 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Little Help Goes a Long Way: Efficient LLM Training by Leveraging Small LMs
Oct 24, 2024
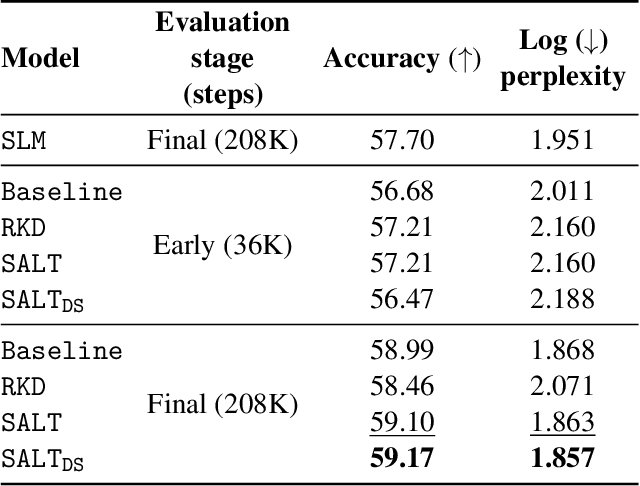

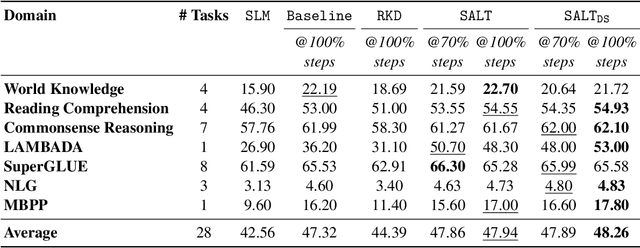
A primary challenge in large language model (LLM) development is their onerous pre-training cost. Typically, such pre-training involves optimizing a self-supervised objective (such as next-token prediction) over a large corpus. This paper explores a promising paradigm to improve LLM pre-training efficiency and quality by suitably leveraging a small language model (SLM). In particular, this paradigm relies on an SLM to both (1) provide soft labels as additional training supervision, and (2) select a small subset of valuable ("informative" and "hard") training examples. Put together, this enables an effective transfer of the SLM's predictive distribution to the LLM, while prioritizing specific regions of the training data distribution. Empirically, this leads to reduced LLM training time compared to standard training, while improving the overall quality. Theoretically, we develop a statistical framework to systematically study the utility of SLMs in enabling efficient training of high-quality LLMs. In particular, our framework characterizes how the SLM's seemingly low-quality supervision can enhance the training of a much more capable LLM. Furthermore, it also highlights the need for an adaptive utilization of such supervision, by striking a balance between the bias and variance introduced by the SLM-provided soft labels. We corroborate our theoretical framework by improving the pre-training of an LLM with 2.8B parameters by utilizing a smaller LM with 1.5B parameters on the Pile dataset.
EmbedDistill: A Geometric Knowledge Distillation for Information Retrieval
Jan 27, 2023



Large neural models (such as Transformers) achieve state-of-the-art performance for information retrieval (IR). In this paper, we aim to improve distillation methods that pave the way for the deployment of such models in practice. The proposed distillation approach supports both retrieval and re-ranking stages and crucially leverages the relative geometry among queries and documents learned by the large teacher model. It goes beyond existing distillation methods in the IR literature, which simply rely on the teacher's scalar scores over the training data, on two fronts: providing stronger signals about local geometry via embedding matching and attaining better coverage of data manifold globally via query generation. Embedding matching provides a stronger signal to align the representations of the teacher and student models. At the same time, query generation explores the data manifold to reduce the discrepancies between the student and teacher where training data is sparse. Our distillation approach is theoretically justified and applies to both dual encoder (DE) and cross-encoder (CE) models. Furthermore, for distilling a CE model to a DE model via embedding matching, we propose a novel dual pooling-based scorer for the CE model that facilitates a distillation-friendly embedding geometry, especially for DE student models.
