 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers Boost the Performance of Decision Trees on Tabular Data across Sample Sizes
Feb 06, 2025Large language models (LLMs) perform remarkably well on tabular datasets in zero- and few-shot settings, since they can extract meaning from natural language column headers that describe features and labels. Similarly, TabPFN, a recent non-LLM transformer pretrained on numerous tables for in-context learning, has demonstrated excellent performance for dataset sizes up to a thousand samples. In contrast, gradient-boosted decision trees (GBDTs) are typically trained from scratch on each dataset without benefiting from pretraining data and must learn the relationships between columns from their entries alone since they lack natural language understanding. LLMs and TabPFN excel on small tabular datasets where a strong prior is essential, yet they are not competitive with GBDTs on medium or large datasets, since their context lengths are limited. In this paper, we propose a simple and lightweight approach for fusing large language models and TabPFN with gradient-boosted decision trees, which allows scalable GBDTs to benefit from the natural language capabilities and pretraining of transformers. We name our fusion methods LLM-Boost and PFN-Boost, respectively. While matching or surpassing the performance of the transformer at sufficiently small dataset sizes and GBDTs at sufficiently large sizes, LLM-Boost and PFN-Boost outperform both standalone components on a wide range of dataset sizes in between. We demonstrate state-of-the-art performance against numerous baselines and ensembling algorithms. We find that PFN-Boost achieves the best average performance among all methods we test for all but very small dataset sizes. We release our code at http://github.com/MayukaJ/LLM-Boost .
PUP 3D-GS: Principled Uncertainty Pruning for 3D Gaussian Splatting
Jun 14, 2024
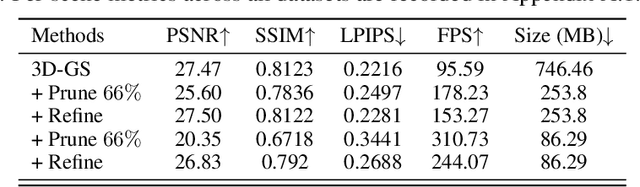
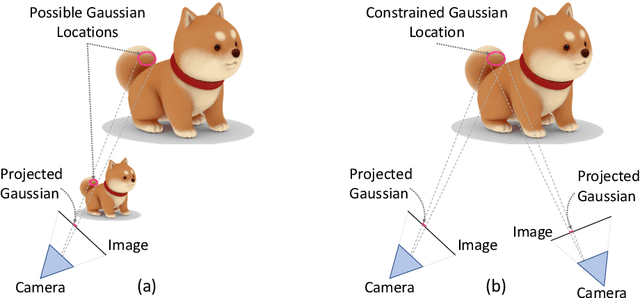
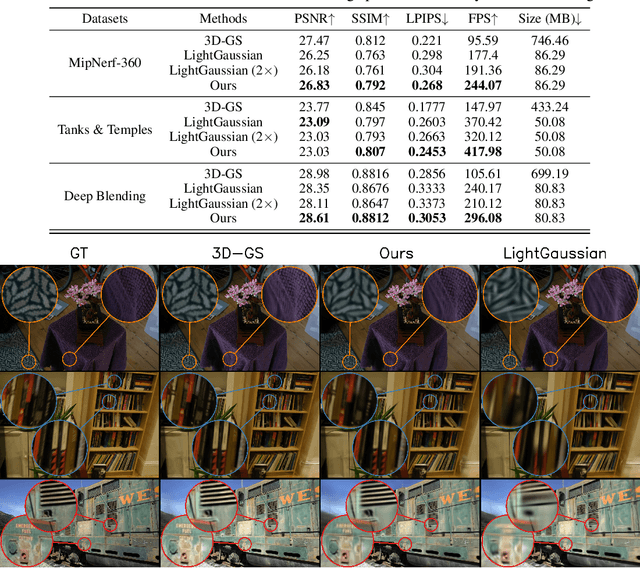
Recent advancements in novel view synthesis have enabled real-time rendering speeds and high reconstruction accuracy. 3D Gaussian Splatting (3D-GS), a foundational point-based parametric 3D scene representation, models scenes as large sets of 3D Gaussians. Complex scenes can comprise of millions of Gaussians, amounting to large storage and memory requirements that limit the viability of 3D-GS on devices with limited resources. Current techniques for compressing these pretrained models by pruning Gaussians rely on combining heuristics to determine which ones to remove. In this paper, we propose a principled spatial sensitivity pruning score that outperforms these approaches. It is computed as a second-order approximation of the reconstruction error on the training views with respect to the spatial parameters of each Gaussian. Additionally, we propose a multi-round prune-refine pipeline that can be applied to any pretrained 3D-GS model without changing the training pipeline. After pruning 88.44% of the Gaussians, we observe that our PUP 3D-GS pipeline increases the average rendering speed of 3D-GS by 2.65$\times$ while retaining more salient foreground information and achieving higher image quality metrics than previous pruning techniques on scenes from the Mip-NeRF 360, Tanks & Temples, and Deep Blending datasets.
