 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXray-Visual Models: Scaling Vision models on Industry Scale Data
Feb 18, 2026We present Xray-Visual, a unified vision model architecture for large-scale image and video understanding trained on industry-scale social media data. Our model leverages over 15 billion curated image-text pairs and 10 billion video-hashtag pairs from Facebook and Instagram, employing robust data curation pipelines that incorporate balancing and noise suppression strategies to maximize semantic diversity while minimizing label noise. We introduce a three-stage training pipeline that combines self-supervised MAE, semi-supervised hashtag classification, and CLIP-style contrastive learning to jointly optimize image and video modalities. Our architecture builds on a Vision Transformer backbone enhanced with efficient token reorganization (EViT) for improved computational efficiency. Extensive experiments demonstrate that Xray-Visual achieves state-of-the-art performance across diverse benchmarks, including ImageNet for image classification, Kinetics and HMDB51 for video understanding, and MSCOCO for cross-modal retrieval. The model exhibits strong robustness to domain shift and adversarial perturbations. We further demonstrate that integrating large language models as text encoders (LLM2CLIP) significantly enhances retrieval performance and generalization capabilities, particularly in real-world environments. Xray-Visual establishes new benchmarks for scalable, multimodal vision models, while maintaining superior accuracy and computational efficiency.
Learning to Localize Objects Improves Spatial Reasoning in Visual-LLMs
Apr 11, 2024



Integration of Large Language Models (LLMs) into visual domain tasks, resulting in visual-LLMs (V-LLMs), has enabled exceptional performance in vision-language tasks, particularly for visual question answering (VQA). However, existing V-LLMs (e.g. BLIP-2, LLaVA) demonstrate weak spatial reasoning and localization awareness. Despite generating highly descriptive and elaborate textual answers, these models fail at simple tasks like distinguishing a left vs right location. In this work, we explore how image-space coordinate based instruction fine-tuning objectives could inject spatial awareness into V-LLMs. We discover optimal coordinate representations, data-efficient instruction fine-tuning objectives, and pseudo-data generation strategies that lead to improved spatial awareness in V-LLMs. Additionally, our resulting model improves VQA across image and video domains, reduces undesired hallucination, and generates better contextual object descriptions. Experiments across 5 vision-language tasks involving 14 different datasets establish the clear performance improvements achieved by our proposed framework.
Open Vocabulary Semantic Segmentation with Patch Aligned Contrastive Learning
Dec 09, 2022We introduce Patch Aligned Contrastive Learning (PACL), a modified compatibility function for CLIP's contrastive loss, intending to train an alignment between the patch tokens of the vision encoder and the CLS token of the text encoder. With such an alignment, a model can identify regions of an image corresponding to a given text input, and therefore transfer seamlessly to the task of open vocabulary semantic segmentation without requiring any segmentation annotations during training. Using pre-trained CLIP encoders with PACL, we are able to set the state-of-the-art on the task of open vocabulary zero-shot segmentation on 4 different segmentation benchmarks: Pascal VOC, Pascal Context, COCO Stuff and ADE20K. Furthermore, we show that PACL is also applicable to image-level predictions and when used with a CLIP backbone, provides a general improvement in zero-shot classification accuracy compared to CLIP, across a suite of 12 image classification datasets.
