 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotate Both Ways: Time-and-Order RoPE for Generative Recommendation
Oct 23, 2025Generative recommenders, typically transformer-based autoregressive models, predict the next item or action from a user's interaction history. Their effectiveness depends on how the model represents where an interaction event occurs in the sequence (discrete index) and when it occurred in wall-clock time. Prevailing approaches inject time via learned embeddings or relative attention biases. In this paper, we argue that RoPE-based approaches, if designed properly, can be a stronger alternative for jointly modeling temporal and sequential information in user behavior sequences. While vanilla RoPE in LLMs considers only token order, generative recommendation requires incorporating both event time and token index. To address this, we propose Time-and-Order RoPE (TO-RoPE), a family of rotary position embedding designs that treat index and time as angle sources shaping the query-key geometry directly. We present three instantiations: early fusion, split-by-dim, and split-by-head. Extensive experiments on both publicly available datasets and a proprietary industrial dataset show that TO-RoPE variants consistently improve accuracy over existing methods for encoding time and index. These results position rotary embeddings as a simple, principled, and deployment-friendly foundation for generative recommendation.
Cost-Aware Contrastive Routing for LLMs
Aug 17, 2025



We study cost-aware routing for large language models across diverse and dynamic pools of models. Existing approaches often overlook prompt-specific context, rely on expensive model profiling, assume a fixed set of experts, or use inefficient trial-and-error strategies. We introduce Cost-Spectrum Contrastive Routing (CSCR), a lightweight framework that maps both prompts and models into a shared embedding space to enable fast, cost-sensitive selection. CSCR uses compact, fast-to-compute logit footprints for open-source models and perplexity fingerprints for black-box APIs. A contrastive encoder is trained to favor the cheapest accurate expert within adaptive cost bands. At inference time, routing reduces to a single k-NN lookup via a FAISS index, requiring no retraining when the expert pool changes and enabling microsecond latency. Across multiple benchmarks, CSCR consistently outperforms baselines, improving the accuracy-cost tradeoff by up to 25%, while generalizing robustly to unseen LLMs and out-of-distribution prompts.
ARGUS: Hallucination and Omission Evaluation in Video-LLMs
Jun 09, 2025Video large language models have not yet been widely deployed, largely due to their tendency to hallucinate. Typical benchmarks for Video-LLMs rely simply on multiple-choice questions. Unfortunately, VideoLLMs hallucinate far more aggressively on freeform text generation tasks like video captioning than they do on multiple choice verification tasks. To address this weakness, we propose ARGUS, a VideoLLM benchmark that measures freeform video captioning performance. By comparing VideoLLM outputs to human ground truth captions, ARGUS quantifies dual metrics. First, we measure the rate of hallucinations in the form of incorrect statements about video content or temporal relationships. Second, we measure the rate at which the model omits important descriptive details. Together, these dual metrics form a comprehensive view of video captioning performance.
Bilevel ZOFO: Bridging Parameter-Efficient and Zeroth-Order Techniques for Efficient LLM Fine-Tuning and Meta-Training
Feb 05, 2025



Fine-tuning pre-trained Large Language Models (LLMs) for downstream tasks using First-Order (FO) optimizers presents significant computational challenges. Parameter-Efficient Fine-Tuning(PEFT) methods have been proposed to address these challenges by freezing most model parameters and training only a small subset. While PEFT is efficient, it may not outperform full fine-tuning when high task-specific performance is required. Zeroth-Order (ZO) methods offer an alternative for fine-tuning the entire pre-trained model by approximating gradients using only the forward pass, thus eliminating the computational burden of back-propagation in first-order methods. However, when implementing ZO methods, a hard prompt is crucial, and relying on simple, fixed hard prompts may not be optimal. In this paper, we propose a bilevel optimization framework that complements ZO methods with PEFT to mitigate sensitivity to hard prompts while efficiently and effectively fine-tuning LLMs. Our Bilevel ZOFO (Zeroth-Order-First-Order) method employs a double-loop optimization strategy, where only the gradient of the PEFT model and the forward pass of the base model are required. We provide convergence guarantees for Bilevel ZOFO. Empirically, we demonstrate that Bilevel ZOFO outperforms both PEFT and ZO methods in single-task settings while maintaining similar memory efficiency. Additionally, we show its strong potential for multitask learning. Compared to current first-order meta-training algorithms for multitask learning, our method has significantly lower computational demands while maintaining or improving performance.
ToMoE: Converting Dense Large Language Models to Mixture-of-Experts through Dynamic Structural Pruning
Jan 25, 2025Large Language Models (LLMs) have demonstrated remarkable abilities in tackling a wide range of complex tasks. However, their huge computational and memory costs raise significant challenges in deploying these models on resource-constrained devices or efficiently serving them. Prior approaches have attempted to alleviate these problems by permanently removing less important model structures, yet these methods often result in substantial performance degradation due to the permanent deletion of model parameters. In this work, we tried to mitigate this issue by reducing the number of active parameters without permanently removing them. Specifically, we introduce a differentiable dynamic pruning method that pushes dense models to maintain a fixed number of active parameters by converting their MLP layers into a Mixture of Experts (MoE) architecture. Our method, even without fine-tuning, consistently outperforms previous structural pruning techniques across diverse model families, including Phi-2, LLaMA-2, LLaMA-3, and Qwen-2.5.
Efficient Fine-Tuning and Concept Suppression for Pruned Diffusion Models
Dec 19, 2024