Multivariate Trend Filtering for Lattice Data
Dec 29, 2021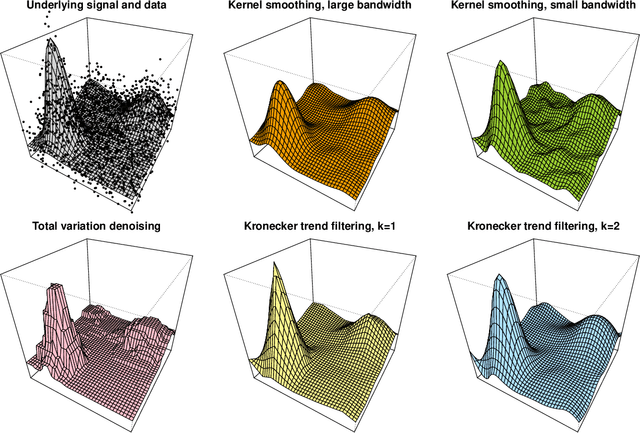
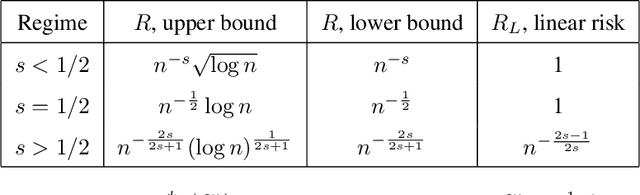
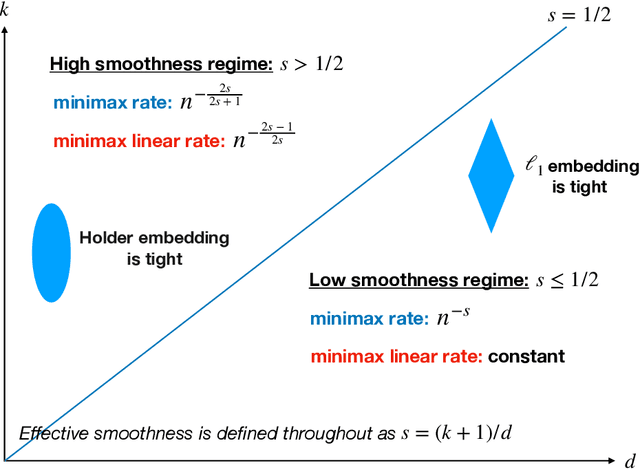
We study a multivariate version of trend filtering, called Kronecker trend filtering or KTF, for the case in which the design points form a lattice in $d$ dimensions. KTF is a natural extension of univariate trend filtering (Steidl et al., 2006; Kim et al., 2009; Tibshirani, 2014), and is defined by minimizing a penalized least squares problem whose penalty term sums the absolute (higher-order) differences of the parameter to be estimated along each of the coordinate directions. The corresponding penalty operator can be written in terms of Kronecker products of univariate trend filtering penalty operators, hence the name Kronecker trend filtering. Equivalently, one can view KTF in terms of an $\ell_1$-penalized basis regression problem where the basis functions are tensor products of falling factorial functions, a piecewise polynomial (discrete spline) basis that underlies univariate trend filtering. This paper is a unification and extension of the results in Sadhanala et al. (2016, 2017). We develop a complete set of theoretical results that describe the behavior of $k^{\mathrm{th}}$ order Kronecker trend filtering in $d$ dimensions, for every $k \geq 0$ and $d \geq 1$. This reveals a number of interesting phenomena, including the dominance of KTF over linear smoothers in estimating heterogeneously smooth functions, and a phase transition at $d=2(k+1)$, a boundary past which (on the high dimension-to-smoothness side) linear smoothers fail to be consistent entirely. We also leverage recent results on discrete splines from Tibshirani (2020), in particular, discrete spline interpolation results that enable us to extend the KTF estimate to any off-lattice location in constant-time (independent of the size of the lattice $n$).
