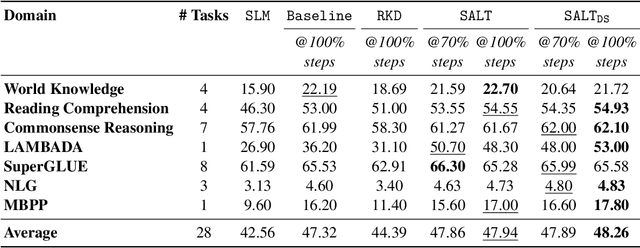
A primary challenge in large language model (LLM) development is their onerous pre-training cost. Typically, such pre-training involves optimizing a self-supervised objective (such as next-token prediction) over a large corpus. This paper explores a promising paradigm to improve LLM pre-training efficiency and quality by suitably leveraging a small language model (SLM). In particular, this paradigm relies on an SLM to both (1) provide soft labels as additional training supervision, and (2) select a small subset of valuable ("informative" and "hard") training examples. Put together, this enables an effective transfer of the SLM's predictive distribution to the LLM, while prioritizing specific regions of the training data distribution. Empirically, this leads to reduced LLM training time compared to standard training, while improving the overall quality. Theoretically, we develop a statistical framework to systematically study the utility of SLMs in enabling efficient training of high-quality LLMs. In particular, our framework characterizes how the SLM's seemingly low-quality supervision can enhance the training of a much more capable LLM. Furthermore, it also highlights the need for an adaptive utilization of such supervision, by striking a balance between the bias and variance introduced by the SLM-provided soft labels. We corroborate our theoretical framework by improving the pre-training of an LLM with 2.8B parameters by utilizing a smaller LM with 1.5B parameters on the Pile dataset.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Sketchy: Memory-efficient Adaptive Regularization with Frequent Directions
Feb 07, 2023Adaptive regularization methods that exploit more than the diagonal entries exhibit state of the art performance for many tasks, but can be prohibitive in terms of memory and running time. We find the spectra of the Kronecker-factored gradient covariance matrix in deep learning (DL) training tasks are concentrated on a small leading eigenspace that changes throughout training, motivating a low-rank sketching approach. We describe a generic method for reducing memory and compute requirements of maintaining a matrix preconditioner using the Frequent Directions (FD) sketch. Our technique allows interpolation between resource requirements and the degradation in regret guarantees with rank $k$: in the online convex optimization (OCO) setting over dimension $d$, we match full-matrix $d^2$ memory regret using only $dk$ memory up to additive error in the bottom $d-k$ eigenvalues of the gradient covariance. Further, we show extensions of our work to Shampoo, placing the method on the memory-quality Pareto frontier of several large scale benchmarks.
Chromatic Learning for Sparse Datasets
Jun 06, 2020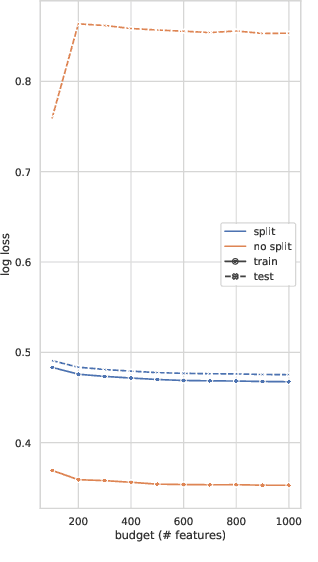


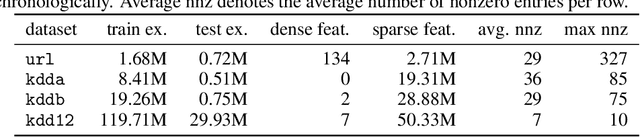
Learning over sparse, high-dimensional data frequently necessitates the use of specialized methods such as the hashing trick. In this work, we design a highly scalable alternative approach that leverages the low degree of feature co-occurrences present in many practical settings. This approach, which we call Chromatic Learning (CL), obtains a low-dimensional dense feature representation by performing graph coloring over the co-occurrence graph of features---an approach previously used as a runtime performance optimization for GBDT training. This color-based dense representation can be combined with additional dense categorical encoding approaches, e.g., submodular feature compression, to further reduce dimensionality. CL exhibits linear parallelizability and consumes memory linear in the size of the co-occurrence graph. By leveraging the structural properties of the co-occurrence graph, CL can compress sparse datasets, such as KDD Cup 2012, that contain over 50M features down to 1024, using an order of magnitude fewer features than frequency-based truncation and the hashing trick while maintaining the same test error for linear models. This compression further enables the use of deep networks in this wide, sparse setting, where CL similarly has favorable performance compared to existing baselines for budgeted input dimension.
