 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Generation with a Sphere Encoder
Feb 16, 2026We introduce the Sphere Encoder, an efficient generative framework capable of producing images in a single forward pass and competing with many-step diffusion models using fewer than five steps. Our approach works by learning an encoder that maps natural images uniformly onto a spherical latent space, and a decoder that maps random latent vectors back to the image space. Trained solely through image reconstruction losses, the model generates an image by simply decoding a random point on the sphere. Our architecture naturally supports conditional generation, and looping the encoder/decoder a few times can further enhance image quality. Across several datasets, the sphere encoder approach yields performance competitive with state of the art diffusions, but with a small fraction of the inference cost. Project page is available at https://sphere-encoder.github.io .
Zebra-CoT: A Dataset for Interleaved Vision Language Reasoning
Jul 22, 2025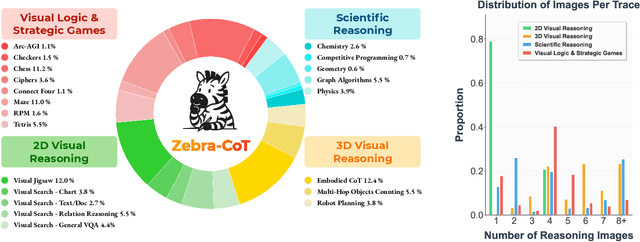

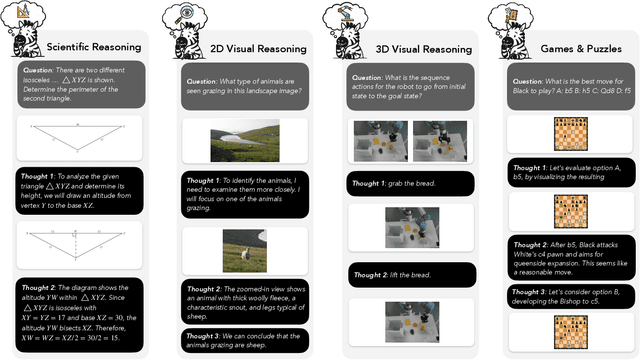

Humans often use visual aids, for example diagrams or sketches, when solving complex problems. Training multimodal models to do the same, known as Visual Chain of Thought (Visual CoT), is challenging due to: (1) poor off-the-shelf visual CoT performance, which hinders reinforcement learning, and (2) the lack of high-quality visual CoT training data. We introduce $\textbf{Zebra-CoT}$, a diverse large-scale dataset with 182,384 samples, containing logically coherent interleaved text-image reasoning traces. We focus on four categories of tasks where sketching or visual reasoning is especially natural, spanning scientific questions such as geometry, physics, and algorithms; 2D visual reasoning tasks like visual search and jigsaw puzzles; 3D reasoning tasks including 3D multi-hop inference, embodied and robot planning; visual logic problems and strategic games like chess. Fine-tuning the Anole-7B model on the Zebra-CoT training corpus results in an improvement of +12% in our test-set accuracy and yields up to +13% performance gain on standard VLM benchmark evaluations. Fine-tuning Bagel-7B yields a model that generates high-quality interleaved visual reasoning chains, underscoring Zebra-CoT's effectiveness for developing multimodal reasoning abilities. We open-source our dataset and models to support development and evaluation of visual CoT.