From Pixels to Prose: A Large Dataset of Dense Image Captions
Jun 14, 2024

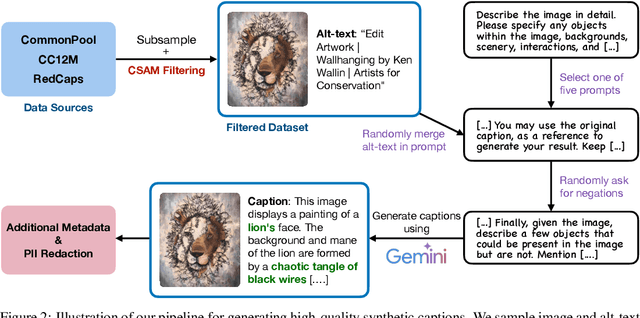
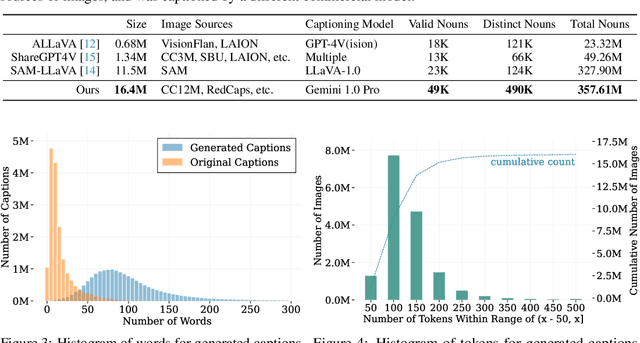
Training large vision-language models requires extensive, high-quality image-text pairs. Existing web-scraped datasets, however, are noisy and lack detailed image descriptions. To bridge this gap, we introduce PixelProse, a comprehensive dataset of over 16M (million) synthetically generated captions, leveraging cutting-edge vision-language models for detailed and accurate descriptions. To ensure data integrity, we rigorously analyze our dataset for problematic content, including child sexual abuse material (CSAM), personally identifiable information (PII), and toxicity. We also provide valuable metadata such as watermark presence and aesthetic scores, aiding in further dataset filtering. We hope PixelProse will be a valuable resource for future vision-language research. PixelProse is available at https://huggingface.co/datasets/tomg-group-umd/pixelprose
Extending Multi-Object Tracking systems to better exploit appearance and 3D information
Dec 25, 2019
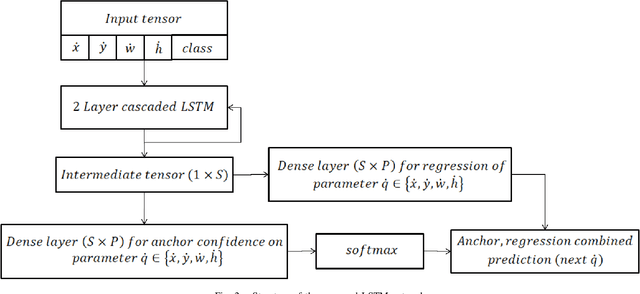
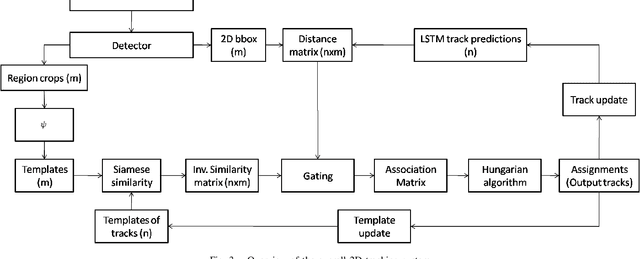
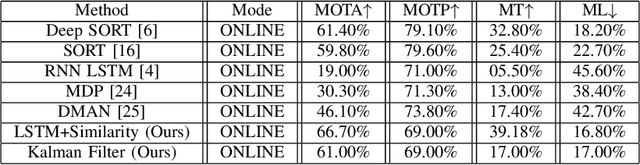
Tracking multiple objects in real time is essential for a variety of real-world applications, with self-driving industry being at the foremost. This work involves exploiting temporally varying appearance and motion information for tracking. Siamese networks have recently become highly successful at appearance based single object tracking and Recurrent Neural Networks have started dominating both motion and appearance based tracking. Our work focuses on combining Siamese networks and RNNs