On the Computational Inefficiency of Large Batch Sizes for Stochastic Gradient Descent
Nov 30, 2018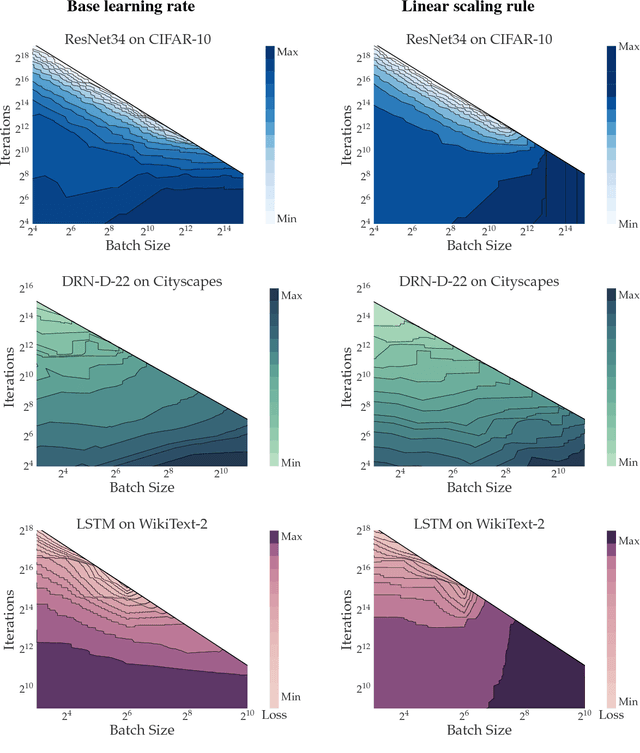
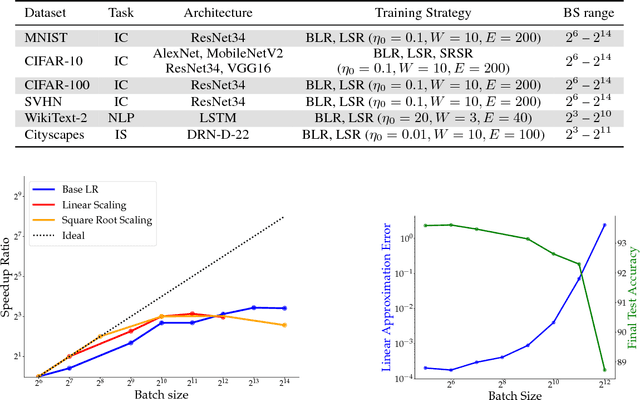
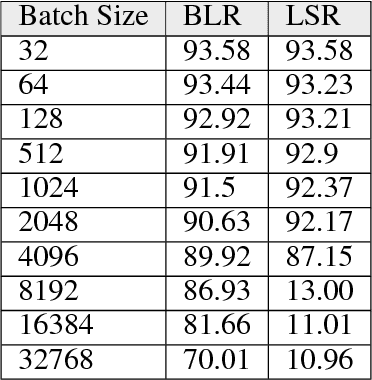

Increasing the mini-batch size for stochastic gradient descent offers significant opportunities to reduce wall-clock training time, but there are a variety of theoretical and systems challenges that impede the widespread success of this technique. We investigate these issues, with an emphasis on time to convergence and total computational cost, through an extensive empirical analysis of network training across several architectures and problem domains, including image classification, image segmentation, and language modeling. Although it is common practice to increase the batch size in order to fully exploit available computational resources, we find a substantially more nuanced picture. Our main finding is that across a wide range of network architectures and problem domains, increasing the batch size beyond a certain point yields no decrease in wall-clock time to convergence for \emph{either} train or test loss. This batch size is usually substantially below the capacity of current systems. We show that popular training strategies for large batch size optimization begin to fail before we can populate all available compute resources, and we show that the point at which these methods break down depends more on attributes like model architecture and data complexity than it does directly on the size of the dataset.
