 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Video Categorization with Redundancy Reduction Attention
Paper and Code
Oct 26, 2018


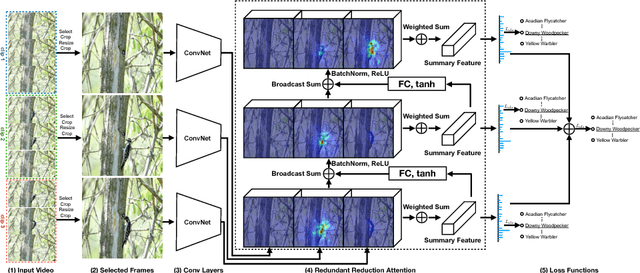
For fine-grained categorization tasks, videos could serve as a better source than static images as videos have a higher chance of containing discriminative patterns. Nevertheless, a video sequence could also contain a lot of redundant and irrelevant frames. How to locate critical information of interest is a challenging task. In this paper, we propose a new network structure, known as Redundancy Reduction Attention (RRA), which learns to focus on multiple discriminative patterns by sup- pressing redundant feature channels. Specifically, it firstly summarizes the video by weight-summing all feature vectors in the feature maps of selected frames with a spatio-temporal soft attention, and then predicts which channels to suppress or to enhance according to this summary with a learned non-linear transform. Suppression is achieved by modulating the feature maps and threshing out weak activations. The updated feature maps are then used in the next iteration. Finally, the video is classified based on multiple summaries. The proposed method achieves out- standing performances in multiple video classification datasets. Further- more, we have collected two large-scale video datasets, YouTube-Birds and YouTube-Cars, for future researches on fine-grained video categorization. The datasets are available at http://www.cs.umd.edu/~chenzhu/fgvc.