 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Seeking for Robust Decision Making under Partial Observability
Oct 02, 2025Explicit information seeking is essential to human problem-solving in practical environments characterized by incomplete information and noisy dynamics. When the true environmental state is not directly observable, humans seek information to update their internal dynamics and inform future decision-making. Although existing Large Language Model (LLM) planning agents have addressed observational uncertainty, they often overlook discrepancies between their internal dynamics and the actual environment. We introduce Information Seeking Decision Planner (InfoSeeker), an LLM decision-making framework that integrates task-oriented planning with information seeking to align internal dynamics and make optimal decisions under uncertainty in both agent observations and environmental dynamics. InfoSeeker prompts an LLM to actively gather information by planning actions to validate its understanding, detect environmental changes, or test hypotheses before generating or revising task-oriented plans. To evaluate InfoSeeker, we introduce a novel benchmark suite featuring partially observable environments with incomplete observations and uncertain dynamics. Experiments demonstrate that InfoSeeker achieves a 74% absolute performance gain over prior methods without sacrificing sample efficiency. Moreover, InfoSeeker generalizes across LLMs and outperforms baselines on established benchmarks such as robotic manipulation and web navigation. These findings underscore the importance of tightly integrating planning and information seeking for robust behavior in partially observable environments. The project page is available at https://infoseekerllm.github.io
See, Point, Fly: A Learning-Free VLM Framework for Universal Unmanned Aerial Navigation
Sep 26, 2025We present See, Point, Fly (SPF), a training-free aerial vision-and-language navigation (AVLN) framework built atop vision-language models (VLMs). SPF is capable of navigating to any goal based on any type of free-form instructions in any kind of environment. In contrast to existing VLM-based approaches that treat action prediction as a text generation task, our key insight is to consider action prediction for AVLN as a 2D spatial grounding task. SPF harnesses VLMs to decompose vague language instructions into iterative annotation of 2D waypoints on the input image. Along with the predicted traveling distance, SPF transforms predicted 2D waypoints into 3D displacement vectors as action commands for UAVs. Moreover, SPF also adaptively adjusts the traveling distance to facilitate more efficient navigation. Notably, SPF performs navigation in a closed-loop control manner, enabling UAVs to follow dynamic targets in dynamic environments. SPF sets a new state of the art in DRL simulation benchmark, outperforming the previous best method by an absolute margin of 63%. In extensive real-world evaluations, SPF outperforms strong baselines by a large margin. We also conduct comprehensive ablation studies to highlight the effectiveness of our design choice. Lastly, SPF shows remarkable generalization to different VLMs. Project page: https://spf-web.pages.dev
3D Diffuser Actor: Policy Diffusion with 3D Scene Representations
Feb 16, 2024We marry diffusion policies and 3D scene representations for robot manipulation. Diffusion policies learn the action distribution conditioned on the robot and environment state using conditional diffusion models. They have recently shown to outperform both deterministic and alternative state-conditioned action distribution learning methods. 3D robot policies use 3D scene feature representations aggregated from a single or multiple camera views using sensed depth. They have shown to generalize better than their 2D counterparts across camera viewpoints. We unify these two lines of work and present 3D Diffuser Actor, a neural policy architecture that, given a language instruction, builds a 3D representation of the visual scene and conditions on it to iteratively denoise 3D rotations and translations for the robot's end-effector. At each denoising iteration, our model represents end-effector pose estimates as 3D scene tokens and predicts the 3D translation and rotation error for each of them, by featurizing them using 3D relative attention to other 3D visual and language tokens. 3D Diffuser Actor sets a new state-of-the-art on RLBench with an absolute performance gain of 16.3% over the current SOTA on a multi-view setup and an absolute gain of 13.1% on a single-view setup. On the CALVIN benchmark, it outperforms the current SOTA in the setting of zero-shot unseen scene generalization by being able to successfully run 0.2 more tasks, a 7% relative increase. It also works in the real world from a handful of demonstrations. We ablate our model's architectural design choices, such as 3D scene featurization and 3D relative attentions, and show they all help generalization. Our results suggest that 3D scene representations and powerful generative modeling are keys to efficient robot learning from demonstrations.