Model-Based Value Estimation for Efficient Model-Free Reinforcement Learning
Feb 28, 2018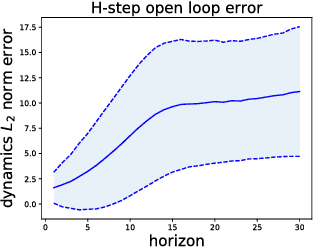


Recent model-free reinforcement learning algorithms have proposed incorporating learned dynamics models as a source of additional data with the intention of reducing sample complexity. Such methods hold the promise of incorporating imagined data coupled with a notion of model uncertainty to accelerate the learning of continuous control tasks. Unfortunately, they rely on heuristics that limit usage of the dynamics model. We present model-based value expansion, which controls for uncertainty in the model by only allowing imagination to fixed depth. By enabling wider use of learned dynamics models within a model-free reinforcement learning algorithm, we improve value estimation, which, in turn, reduces the sample complexity of learning.
Large Linear Multi-output Gaussian Process Learning
Oct 23, 2017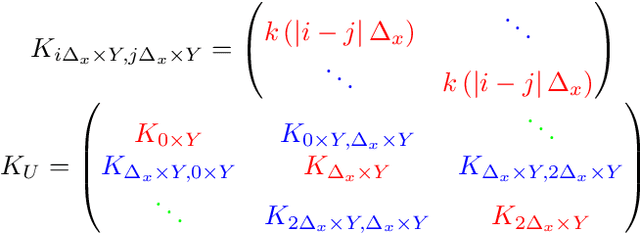

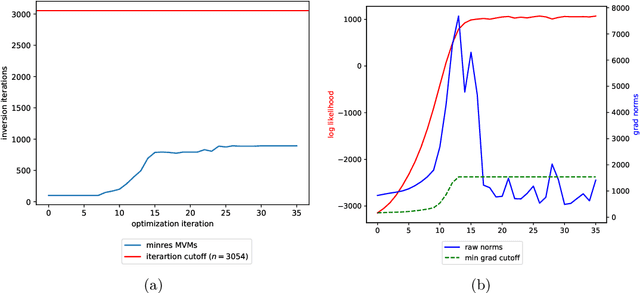
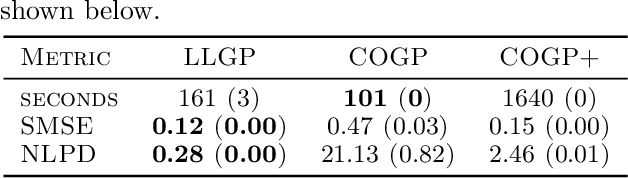
Gaussian processes (GPs), or distributions over arbitrary functions in a continuous domain, can be generalized to the multi-output case: a linear model of coregionalization (LMC) is one approach. LMCs estimate and exploit correlations across the multiple outputs. While model estimation can be performed efficiently for single-output GPs, these assume stationarity, but in the multi-output case the cross-covariance interaction is not stationary. We propose Large Linear GP (LLGP), which circumvents the need for stationarity by inducing structure in the LMC kernel through a common grid of inputs shared between outputs, enabling optimization of GP hyperparameters for multi-dimensional outputs and low-dimensional inputs. When applied to synthetic two-dimensional and real time series data, we find our theoretical improvement relative to the current solutions for multi-output GPs is realized with LLGP reducing training time while improving or maintaining predictive mean accuracy. Moreover, by using a direct likelihood approximation rather than a variational one, model confidence estimates are significantly improved.