 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatching Guided Distillation
Paper and Code

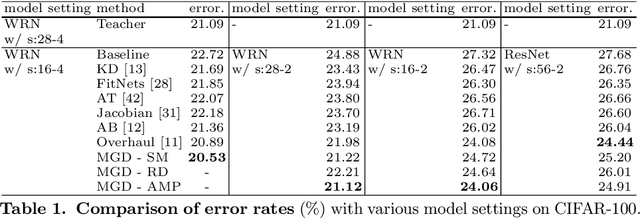
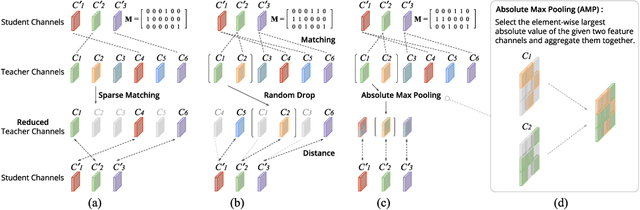
Feature distillation is an effective way to improve the performance for a smaller student model, which has fewer parameters and lower computation cost compared to the larger teacher model. Unfortunately, there is a common obstacle - the gap in semantic feature structure between the intermediate features of teacher and student. The classic scheme prefers to transform intermediate features by adding the adaptation module, such as naive convolutional, attention-based or more complicated one. However, this introduces two problems: a) The adaptation module brings more parameters into training. b) The adaptation module with random initialization or special transformation isn't friendly for distilling a pre-trained student. In this paper, we present Matching Guided Distillation (MGD) as an efficient and parameter-free manner to solve these problems. The key idea of MGD is to pose matching the teacher channels with students' as an assignment problem. We compare three solutions of the assignment problem to reduce channels from teacher features with partial distillation loss. The overall training takes a coordinate-descent approach between two optimization objects - assignments update and parameters update. Since MGD only contains normalization or pooling operations with negligible computation cost, it is flexible to plug into network with other distillation methods.