Zero-Shot Vision Encoder Grafting via LLM Surrogates
May 28, 2025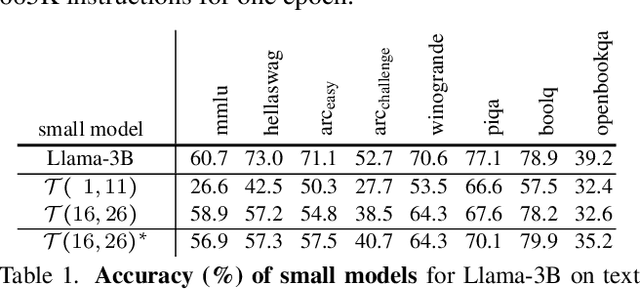
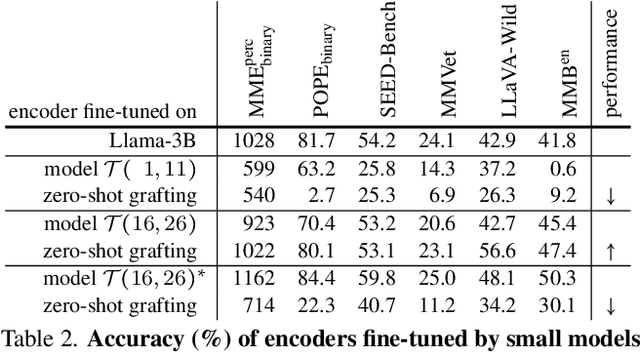
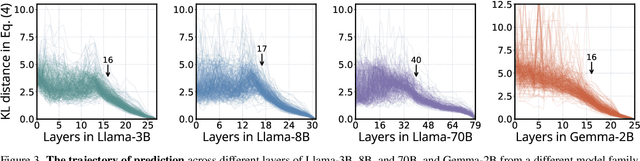

Vision language models (VLMs) typically pair a modestly sized vision encoder with a large language model (LLM), e.g., Llama-70B, making the decoder the primary computational burden during training. To reduce costs, a potential promising strategy is to first train the vision encoder using a small language model before transferring it to the large one. We construct small "surrogate models" that share the same embedding space and representation language as the large target LLM by directly inheriting its shallow layers. Vision encoders trained on the surrogate can then be directly transferred to the larger model, a process we call zero-shot grafting -- when plugged directly into the full-size target LLM, the grafted pair surpasses the encoder-surrogate pair and, on some benchmarks, even performs on par with full decoder training with the target LLM. Furthermore, our surrogate training approach reduces overall VLM training costs by ~45% when using Llama-70B as the decoder.
From Pixels to Prose: A Large Dataset of Dense Image Captions
Jun 14, 2024

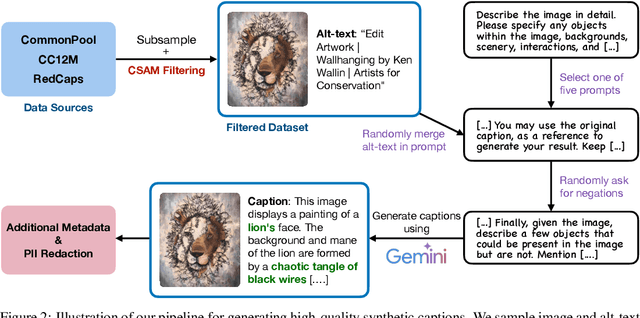
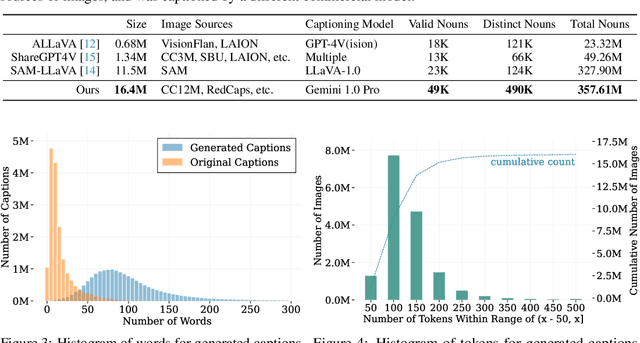
Training large vision-language models requires extensive, high-quality image-text pairs. Existing web-scraped datasets, however, are noisy and lack detailed image descriptions. To bridge this gap, we introduce PixelProse, a comprehensive dataset of over 16M (million) synthetically generated captions, leveraging cutting-edge vision-language models for detailed and accurate descriptions. To ensure data integrity, we rigorously analyze our dataset for problematic content, including child sexual abuse material (CSAM), personally identifiable information (PII), and toxicity. We also provide valuable metadata such as watermark presence and aesthetic scores, aiding in further dataset filtering. We hope PixelProse will be a valuable resource for future vision-language research. PixelProse is available at https://huggingface.co/datasets/tomg-group-umd/pixelprose