Raising the Bar on the Evaluation of Out-of-Distribution Detection
Sep 24, 2022


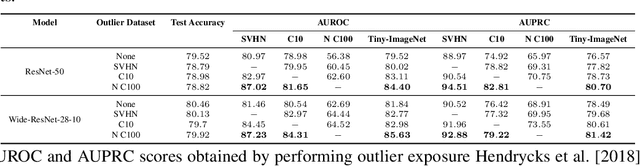
In image classification, a lot of development has happened in detecting out-of-distribution (OoD) data. However, most OoD detection methods are evaluated on a standard set of datasets, arbitrarily different from training data. There is no clear definition of what forms a ``good" OoD dataset. Furthermore, the state-of-the-art OoD detection methods already achieve near perfect results on these standard benchmarks. In this paper, we define 2 categories of OoD data using the subtly different concepts of perceptual/visual and semantic similarity to in-distribution (iD) data. We define Near OoD samples as perceptually similar but semantically different from iD samples, and Shifted samples as points which are visually different but semantically akin to iD data. We then propose a GAN based framework for generating OoD samples from each of these 2 categories, given an iD dataset. Through extensive experiments on MNIST, CIFAR-10/100 and ImageNet, we show that a) state-of-the-art OoD detection methods which perform exceedingly well on conventional benchmarks are significantly less robust to our proposed benchmark. Moreover, b) models performing well on our setup also perform well on conventional real-world OoD detection benchmarks and vice versa, thereby indicating that one might not even need a separate OoD set, to reliably evaluate performance in OoD detection.
Visualizing and Describing Fine-grained Categories as Textures
Jul 02, 2019


We analyze how categories from recent FGVC challenges can be described by their textural content. The motivation is that subtle differences between species of birds or butterflies can often be described in terms of the texture associated with them and that several top-performing networks are inspired by texture-based representations. These representations are characterized by orderless pooling of second-order filter activations such as in bilinear CNNs and the winner of the iNaturalist 2018 challenge. Concretely, for each category we (i) visualize the "maximal images" by obtaining inputs x that maximize the probability of the particular class according to a texture-based deep network, and (ii) automatically describe the maximal images using a set of texture attributes. The models for texture captioning were trained on our ongoing efforts on collecting a dataset of describable textures building on the DTD dataset. These visualizations indicate what aspects of the texture is most discriminative for each category while the descriptions provide a language-based explanation of the same.
Second-order Democratic Aggregation
Aug 22, 2018
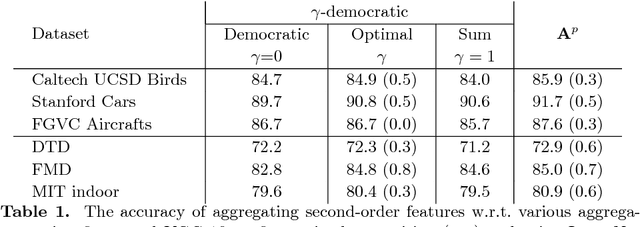
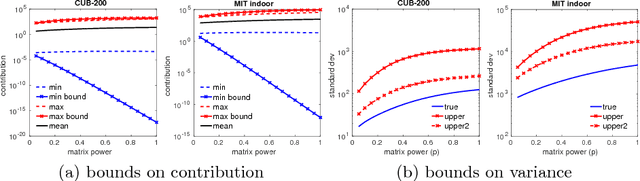

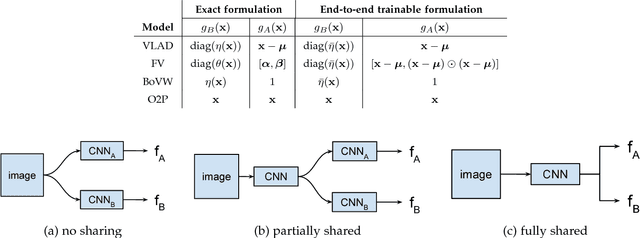
Aggregated second-order features extracted from deep convolutional networks have been shown to be effective for texture generation, fine-grained recognition, material classification, and scene understanding. In this paper, we study a class of orderless aggregation functions designed to minimize interference or equalize contributions in the context of second-order features and we show that they can be computed just as efficiently as their first-order counterparts and they have favorable properties over aggregation by summation. Another line of work has shown that matrix power normalization after aggregation can significantly improve the generalization of second-order representations. We show that matrix power normalization implicitly equalizes contributions during aggregation thus establishing a connection between matrix normalization techniques and prior work on minimizing interference. Based on the analysis we present {\gamma}-democratic aggregators that interpolate between sum ({\gamma}=1) and democratic pooling ({\gamma}=0) outperforming both on several classification tasks. Moreover, unlike power normalization, the {\gamma}-democratic aggregations can be computed in a low dimensional space by sketching that allows the use of very high-dimensional second-order features. This results in a state-of-the-art performance on several datasets.
