 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Object Recognition as Next Token Prediction
Dec 04, 2023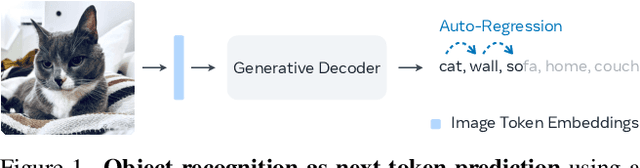
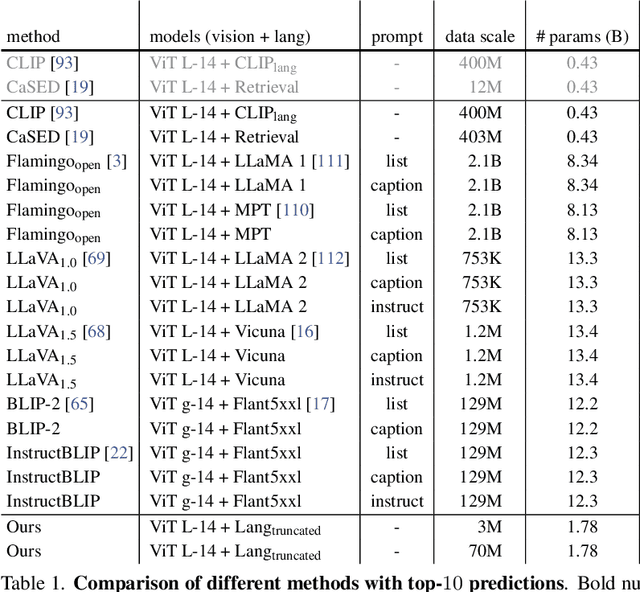
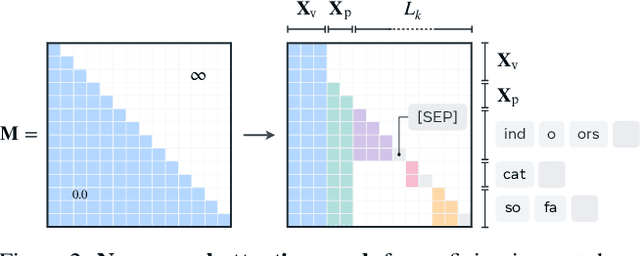

We present an approach to pose object recognition as next token prediction. The idea is to apply a language decoder that auto-regressively predicts the text tokens from image embeddings to form labels. To ground this prediction process in auto-regression, we customize a non-causal attention mask for the decoder, incorporating two key features: modeling tokens from different labels to be independent, and treating image tokens as a prefix. This masking mechanism inspires an efficient method - one-shot sampling - to simultaneously sample tokens of multiple labels in parallel and rank generated labels by their probabilities during inference. To further enhance the efficiency, we propose a simple strategy to construct a compact decoder by simply discarding the intermediate blocks of a pretrained language model. This approach yields a decoder that matches the full model's performance while being notably more efficient. The code is available at https://github.com/kaiyuyue/nxtp
Raising the Bar on the Evaluation of Out-of-Distribution Detection
Sep 24, 2022


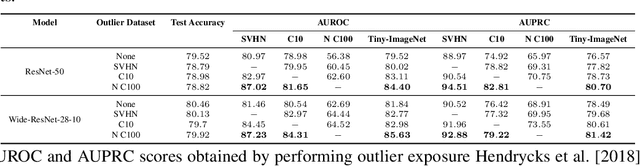
In image classification, a lot of development has happened in detecting out-of-distribution (OoD) data. However, most OoD detection methods are evaluated on a standard set of datasets, arbitrarily different from training data. There is no clear definition of what forms a ``good" OoD dataset. Furthermore, the state-of-the-art OoD detection methods already achieve near perfect results on these standard benchmarks. In this paper, we define 2 categories of OoD data using the subtly different concepts of perceptual/visual and semantic similarity to in-distribution (iD) data. We define Near OoD samples as perceptually similar but semantically different from iD samples, and Shifted samples as points which are visually different but semantically akin to iD data. We then propose a GAN based framework for generating OoD samples from each of these 2 categories, given an iD dataset. Through extensive experiments on MNIST, CIFAR-10/100 and ImageNet, we show that a) state-of-the-art OoD detection methods which perform exceedingly well on conventional benchmarks are significantly less robust to our proposed benchmark. Moreover, b) models performing well on our setup also perform well on conventional real-world OoD detection benchmarks and vice versa, thereby indicating that one might not even need a separate OoD set, to reliably evaluate performance in OoD detection.