Object Recognition as Next Token Prediction
Dec 04, 2023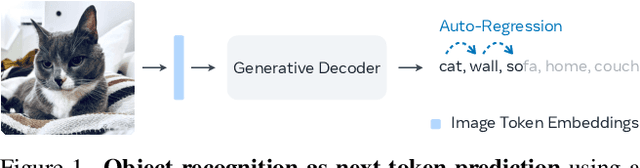
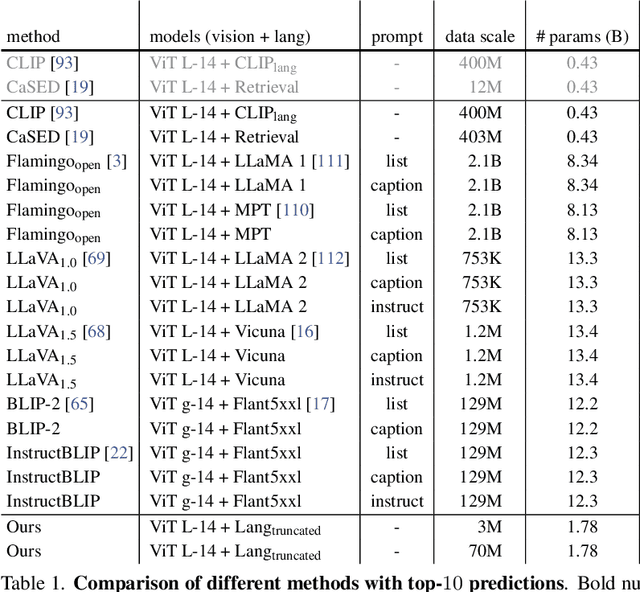
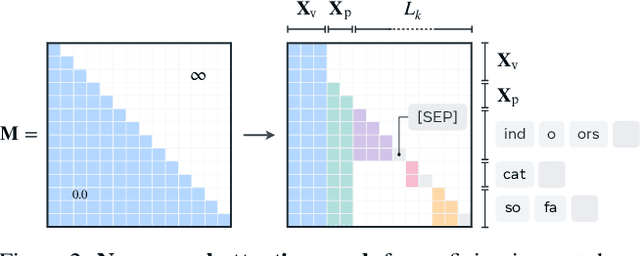

We present an approach to pose object recognition as next token prediction. The idea is to apply a language decoder that auto-regressively predicts the text tokens from image embeddings to form labels. To ground this prediction process in auto-regression, we customize a non-causal attention mask for the decoder, incorporating two key features: modeling tokens from different labels to be independent, and treating image tokens as a prefix. This masking mechanism inspires an efficient method - one-shot sampling - to simultaneously sample tokens of multiple labels in parallel and rank generated labels by their probabilities during inference. To further enhance the efficiency, we propose a simple strategy to construct a compact decoder by simply discarding the intermediate blocks of a pretrained language model. This approach yields a decoder that matches the full model's performance while being notably more efficient. The code is available at https://github.com/kaiyuyue/nxtp
Visible Feature Guidance for Crowd Pedestrian Detection
Sep 16, 2020
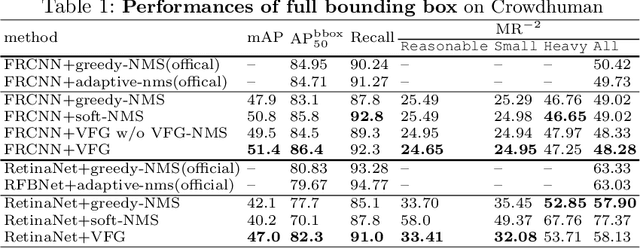
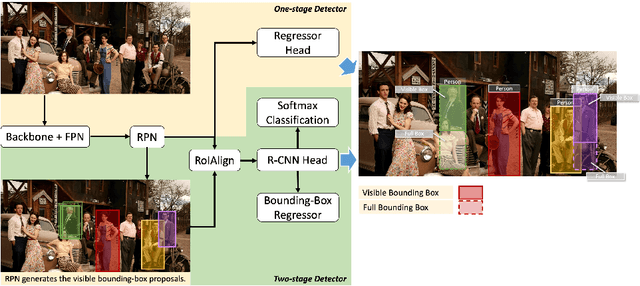
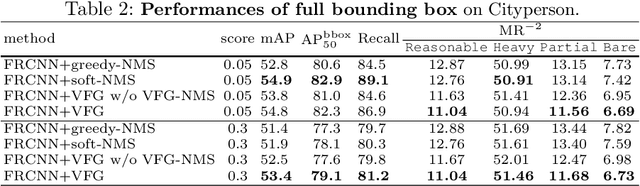
Heavy occlusion and dense gathering in crowd scene make pedestrian detection become a challenging problem, because it's difficult to guess a precise full bounding box according to the invisible human part. To crack this nut, we propose a mechanism called Visible Feature Guidance (VFG) for both training and inference. During training, we adopt visible feature to regress the simultaneous outputs of visible bounding box and full bounding box. Then we perform NMS only on visible bounding boxes to achieve the best fitting full box in inference. This manner can alleviate the incapable influence brought by NMS in crowd scene and make full bounding box more precisely. Furthermore, in order to ease feature