 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentCRF: Continuous CRF for Efficient Latent Diffusion
Dec 24, 2024



Latent Diffusion Models (LDMs) produce high-quality, photo-realistic images, however, the latency incurred by multiple costly inference iterations can restrict their applicability. We introduce LatentCRF, a continuous Conditional Random Field (CRF) model, implemented as a neural network layer, that models the spatial and semantic relationships among the latent vectors in the LDM. By replacing some of the computationally-intensive LDM inference iterations with our lightweight LatentCRF, we achieve a superior balance between quality, speed and diversity. We increase inference efficiency by 33% with no loss in image quality or diversity compared to the full LDM. LatentCRF is an easy add-on, which does not require modifying the LDM.
Efficient Document Ranking with Learnable Late Interactions
Jun 25, 2024



Cross-Encoder (CE) and Dual-Encoder (DE) models are two fundamental approaches for query-document relevance in information retrieval. To predict relevance, CE models use joint query-document embeddings, while DE models maintain factorized query and document embeddings; usually, the former has higher quality while the latter benefits from lower latency. Recently, late-interaction models have been proposed to realize more favorable latency-quality tradeoffs, by using a DE structure followed by a lightweight scorer based on query and document token embeddings. However, these lightweight scorers are often hand-crafted, and there is no understanding of their approximation power; further, such scorers require access to individual document token embeddings, which imposes an increased latency and storage burden. In this paper, we propose novel learnable late-interaction models (LITE) that resolve these issues. Theoretically, we prove that LITE is a universal approximator of continuous scoring functions, even for relatively small embedding dimension. Empirically, LITE outperforms previous late-interaction models such as ColBERT on both in-domain and zero-shot re-ranking tasks. For instance, experiments on MS MARCO passage re-ranking show that LITE not only yields a model with better generalization, but also lowers latency and requires 0.25x storage compared to ColBERT.
SPEGTI: Structured Prediction for Efficient Generative Text-to-Image Models
Aug 14, 2023Modern text-to-image generation models produce high-quality images that are both photorealistic and faithful to the text prompts. However, this quality comes at significant computational cost: nearly all of these models are iterative and require running inference multiple times with large models. This iterative process is needed to ensure that different regions of the image are not only aligned with the text prompt, but also compatible with each other. In this work, we propose a light-weight approach to achieving this compatibility between different regions of an image, using a Markov Random Field (MRF) model. This method is shown to work in conjunction with the recently proposed Muse model. The MRF encodes the compatibility among image tokens at different spatial locations and enables us to significantly reduce the required number of Muse prediction steps. Inference with the MRF is significantly cheaper, and its parameters can be quickly learned through back-propagation by modeling MRF inference as a differentiable neural-network layer. Our full model, SPEGTI, uses this proposed MRF model to speed up Muse by 1.5X with no loss in output image quality.
EmbedDistill: A Geometric Knowledge Distillation for Information Retrieval
Jan 27, 2023



Large neural models (such as Transformers) achieve state-of-the-art performance for information retrieval (IR). In this paper, we aim to improve distillation methods that pave the way for the deployment of such models in practice. The proposed distillation approach supports both retrieval and re-ranking stages and crucially leverages the relative geometry among queries and documents learned by the large teacher model. It goes beyond existing distillation methods in the IR literature, which simply rely on the teacher's scalar scores over the training data, on two fronts: providing stronger signals about local geometry via embedding matching and attaining better coverage of data manifold globally via query generation. Embedding matching provides a stronger signal to align the representations of the teacher and student models. At the same time, query generation explores the data manifold to reduce the discrepancies between the student and teacher where training data is sparse. Our distillation approach is theoretically justified and applies to both dual encoder (DE) and cross-encoder (CE) models. Furthermore, for distilling a CE model to a DE model via embedding matching, we propose a novel dual pooling-based scorer for the CE model that facilitates a distillation-friendly embedding geometry, especially for DE student models.
When does mixup promote local linearity in learned representations?
Oct 28, 2022