Visual Prompt Tuning
Mar 23, 2022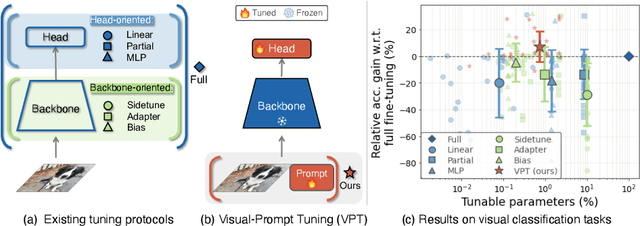
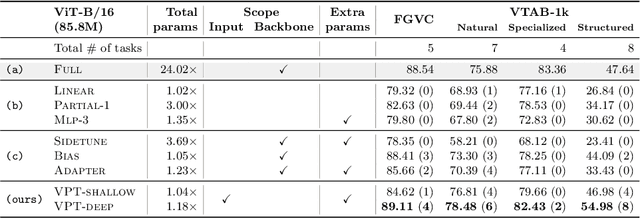
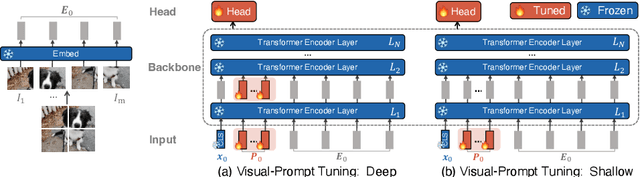
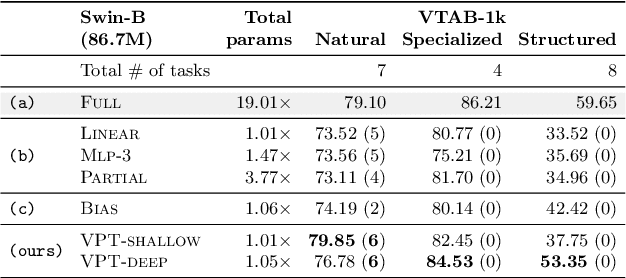
The current modus operandi in adapting pre-trained models involves updating all the backbone parameters, ie, full fine-tuning. This paper introduces Visual Prompt Tuning (VPT) as an efficient and effective alternative to full fine-tuning for large-scale Transformer models in vision. Taking inspiration from recent advances in efficiently tuning large language models, VPT introduces only a small amount (less than 1% of model parameters) of trainable parameters in the input space while keeping the model backbone frozen. Via extensive experiments on a wide variety of downstream recognition tasks, we show that VPT achieves significant performance gains compared to other parameter efficient tuning protocols. Most importantly, VPT even outperforms full fine-tuning in many cases across model capacities and training data scales, while reducing per-task storage cost.
Rethinking Nearest Neighbors for Visual Classification
Dec 17, 2021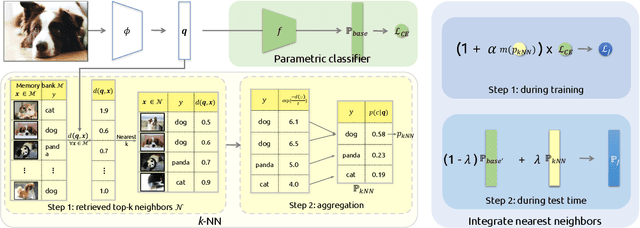
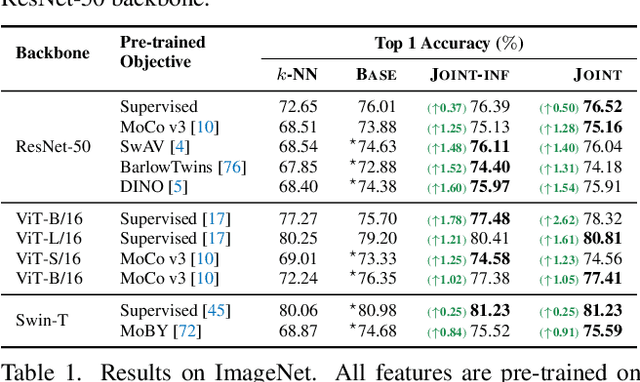
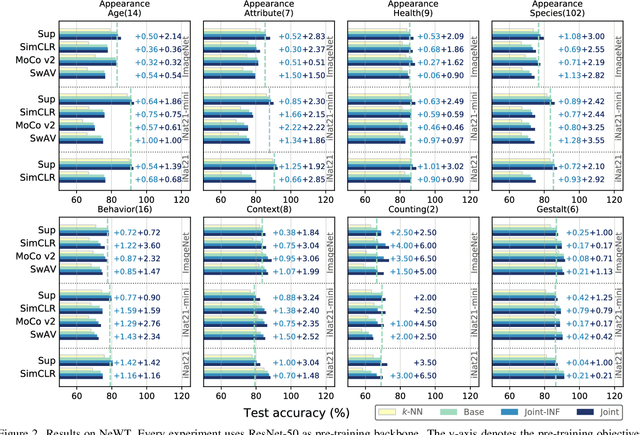
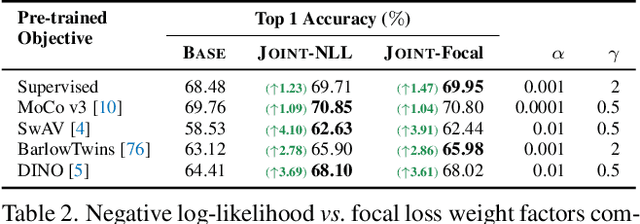
Neural network classifiers have become the de-facto choice for current "pre-train then fine-tune" paradigms of visual classification. In this paper, we investigate k-Nearest-Neighbor (k-NN) classifiers, a classical model-free learning method from the pre-deep learning era, as an augmentation to modern neural network based approaches. As a lazy learning method, k-NN simply aggregates the distance between the test image and top-k neighbors in a training set. We adopt k-NN with pre-trained visual representations produced by either supervised or self-supervised methods in two steps: (1) Leverage k-NN predicted probabilities as indications for easy vs. hard examples during training. (2) Linearly interpolate the k-NN predicted distribution with that of the augmented classifier. Via extensive experiments on a wide range of classification tasks, our