Recent advances in diffusion generative models have yielded remarkable progress. While the quality of generated content continues to improve, these models have grown considerably in size and complexity. This increasing computational burden poses significant challenges, particularly in resource-constrained deployment scenarios such as mobile devices. The combination of model pruning and knowledge distillation has emerged as a promising solution to reduce computational demands while preserving generation quality. However, this technique inadvertently propagates undesirable behaviors, including the generation of copyrighted content and unsafe concepts, even when such instances are absent from the fine-tuning dataset. In this paper, we propose a novel bilevel optimization framework for pruned diffusion models that consolidates the fine-tuning and unlearning processes into a unified phase. Our approach maintains the principal advantages of distillation-namely, efficient convergence and style transfer capabilities-while selectively suppressing the generation of unwanted content. This plug-in framework is compatible with various pruning and concept unlearning methods, facilitating efficient, safe deployment of diffusion models in controlled environments.
Not All Prompts Are Made Equal: Prompt-based Pruning of Text-to-Image Diffusion Models
Jun 17, 2024



Text-to-image (T2I) diffusion models have demonstrated impressive image generation capabilities. Still, their computational intensity prohibits resource-constrained organizations from deploying T2I models after fine-tuning them on their internal target data. While pruning techniques offer a potential solution to reduce the computational burden of T2I models, static pruning methods use the same pruned model for all input prompts, overlooking the varying capacity requirements of different prompts. Dynamic pruning addresses this issue by utilizing a separate sub-network for each prompt, but it prevents batch parallelism on GPUs. To overcome these limitations, we introduce Adaptive Prompt-Tailored Pruning (APTP), a novel prompt-based pruning method designed for T2I diffusion models. Central to our approach is a prompt router model, which learns to determine the required capacity for an input text prompt and routes it to an architecture code, given a total desired compute budget for prompts. Each architecture code represents a specialized model tailored to the prompts assigned to it, and the number of codes is a hyperparameter. We train the prompt router and architecture codes using contrastive learning, ensuring that similar prompts are mapped to nearby codes. Further, we employ optimal transport to prevent the codes from collapsing into a single one. We demonstrate APTP's effectiveness by pruning Stable Diffusion (SD) V2.1 using CC3M and COCO as target datasets. APTP outperforms the single-model pruning baselines in terms of FID, CLIP, and CMMD scores. Our analysis of the clusters learned by APTP reveals they are semantically meaningful. We also show that APTP can automatically discover previously empirically found challenging prompts for SD, e.g., prompts for generating text images, assigning them to higher capacity codes.
From Pixels to Prose: A Large Dataset of Dense Image Captions
Jun 14, 2024