Mixup is a regularization technique that artificially produces new samples using convex combinations of original training points. This simple technique has shown strong empirical performance, and has been heavily used as part of semi-supervised learning techniques such as mixmatch~\citep{berthelot2019mixmatch} and interpolation consistent training (ICT)~\citep{verma2019interpolation}. In this paper, we look at Mixup through a \emph{representation learning} lens in a semi-supervised learning setup. In particular, we study the role of Mixup in promoting linearity in the learned network representations. Towards this, we study two questions: (1) how does the Mixup loss that enforces linearity in the \emph{last} network layer propagate the linearity to the \emph{earlier} layers?; and (2) how does the enforcement of stronger Mixup loss on more than two data points affect the convergence of training? We empirically investigate these properties of Mixup on vision datasets such as CIFAR-10, CIFAR-100 and SVHN. Our results show that supervised Mixup training does not make \emph{all} the network layers linear; in fact the \emph{intermediate layers} become more non-linear during Mixup training compared to a network that is trained \emph{without} Mixup. However, when Mixup is used as an unsupervised loss, we observe that all the network layers become more linear resulting in faster training convergence.
Disentangling Sampling and Labeling Bias for Learning in Large-Output Spaces
May 12, 2021
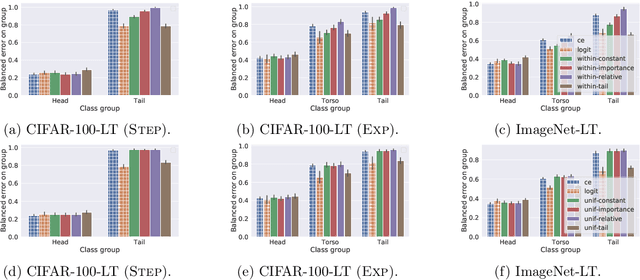

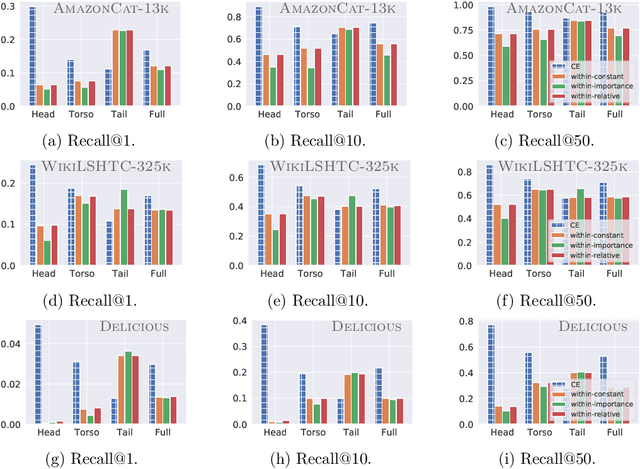
Negative sampling schemes enable efficient training given a large number of classes, by offering a means to approximate a computationally expensive loss function that takes all labels into account. In this paper, we present a new connection between these schemes and loss modification techniques for countering label imbalance. We show that different negative