Improved Bilinear Pooling with CNNs
Jul 21, 2017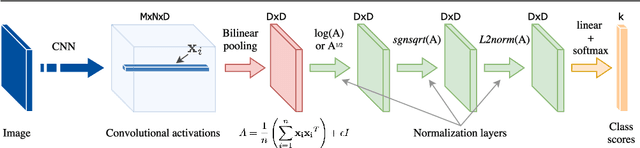
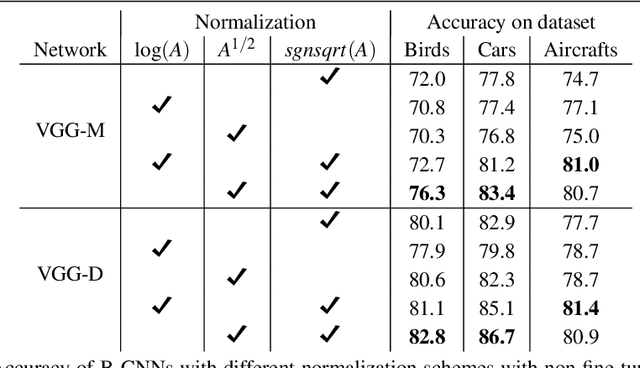
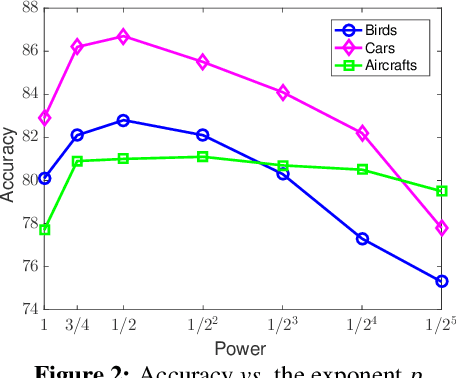

Bilinear pooling of Convolutional Neural Network (CNN) features [22, 23], and their compact variants [10], have been shown to be effective at fine-grained recognition, scene categorization, texture recognition, and visual question-answering tasks among others. The resulting representation captures second-order statistics of convolutional features in a translationally invariant manner. In this paper we investigate various ways of normalizing these statistics to improve their representation power. In particular we find that the matrix square-root normalization offers significant improvements and outperforms alternative schemes such as the matrix logarithm normalization when combined with elementwise square-root and l2 normalization. This improves the accuracy by 2-3% on a range of fine-grained recognition datasets leading to a new state of the art. We also investigate how the accuracy of matrix function computations effect network training and evaluation. In particular we compare against a technique for estimating matrix square-root gradients via solving a Lyapunov equation that is more numerically accurate than computing gradients via a Singular Value Decomposition (SVD). We find that while SVD gradients are numerically inaccurate the overall effect on the final accuracy is negligible once boundary cases are handled carefully. We present an alternative scheme for computing gradients that is faster and yet it offers improvements over the baseline model. Finally we show that the matrix square-root computed approximately using a few Newton iterations is just as accurate for the classification task but allows an order-of-magnitude faster GPU implementation compared to SVD decomposition.