study reveals the generality and flexibility of k-NN integration with additional insights: (1) k-NN achieves competitive results, sometimes even outperforming a standard linear classifier. (2) Incorporating k-NN is especially beneficial for tasks where parametric classifiers perform poorly and / or in low-data regimes. We hope these discoveries will encourage people to rethink the role of pre-deep learning, classical methods in computer vision. Our code is available at: https://github.com/KMnP/nn-revisit.
AdaViT: Adaptive Vision Transformers for Efficient Image Recognition
Nov 30, 2021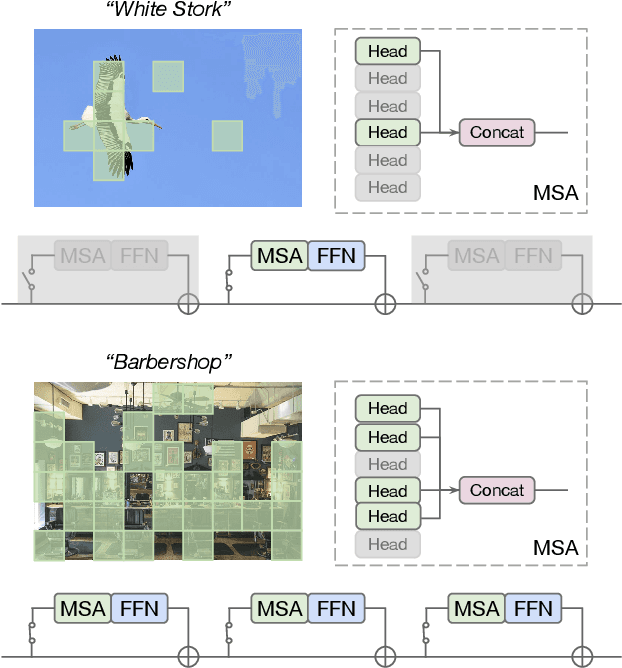
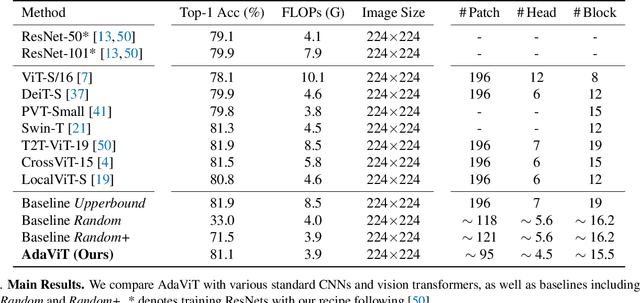
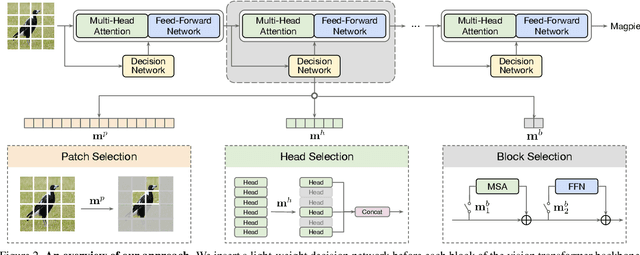

Built on top of self-attention mechanisms, vision transformers have demonstrated remarkable performance on a variety of vision tasks recently. While achieving excellent performance, they still require relatively intensive computational cost that scales up drastically as the numbers of patches, self-attention heads and transformer blocks increase. In this paper, we argue that due to the large variations among images, their need for modeling long-range dependencies between patches differ. To this end, we introduce AdaViT, an adaptive computation framework that learns to derive usage policies on which patches, self-attention heads and transformer blocks to use throughout the backbone on a per-input basis, aiming to improve inference efficiency of vision transformers with a minimal drop of accuracy for image recognition. Optimized jointly with a transformer backbone in an end-to-end manner, a light-weight decision network is attached to the backbone to produce decisions on-the-fly. Extensive experiments on ImageNet demonstrate that our method obtains more than 2x improvement on efficiency compared to state-of-the-art vision transformers with only 0.8% drop of accuracy, achieving good efficiency/accuracy trade-offs conditioned on different computational budgets. We further conduct quantitative and qualitative analysis on learned usage polices and provide more insights on the redundancy in vision transformers.