A Higher-Order Kolmogorov-Smirnov Test
Mar 24, 2019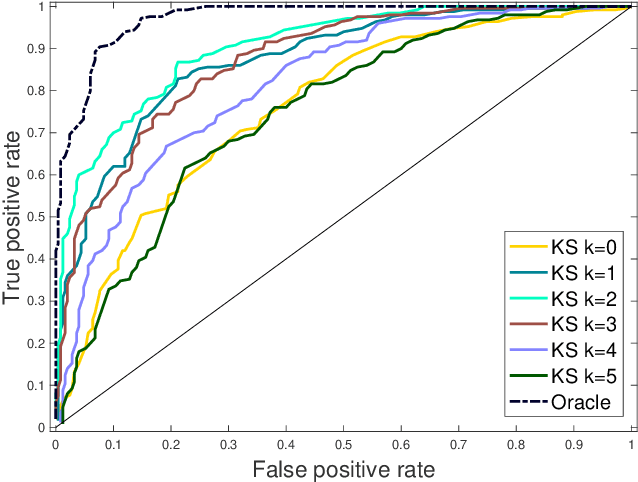
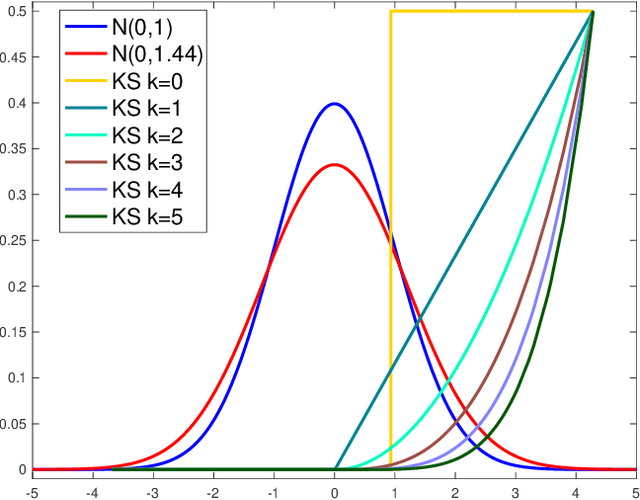
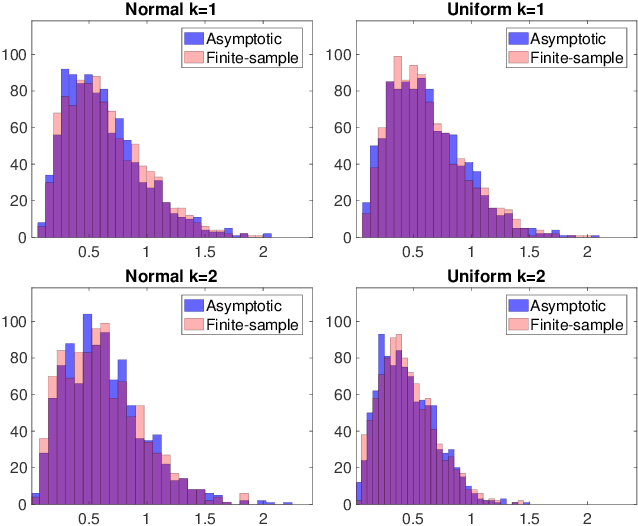
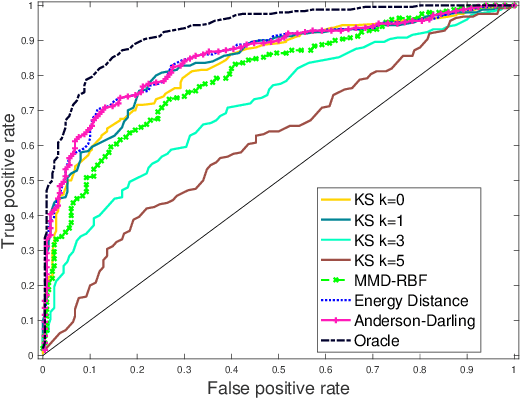
We present an extension of the Kolmogorov-Smirnov (KS) two-sample test, which can be more sensitive to differences in the tails. Our test statistic is an integral probability metric (IPM) defined over a higher-order total variation ball, recovering the original KS test as its simplest case. We give an exact representer result for our IPM, which generalizes the fact that the original KS test statistic can be expressed in equivalent variational and CDF forms. For small enough orders ($k \leq 5$), we develop a linear-time algorithm for computing our higher-order KS test statistic; for all others ($k \geq 6$), we give a nearly linear-time approximation. We derive the asymptotic null distribution for our test, and show that our nearly linear-time approximation shares the same asymptotic null. Lastly, we complement our theory with numerical studies.