Bilinear CNNs for Fine-grained Visual Recognition
Jun 01, 2017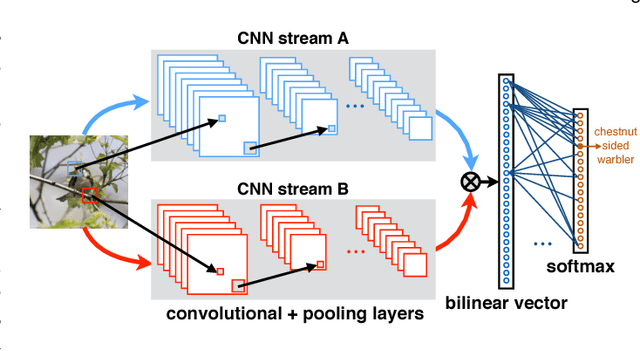
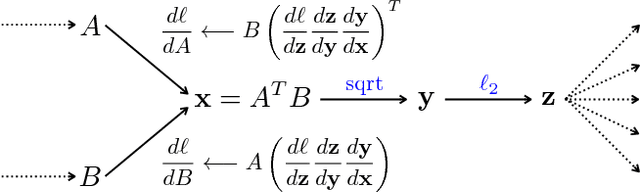
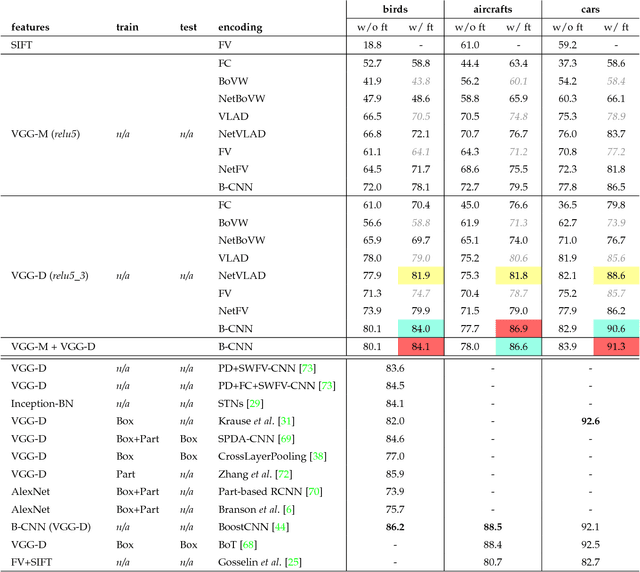
We present a simple and effective architecture for fine-grained visual recognition called Bilinear Convolutional Neural Networks (B-CNNs). These networks represent an image as a pooled outer product of features derived from two CNNs and capture localized feature interactions in a translationally invariant manner. B-CNNs belong to the class of orderless texture representations but unlike prior work they can be trained in an end-to-end manner. Our most accurate model obtains 84.1%, 79.4%, 86.9% and 91.3% per-image accuracy on the Caltech-UCSD birds [67], NABirds [64], FGVC aircraft [42], and Stanford cars [33] dataset respectively and runs at 30 frames-per-second on a NVIDIA Titan X GPU. We then present a systematic analysis of these networks and show that (1) the bilinear features are highly redundant and can be reduced by an order of magnitude in size without significant loss in accuracy, (2) are also effective for other image classification tasks such as texture and scene recognition, and (3) can be trained from scratch on the ImageNet dataset offering consistent improvements over the baseline architecture. Finally, we present visualizations of these models on various datasets using top activations of neural units and gradient-based inversion techniques. The source code for the complete system is available at http://vis-www.cs.umass.edu/bcnn.
