 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBilinear CNNs for Fine-grained Visual Recognition
Paper and Code
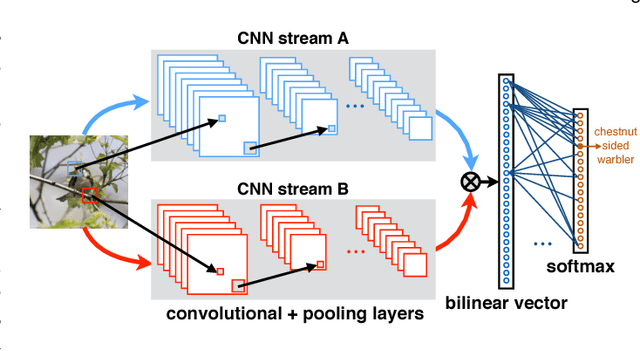
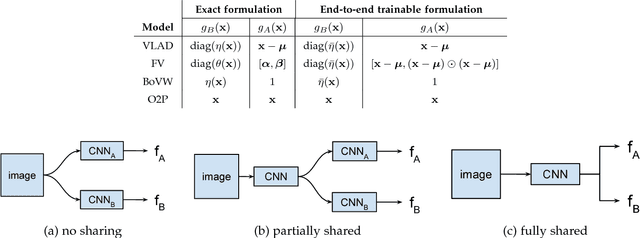
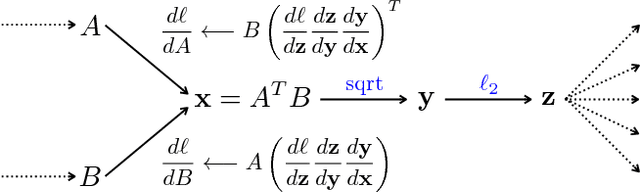
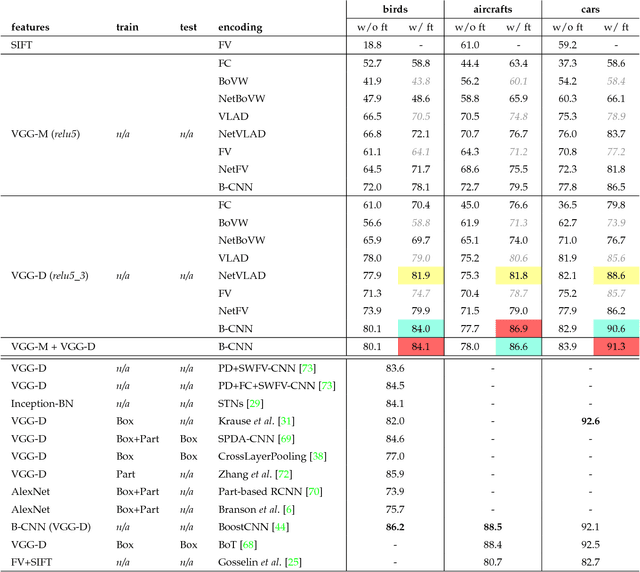
We present a simple and effective architecture for fine-grained visual recognition called Bilinear Convolutional Neural Networks (B-CNNs). These networks represent an image as a pooled outer product of features derived from two CNNs and capture localized feature interactions in a translationally invariant manner. B-CNNs belong to the class of orderless texture representations but unlike prior work they can be trained in an end-to-end manner. Our most accurate model obtains 84.1%, 79.4%, 86.9% and 91.3% per-image accuracy on the Caltech-UCSD birds [67], NABirds [64], FGVC aircraft [42], and Stanford cars [33] dataset respectively and runs at 30 frames-per-second on a NVIDIA Titan X GPU. We then present a systematic analysis of these networks and show that (1) the bilinear features are highly redundant and can be reduced by an order of magnitude in size without significant loss in accuracy, (2) are also effective for other image classification tasks such as texture and scene recognition, and (3) can be trained from scratch on the ImageNet dataset offering consistent improvements over the baseline architecture. Finally, we present visualizations of these models on various datasets using top activations of neural units and gradient-based inversion techniques. The source code for the complete system is available at http://vis-www.cs.umass.edu/bcnn.