Unsupervised Deep Metric Learning via Auxiliary Rotation Loss
Nov 16, 2019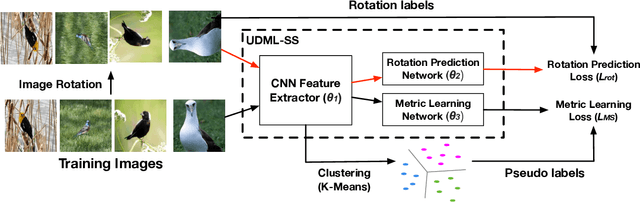
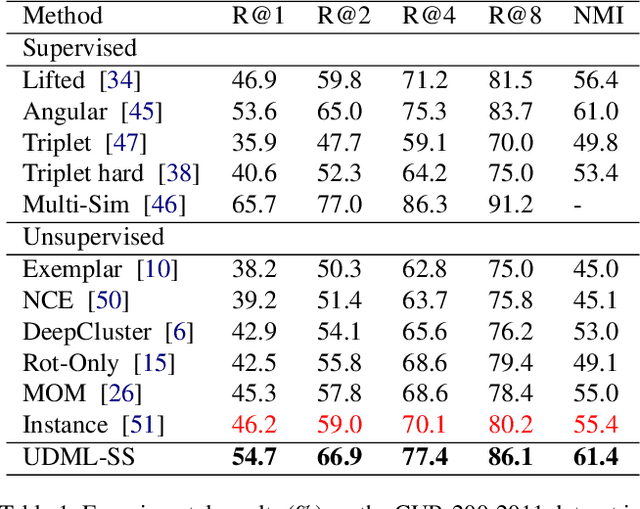

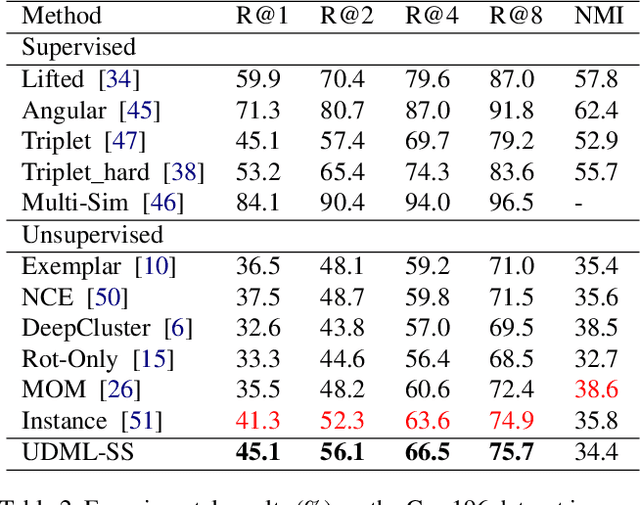
Deep metric learning is an important area due to its applicability to many domains such as image retrieval and person re-identification. The main drawback of such models is the necessity for labeled data. In this work, we propose to generate pseudo-labels for deep metric learning directly from clustering assignment and we introduce unsupervised deep metric learning (UDML) regularized by a self-supervision (SS) task. In particular, we propose to regularize the training process by predicting image rotations. Our method (UDML-SS) jointly learns discriminative embeddings, unsupervised clustering assignments of the embeddings, as well as a self-supervised pretext task. UDML-SS iteratively cluster embeddings using traditional clustering algorithm (e.g., k-means), and sampling training pairs based on the cluster assignment for metric learning, while optimizing self-supervised pretext task in a multi-task fashion. The role of self-supervision is to stabilize the training process and encourages the model to learn meaningful feature representations that are not distorted due to unreliable clustering assignments. The proposed method performs well on standard benchmarks for metric learning, where it outperforms current state-of-the-art approaches by a large margin and it also shows competitive performance with various metric learning loss functions.