Visualizing and Understanding Deep Texture Representations
Apr 12, 2016


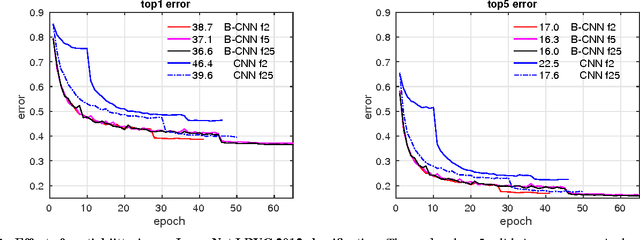
A number of recent approaches have used deep convolutional neural networks (CNNs) to build texture representations. Nevertheless, it is still unclear how these models represent texture and invariances to categorical variations. This work conducts a systematic evaluation of recent CNN-based texture descriptors for recognition and attempts to understand the nature of invariances captured by these representations. First we show that the recently proposed bilinear CNN model [25] is an excellent general-purpose texture descriptor and compares favorably to other CNN-based descriptors on various texture and scene recognition benchmarks. The model is translationally invariant and obtains better accuracy on the ImageNet dataset without requiring spatial jittering of data compared to corresponding models trained with spatial jittering. Based on recent work [13, 28] we propose a technique to visualize pre-images, providing a means for understanding categorical properties that are captured by these representations. Finally, we show preliminary results on how a unified parametric model of texture analysis and synthesis can be used for attribute-based image manipulation, e.g. to make an image more swirly, honeycombed, or knitted. The source code and additional visualizations are available at http://vis-www.cs.umass.edu/texture
One-to-many face recognition with bilinear CNNs
Mar 28, 2016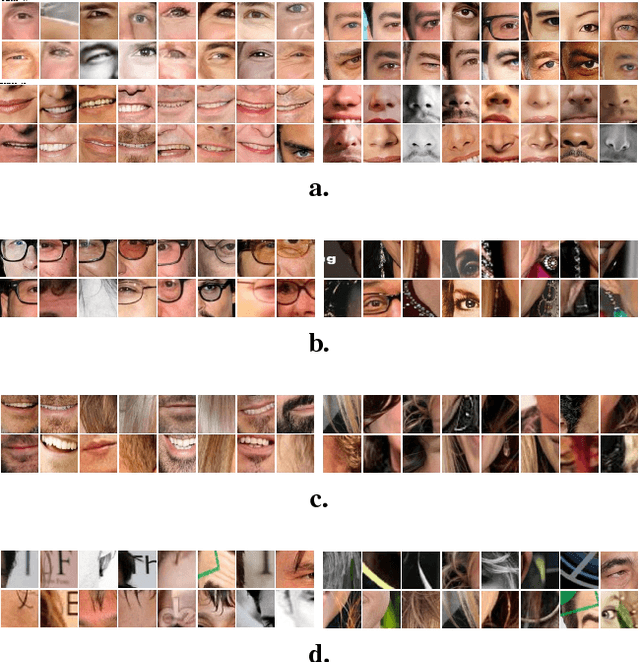
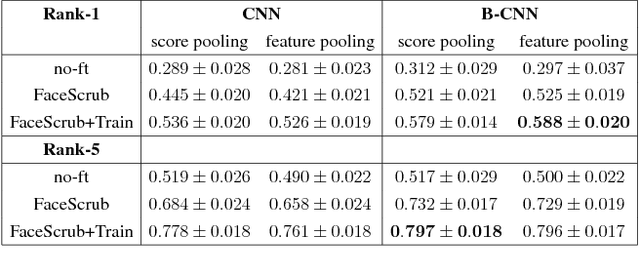


The recent explosive growth in convolutional neural network (CNN) research has produced a variety of new architectures for deep learning. One intriguing new architecture is the bilinear CNN (B-CNN), which has shown dramatic performance gains on certain fine-grained recognition problems [15]. We apply this new CNN to the challenging new face recognition benchmark, the IARPA Janus Benchmark A (IJB-A) [12]. It features faces from a large number of identities in challenging real-world conditions. Because the face images were not identified automatically using a computerized face detection system, it does not have the bias inherent in such a database. We demonstrate the performance of the B-CNN model beginning from an AlexNet-style network pre-trained on ImageNet. We then show results for fine-tuning using a moderate-sized and public external database, FaceScrub [17]. We also present results with additional fine-tuning on the limited training data provided by the protocol. In each case, the fine-tuned bilinear model shows substantial improvements over the standard CNN. Finally, we demonstrate how a standard CNN pre-trained on a large face database, the recently released VGG-Face model [20], can be converted into a B-CNN without any additional feature training. This B-CNN improves upon the CNN performance on the IJB-A benchmark, achieving 89.5% rank-1 recall.