sampling schemes implicitly trade-off performance on dominant versus rare labels. Further, we provide a unified means to explicitly tackle both sampling bias, arising from working with a subset of all labels, and labeling bias, which is inherent to the data due to label imbalance. We empirically verify our findings on long-tail classification and retrieval benchmarks.
Balancing Constraints and Submodularity in Data Subset Selection
Apr 26, 2021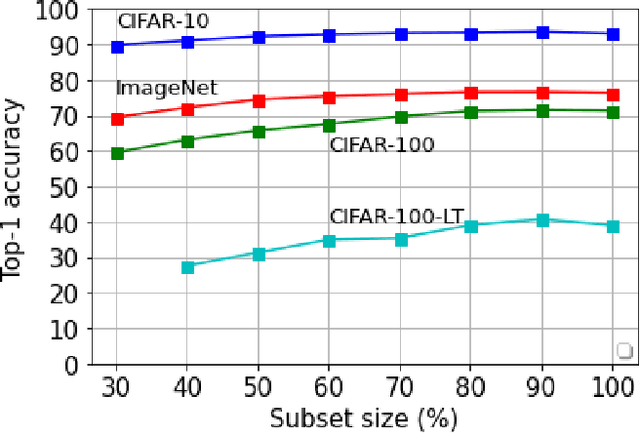
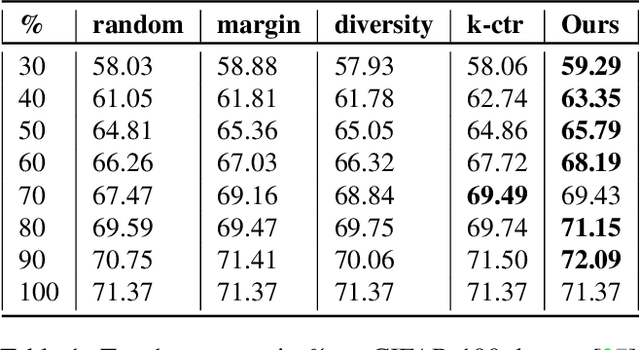
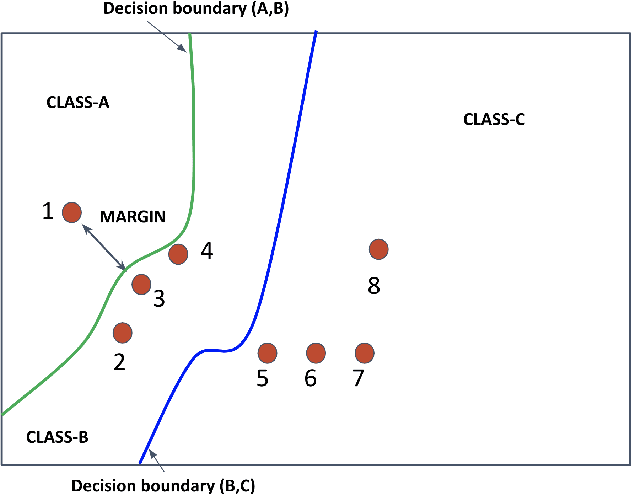
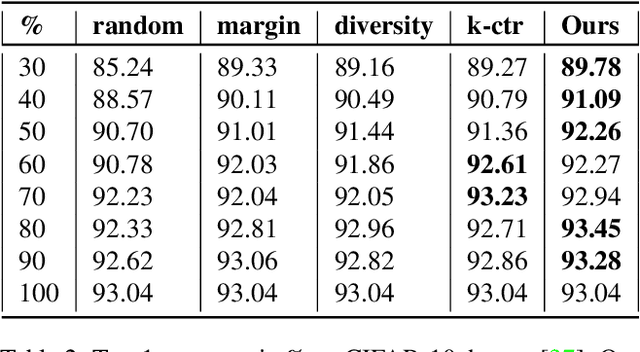
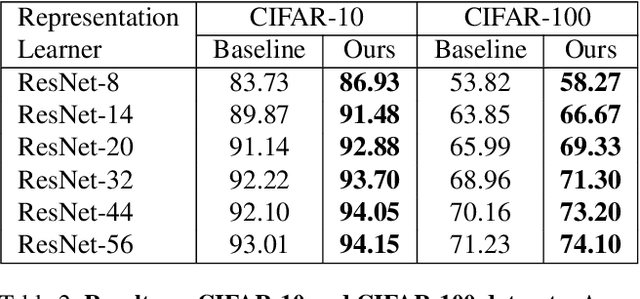
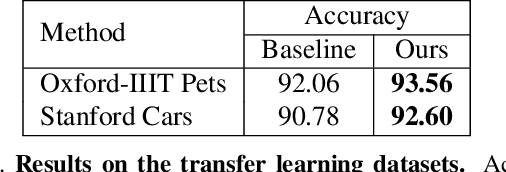
Deep learning has yielded extraordinary results in vision and natural language processing, but this achievement comes at a cost. Most deep learning models require enormous resources during training, both in terms of computation and in human labeling effort. In this paper, we show that one can achieve similar accuracy to traditional deep-learning models, while using less training data. Much of the previous work in this area relies on using uncertainty or some form of diversity to select subsets of a larger training set. Submodularity, a discrete analogue of convexity, has been exploited to model diversity in various settings including data subset selection. In contrast to prior methods, we propose a novel diversity driven objective function, and balancing constraints on class labels and decision boundaries using matroids. This allows us to use efficient greedy algorithms with approximation guarantees for subset selection. We outperform baselines on standard image classification datasets such as CIFAR-10, CIFAR-100, and ImageNet. In addition, we also show that the proposed balancing constraints can play a key role in boosting the performance in long-tailed datasets such as CIFAR-100-LT.
Kernelized Classification in Deep Networks
Dec 08, 2020