to exploit appearance and motion information respectively to build a joint system capable of real time multi-object tracking. We further explore heuristics based constraints for tracking in the Birds Eye View Space for efficiently exploiting 3D information as a constrained optimization problem for track prediction.
Bipartite Conditional Random Fields for Panoptic Segmentation
Dec 11, 2019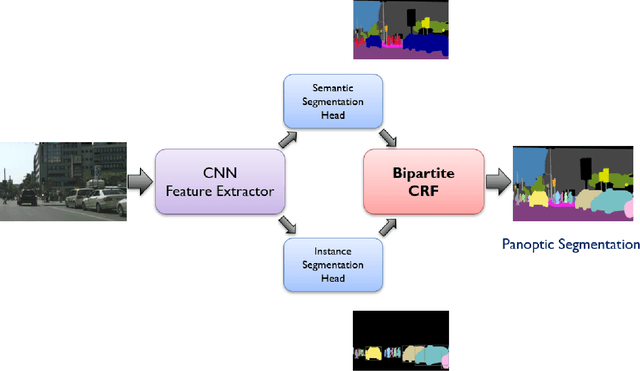
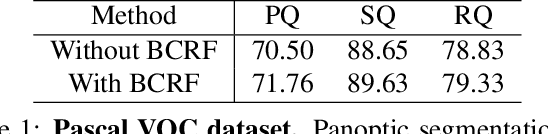
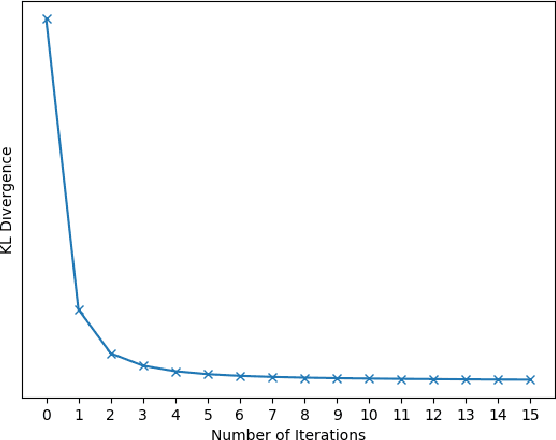

We tackle the panoptic segmentation problem with a conditional random field (CRF) model. Panoptic segmentation involves assigning a semantic label and an instance label to each pixel of a given image. At each pixel, the semantic label and the instance label should be compatible. Furthermore, a good panoptic segmentation should have a number of other desirable properties such as the spatial and color consistency of the labeling (similar looking neighboring pixels should have the same semantic label and the instance label). To tackle this problem, we propose a CRF model, named Bipartite CRF or BCRF, with two types of random variables for semantic and instance labels. In this formulation, various energies are defined within and across the two types of random variables to encourage a consistent panoptic segmentation. We propose a mean-field-based efficient inference algorithm for solving the CRF and empirically show its convergence properties. This algorithm is fully differentiable, and therefore, BCRF inference can be included as a trainable module in a deep network. In the experimental evaluation, we quantitatively and qualitatively show that the BCRF yields superior panoptic segmentation results in practice.