Diffusion-ES: Gradient-free Planning with Diffusion for Autonomous Driving and Zero-Shot Instruction Following
Feb 09, 2024



Diffusion models excel at modeling complex and multimodal trajectory distributions for decision-making and control. Reward-gradient guided denoising has been recently proposed to generate trajectories that maximize both a differentiable reward function and the likelihood under the data distribution captured by a diffusion model. Reward-gradient guided denoising requires a differentiable reward function fitted to both clean and noised samples, limiting its applicability as a general trajectory optimizer. In this paper, we propose DiffusionES, a method that combines gradient-free optimization with trajectory denoising to optimize black-box non-differentiable objectives while staying in the data manifold. Diffusion-ES samples trajectories during evolutionary search from a diffusion model and scores them using a black-box reward function. It mutates high-scoring trajectories using a truncated diffusion process that applies a small number of noising and denoising steps, allowing for much more efficient exploration of the solution space. We show that DiffusionES achieves state-of-the-art performance on nuPlan, an established closed-loop planning benchmark for autonomous driving. Diffusion-ES outperforms existing sampling-based planners, reactive deterministic or diffusion-based policies, and reward-gradient guidance. Additionally, we show that unlike prior guidance methods, our method can optimize non-differentiable language-shaped reward functions generated by few-shot LLM prompting. When guided by a human teacher that issues instructions to follow, our method can generate novel, highly complex behaviors, such as aggressive lane weaving, which are not present in the training data. This allows us to solve the hardest nuPlan scenarios which are beyond the capabilities of existing trajectory optimization methods and driving policies.
Diffusion-TTA: Test-time Adaptation of Discriminative Models via Generative Feedback
Nov 29, 2023



The advancements in generative modeling, particularly the advent of diffusion models, have sparked a fundamental question: how can these models be effectively used for discriminative tasks? In this work, we find that generative models can be great test-time adapters for discriminative models. Our method, Diffusion-TTA, adapts pre-trained discriminative models such as image classifiers, segmenters and depth predictors, to each unlabelled example in the test set using generative feedback from a diffusion model. We achieve this by modulating the conditioning of the diffusion model using the output of the discriminative model. We then maximize the image likelihood objective by backpropagating the gradients to discriminative model's parameters. We show Diffusion-TTA significantly enhances the accuracy of various large-scale pre-trained discriminative models, such as, ImageNet classifiers, CLIP models, image pixel labellers and image depth predictors. Diffusion-TTA outperforms existing test-time adaptation methods, including TTT-MAE and TENT, and particularly shines in online adaptation setups, where the discriminative model is continually adapted to each example in the test set. We provide access to code, results, and visualizations on our website: https://diffusion-tta.github.io/.