In this paper, we propose a kernelized classification layer for deep networks. Although conventional deep networks introduce an abundance of nonlinearity for representation (feature) learning, they almost universally use a linear classifier on the learned feature vectors. We introduce a nonlinear classification layer by using the kernel trick on the softmax cross-entropy loss function during training and the scorer function during testing. Furthermore, we study the choice of kernel functions one could use with this framework and show that the optimal kernel function for a given problem can be learned automatically within the deep network itself using the usual backpropagation and gradient descent methods. To this end, we exploit a classic mathematical result on the positive definite kernels on the unit n-sphere embedded in the (n+1)-dimensional Euclidean space. We show the usefulness of the proposed nonlinear classification layer on several vision datasets and tasks.
Long-tail learning via logit adjustment
Jul 14, 2020
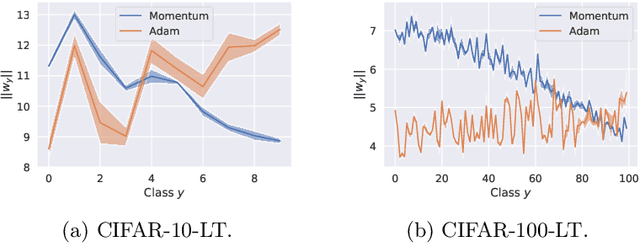
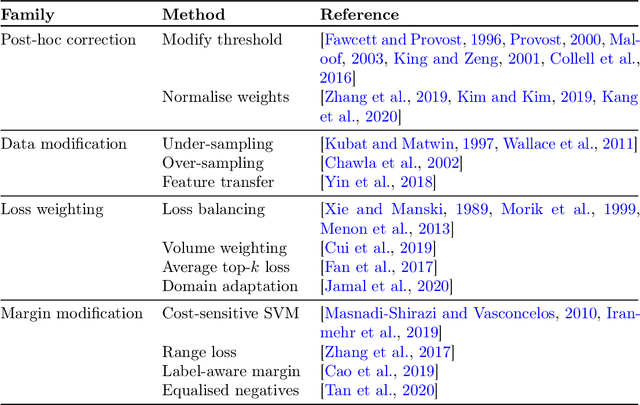
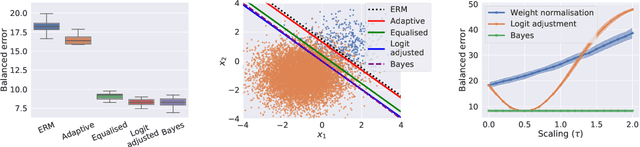
Real-world classification problems typically exhibit an imbalanced or long-tailed label distribution, wherein many labels are associated with only a few samples. This poses a challenge for generalisation on such labels, and also makes na\"ive learning biased towards dominant labels. In this paper, we present two simple modifications of standard softmax cross-entropy training to cope with these challenges. Our techniques revisit the classic idea of logit adjustment based on the label frequencies, either applied post-hoc to a trained model, or enforced in the loss during training. Such adjustment encourages a large relative margin between logits of rare versus dominant labels. These techniques unify and generalise several recent proposals in the literature, while possessing firmer statistical grounding and empirical performance.
Bipartite Conditional Random Fields for Panoptic Segmentation
Dec 11, 2019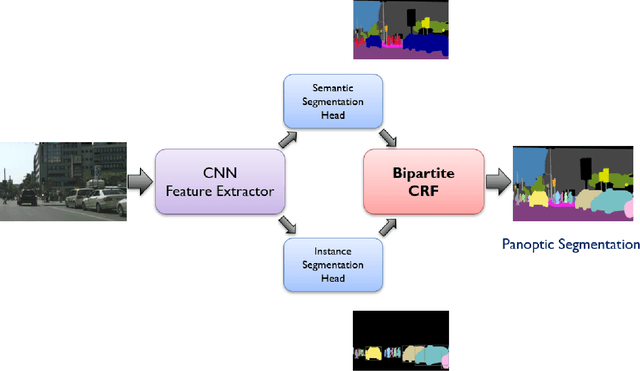
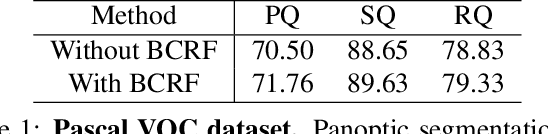
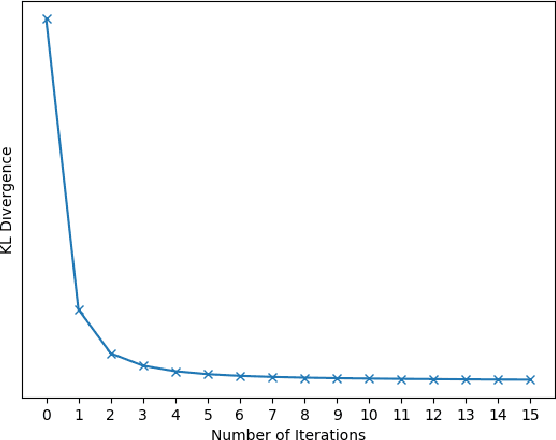

We tackle the panoptic segmentation problem with a conditional random field (CRF) model. Panoptic segmentation involves assigning a semantic label and an instance label to each pixel of a given image. At each pixel, the semantic label and the instance label should be compatible. Furthermore, a good panoptic segmentation should have a number of other desirable properties such as the spatial and color consistency of the labeling (similar looking neighboring pixels should have the same semantic label and the instance label). To tackle this problem, we propose a CRF model, named Bipartite CRF or BCRF, with two types of random variables for semantic and instance labels. In this formulation, various energies are defined within and across the two types of random variables to encourage a consistent panoptic segmentation. We propose a mean-field-based efficient inference algorithm for solving the CRF and empirically show its convergence properties. This algorithm is fully differentiable, and therefore, BCRF inference can be included as a trainable module in a deep network. In the experimental evaluation, we quantitatively and qualitatively show that the BCRF yields superior panoptic segmentation results in practice.