Additive Models with Trend Filtering
Apr 28, 2018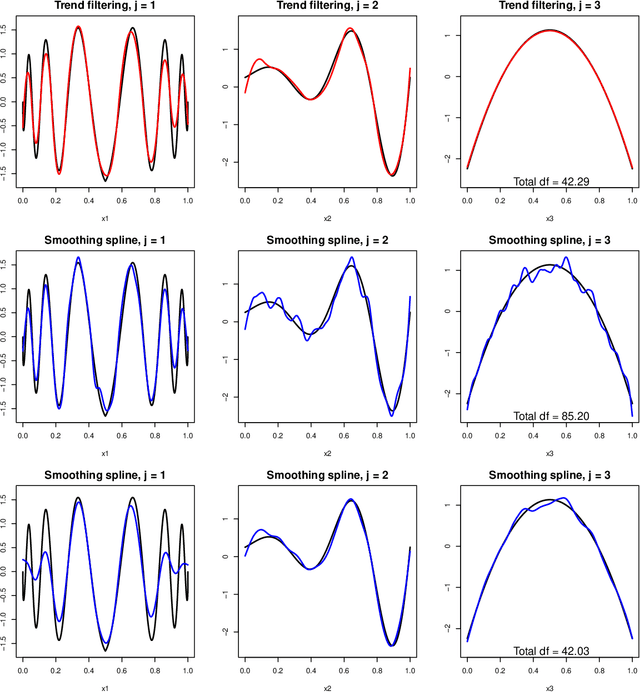
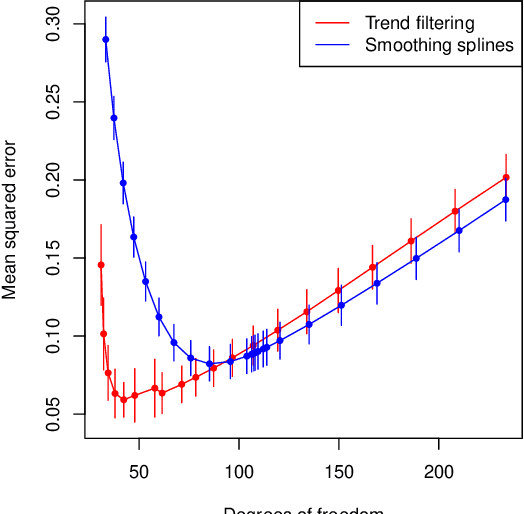
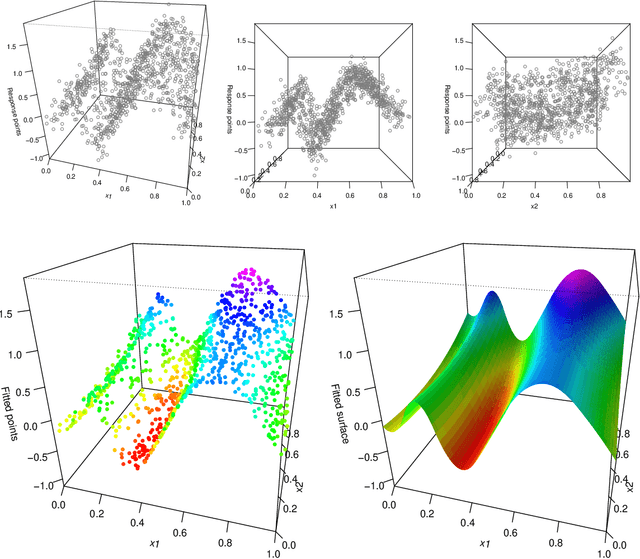
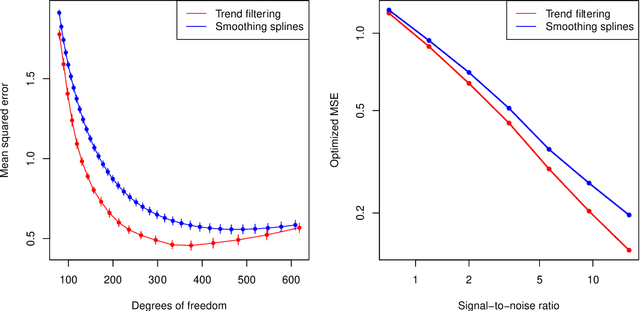
We consider additive models built with trend filtering, i.e., additive models whose components are each regularized by the (discrete) total variation of their $(k+1)$st (discrete) derivative, for a chosen integer $k \geq 0$. This results in $k$th degree piecewise polynomial components, (e.g., $k=0$ gives piecewise constant components, $k=1$ gives piecewise linear, $k=2$ gives piecewise quadratic, etc.). Analogous to its advantages in the univariate case, additive trend filtering has favorable theoretical and computational properties, thanks in large part to the localized nature of the (discrete) total variation regularizer that it uses. On the theory side, we derive fast error rates for additive trend filtering estimates, and show these rates are minimax optimal when the underlying function is additive and has component functions whose derivatives are of bounded variation. We also show that these rates are unattainable by additive smoothing splines (and by additive models built from linear smoothers, in general). On the computational side, as per the standard in additive models, backfitting is an appealing method for optimization, but it is particularly appealing for additive trend filtering because we can leverage a few highly efficient univariate trend filtering solvers. Going one step further, we derive a new backfitting algorithm whose iterations can be run in parallel, which (as far as we know) is the first of its kind. Lastly, we present experiments that examine the empirical performance of additive trend filtering, and outline some possible extensions.