CAST: Concurrent Recognition and Segmentation with Adaptive Segment Tokens
Oct 04, 2022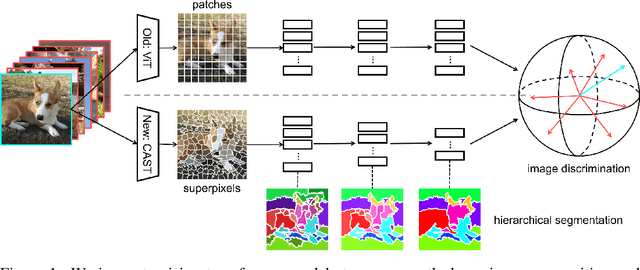
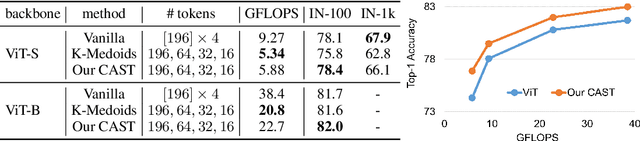
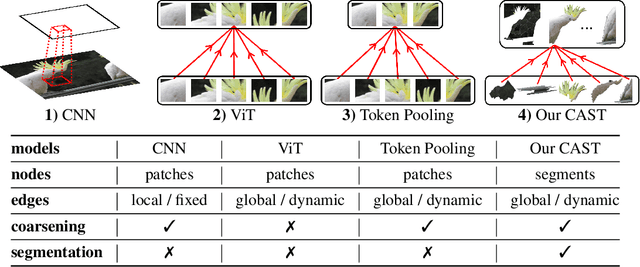

Recognizing an image and segmenting it into coherent regions are often treated as separate tasks. Human vision, however, has a general sense of segmentation hierarchy before recognition occurs. We are thus inspired to learn image recognition with hierarchical image segmentation based entirely on unlabeled images. Our insight is to learn fine-to-coarse features concurrently at superpixels, segments, and full image levels, enforcing consistency and goodness of feature induced segmentations while maximizing discrimination among image instances. Our model innovates vision transformers on three aspects. 1) We use adaptive segment tokens instead of fixed-shape patch tokens. 2) We create a token hierarchy by inserting graph pooling between transformer blocks, naturally producing consistent multi-scale segmentations while increasing the segment size and reducing the number of tokens. 3) We produce hierarchical image segmentation for free while training for recognition by maximizing image-wise discrimination. Our work delivers the first concurrent recognition and hierarchical segmentation model without any supervision. Validated on ImageNet and PASCAL VOC, it achieves better recognition and segmentation with higher computational efficiency.
Unsupervised Hierarchical Semantic Segmentation with Multiview Cosegmentation and Clustering Transformers
Apr 25, 2022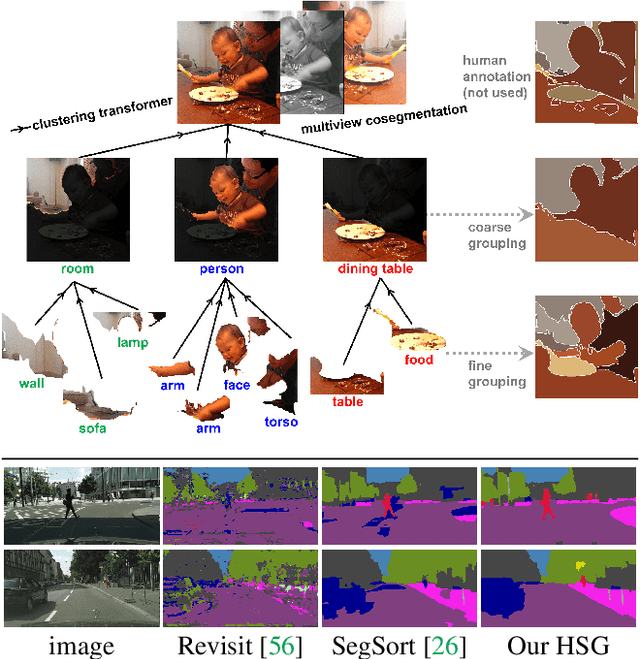
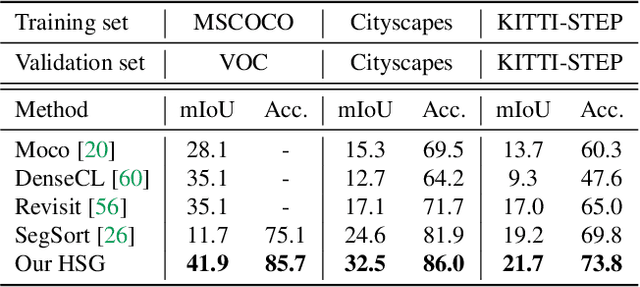
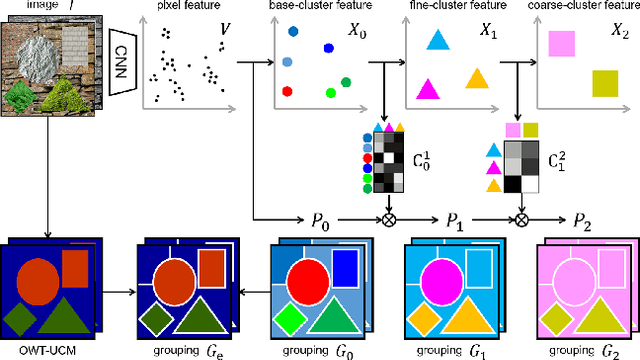

Unsupervised semantic segmentation aims to discover groupings within and across images that capture object and view-invariance of a category without external supervision. Grouping naturally has levels of granularity, creating ambiguity in unsupervised segmentation. Existing methods avoid this ambiguity and treat it as a factor outside modeling, whereas we embrace it and desire hierarchical grouping consistency for unsupervised segmentation. We approach unsupervised segmentation as a pixel-wise feature learning problem. Our idea is that a good representation shall reveal not just a particular level of grouping, but any level of grouping in a consistent and predictable manner. We enforce spatial consistency of