An Analysis of Object Embeddings for Image Retrieval
May 28, 2019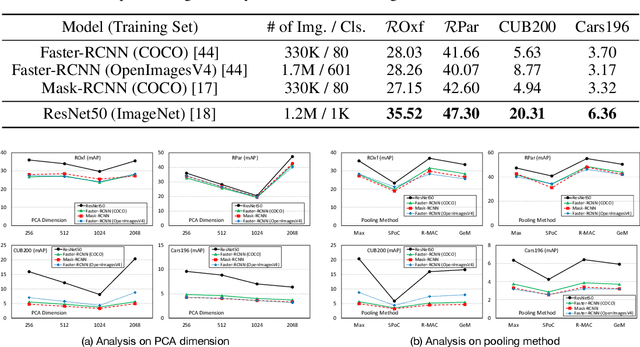

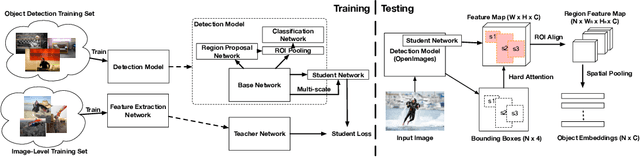
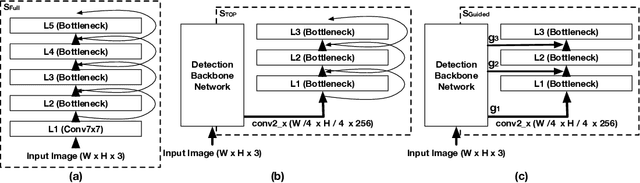
We present an analysis of embeddings extracted from different pre-trained models for content-based image retrieval. Specifically, we study embeddings from image classification and object detection models. We discover that even with additional human annotations such as bounding boxes and segmentation masks, the discriminative power of the embeddings based on modern object detection models is significantly worse than their classification counterparts for the retrieval task. At the same time, our analysis also unearths that object detection model can help retrieval task by acting as a hard attention module for extracting object embeddings that focus on salient region from the convolutional feature map. In order to efficiently extract object embeddings, we introduce a simple guided student-teacher training paradigm for learning discriminative embeddings within the object detection framework. We support our findings with strong experimental results.
Generate, Segment and Replace: Towards Generic Manipulation Segmentation
Nov 24, 2018

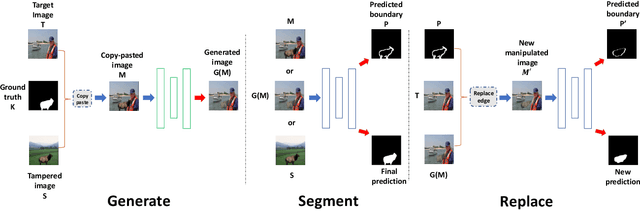
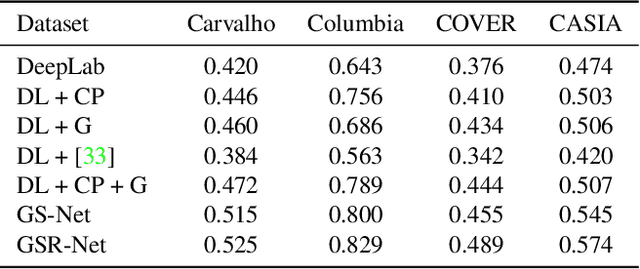
It has been witnessed an emerging demand for image manipulation segmentation to distinguish between fake images produced by advanced photo editing software and authentic ones. In this paper, we describe an approach based on semantic segmentation for detecting image manipulation. The approach consists of three stages. A generation stage generates hard manipulated images from authentic images using a Generative Adversarial Network (GAN) based model by cutting a region out of a training sample, pasting it into an authentic image and then passing the image through a GAN to generate harder true positive tampered region. A segmentation stage and a replacement stage, sharing weights with each other, then collaboratively construct dense predictions of tampered regions. We achieve state-of-the-art performance on four public image manipulation detection benchmarks while maintaining robustness to various attacks.