Total Variation Classes Beyond 1d: Minimax Rates, and the Limitations of Linear Smoothers
May 26, 2016
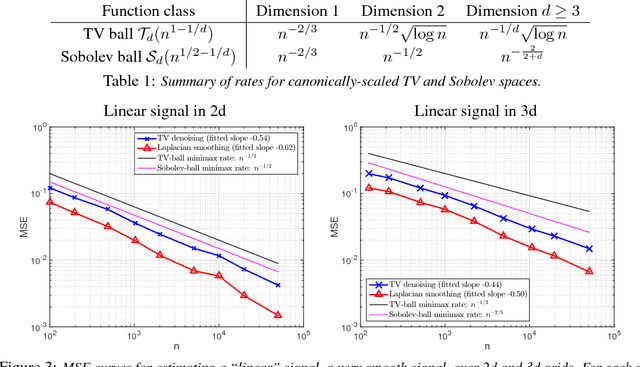
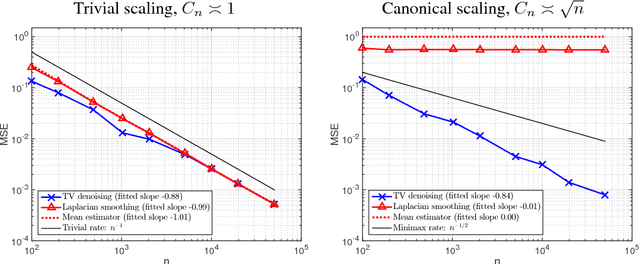
We consider the problem of estimating a function defined over $n$ locations on a $d$-dimensional grid (having all side lengths equal to $n^{1/d}$). When the function is constrained to have discrete total variation bounded by $C_n$, we derive the minimax optimal (squared) $\ell_2$ estimation error rate, parametrized by $n$ and $C_n$. Total variation denoising, also known as the fused lasso, is seen to be rate optimal. Several simpler estimators exist, such as Laplacian smoothing and Laplacian eigenmaps. A natural question is: can these simpler estimators perform just as well? We prove that these estimators, and more broadly all estimators given by linear transformations of the input data, are suboptimal over the class of functions with bounded variation. This extends fundamental findings of Donoho and Johnstone [1998] on 1-dimensional total variation spaces to higher dimensions. The implication is that the computationally simpler methods cannot be used for such sophisticated denoising tasks, without sacrificing statistical accuracy. We also derive minimax rates for discrete Sobolev spaces over $d$-dimensional grids, which are, in some sense, smaller than the total variation function spaces. Indeed, these are small enough spaces that linear estimators can be optimal---and a few well-known ones are, such as Laplacian smoothing and Laplacian eigenmaps, as we show. Lastly, we investigate the problem of adaptivity of the total variation denoiser to these smaller Sobolev function spaces.
Parallel and Distributed Block-Coordinate Frank-Wolfe Algorithms
Feb 13, 2016
We develop parallel and distributed Frank-Wolfe algorithms; the former on shared memory machines with mini-batching, and the latter in a delayed update framework. Whenever possible, we perform computations asynchronously, which helps attain speedups on multicore machines as well as in distributed environments. Moreover, instead of worst-case bounded delays, our methods only depend (mildly) on \emph{expected} delays, allowing them to be robust to stragglers and faulty worker threads. Our algorithms assume block-separable constraints, and subsume the recent Block-Coordinate Frank-Wolfe (BCFW) method~\citep{lacoste2013block}. Our analysis reveals problem-dependent quantities that govern the speedups of our methods over BCFW. We present experiments on structural SVM and Group Fused Lasso, obtaining significant speedups over competing state-of-the-art (and synchronous) methods.