association in the post application process, such as pedestrian tracking, we apply Hungarian algorithm to associate parts for a human instance. Our proposed method can stably bring about 2~3% improvements in mAP and AP50 for both two-stage and one-stage detector. It's also more effective for MR-2 especially with the stricter IoU. Experiments on Crowdhuman, Cityperson, Caltech and KITTI datasets show that visible feature guidance can help detector achieve promisingly better performances. Moreover, parts association produces a strong benchmark on Crowdhuman for the vision community.
Matching Guided Distillation
Aug 23, 2020
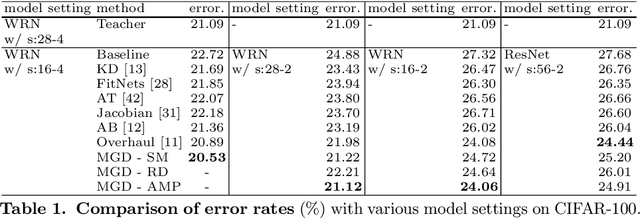
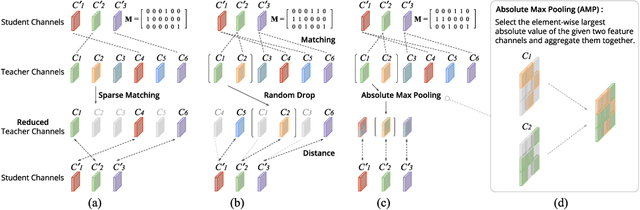
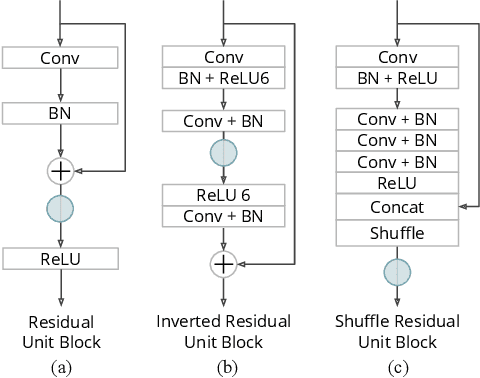
Feature distillation is an effective way to improve the performance for a smaller student model, which has fewer parameters and lower computation cost compared to the larger teacher model. Unfortunately, there is a common obstacle - the gap in semantic feature structure between the intermediate features of teacher and student. The classic scheme prefers to transform intermediate features by adding the adaptation module, such as naive convolutional, attention-based or more complicated one. However, this introduces two problems: a) The adaptation module brings more parameters into training. b) The adaptation module with random initialization or special transformation isn't friendly for distilling a pre-trained student. In this paper, we present Matching Guided Distillation (MGD) as an efficient and parameter-free manner to solve these problems. The key idea of MGD is to pose matching the teacher channels with students' as an assignment problem. We compare three solutions of the assignment problem to reduce channels from teacher features with partial distillation loss. The overall training takes a coordinate-descent approach between two optimization objects - assignments update and parameters update. Since MGD only contains normalization or pooling operations with negligible computation cost, it is flexible to plug into network with other distillation methods.