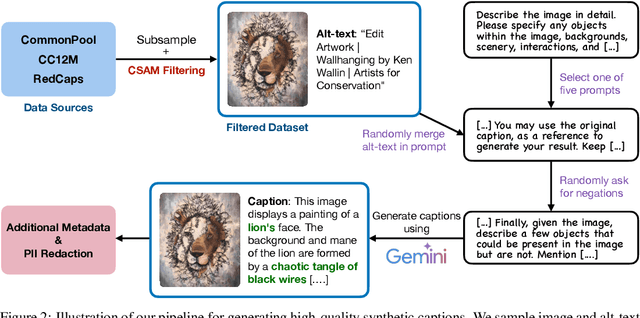
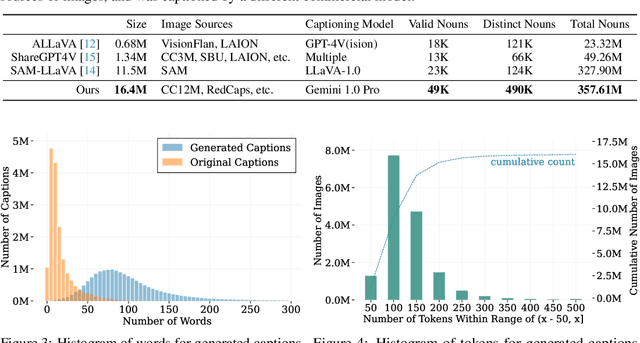
Training large vision-language models requires extensive, high-quality image-text pairs. Existing web-scraped datasets, however, are noisy and lack detailed image descriptions. To bridge this gap, we introduce PixelProse, a comprehensive dataset of over 16M (million) synthetically generated captions, leveraging cutting-edge vision-language models for detailed and accurate descriptions. To ensure data integrity, we rigorously analyze our dataset for problematic content, including child sexual abuse material (CSAM), personally identifiable information (PII), and toxicity. We also provide valuable metadata such as watermark presence and aesthetic scores, aiding in further dataset filtering. We hope PixelProse will be a valuable resource for future vision-language research. PixelProse is available at https://huggingface.co/datasets/tomg-group-umd/pixelprose
Deep Prompt Tuning for Graph Transformers
Sep 18, 2023


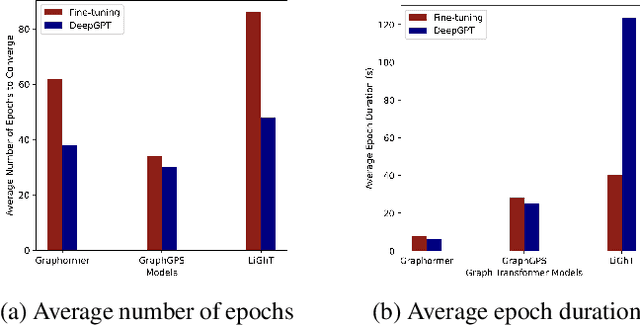
Graph transformers have gained popularity in various graph-based tasks by addressing challenges faced by traditional Graph Neural Networks. However, the quadratic complexity of self-attention operations and the extensive layering in graph transformer architectures present challenges when applying them to graph based prediction tasks. Fine-tuning, a common approach, is resource-intensive and requires storing multiple copies of large models. We propose a novel approach called deep graph prompt tuning as an alternative to fine-tuning for leveraging large graph transformer models in downstream graph based prediction tasks. Our method introduces trainable feature nodes to the graph and pre-pends task-specific tokens to the graph transformer, enhancing the model's expressive power. By freezing the pre-trained parameters and only updating the added tokens, our approach reduces the number of free parameters and eliminates the need for multiple model copies, making it suitable for small datasets and scalable to large graphs. Through extensive experiments on various-sized datasets, we demonstrate that deep graph prompt tuning achieves comparable or even superior performance to fine-tuning, despite utilizing significantly fewer task-specific parameters. Our contributions include the introduction of prompt tuning for graph transformers, its application to both graph transformers and message passing graph neural networks, improved efficiency and resource utilization, and compelling experimental results. This work brings attention to a promising approach to leverage pre-trained models in graph based prediction tasks and offers new opportunities for exploring and advancing graph representation learning.
Prediction of Post-Operative Renal and Pulmonary Complications Using Transformers
Jun 06, 2023Postoperative complications pose a significant challenge in the healthcare industry, resulting in elevated healthcare expenses and prolonged hospital stays, and in rare instances, patient mortality. To improve patient outcomes and reduce healthcare costs, healthcare providers rely on various perioperative risk scores to guide clinical decisions and prioritize care. In recent years, machine learning techniques have shown promise in predicting postoperative complications and fatality, with deep learning models achieving remarkable success in healthcare applications. However, research on the application of deep learning models to intra-operative anesthesia management data is limited. In this paper, we evaluate the performance of transformer-based models in predicting postoperative acute renal failure, postoperative pulmonary complications, and postoperative in-hospital mortality. We compare our method's performance with state-of-the-art tabular data prediction models, including gradient boosting trees and sequential attention models, on a clinical dataset. Our results demonstrate that transformer-based models can achieve superior performance in predicting postoperative complications and outperform traditional machine learning models. This work highlights the potential of deep learning techniques, specifically transformer-based models, in revolutionizing the healthcare industry's approach to postoperative care.