Compact Generalized Non-local Network
Nov 01, 2018
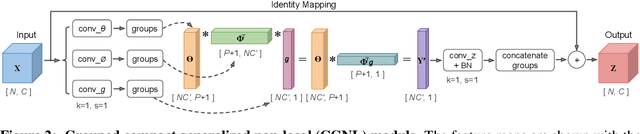
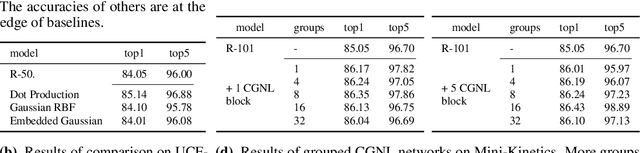

The non-local module is designed for capturing long-range spatio-temporal dependencies in images and videos. Although having shown excellent performance, it lacks the mechanism to model the interactions between positions across channels, which are of vital importance in recognizing fine-grained objects and actions. To address this limitation, we generalize the non-local module and take the correlations between the positions of any two channels into account. This extension utilizes the compact representation for multiple kernel functions with Taylor expansion that makes the generalized non-local module in a fast and low-complexity computation flow. Moreover, we implement our generalized non-local method within channel groups to ease the optimization. Experimental results illustrate the clear-cut improvements and practical applicability of the generalized non-local module on both fine-grained object recognition and video classification. Code is available at: https://github.com/KaiyuYue/cgnl-network.pytorch.
Fine-grained Video Categorization with Redundancy Reduction Attention
Oct 26, 2018


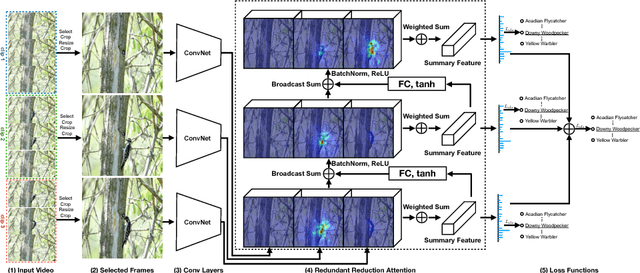
For fine-grained categorization tasks, videos could serve as a better source than static images as videos have a higher chance of containing discriminative patterns. Nevertheless, a video sequence could also contain a lot of redundant and irrelevant frames. How to locate critical information of interest is a challenging task. In this paper, we propose a new network structure, known as Redundancy Reduction Attention (RRA), which learns to focus on multiple discriminative patterns by sup- pressing redundant feature channels. Specifically, it firstly summarizes the video by weight-summing all feature vectors in the feature maps of selected frames with a spatio-temporal soft attention, and then predicts which channels to suppress or to enhance according to this summary with a learned non-linear transform. Suppression is achieved by modulating the feature maps and threshing out weak activations. The updated feature maps are then used in the next iteration. Finally, the video is classified based on multiple summaries. The proposed method achieves out- standing performances in multiple video classification datasets. Further- more, we have collected two large-scale video datasets, YouTube-Birds and YouTube-Cars, for future researches on fine-grained video categorization. The datasets are available at http://www.cs.umd.edu/~chenzhu/fgvc.