grouping and bootstrap feature learning with co-segmentation among multiple views of the same image, and enforce semantic consistency across the grouping hierarchy with clustering transformers between coarse- and fine-grained features. We deliver the first data-driven unsupervised hierarchical semantic segmentation method called Hierarchical Segment Grouping (HSG). Capturing visual similarity and statistical co-occurrences, HSG also outperforms existing unsupervised segmentation methods by a large margin on five major object- and scene-centric benchmarks. Our code is publicly available at https://github.com/twke18/HSG .
Universal Weakly Supervised Segmentation by Pixel-to-Segment Contrastive Learning
May 11, 2021
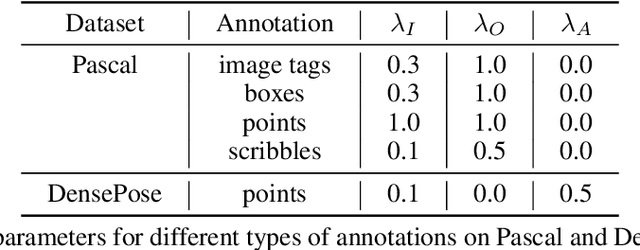
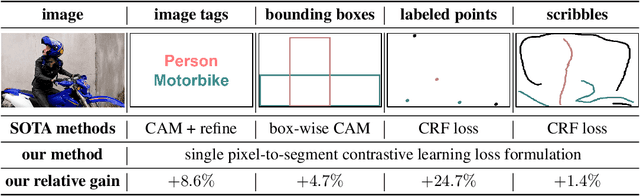
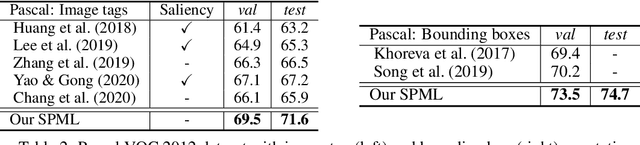
Weakly supervised segmentation requires assigning a label to every pixel based on training instances with partial annotations such as image-level tags, object bounding boxes, labeled points and scribbles. This task is challenging, as coarse annotations (tags, boxes) lack precise pixel localization whereas sparse annotations (points, scribbles) lack broad region coverage. Existing methods tackle these two types of weak supervision differently: Class activation maps are used to localize coarse labels and iteratively refine the segmentation model, whereas conditional random fields are used to propagate sparse labels to the entire image. We formulate weakly supervised segmentation as a semi-supervised metric learning problem, where pixels of the same (different) semantics need to be mapped to the same (distinctive) features. We propose 4 types of contrastive relationships between pixels and segments in the feature space, capturing low-level image similarity, semantic annotation, co-occurrence, and feature affinity They act as priors; the pixel-wise feature can be learned from training images with any partial annotations in a data-driven fashion. In particular, unlabeled pixels in training images participate not only in data-driven grouping within each image, but also in discriminative feature learning within and across images. We deliver a universal weakly supervised segmenter with significant gains on Pascal VOC and DensePose. Our code is publicly available at https://github.com/twke18/SPML.
Adaptive Affinity Fields for Semantic Segmentation
Aug 21, 2018

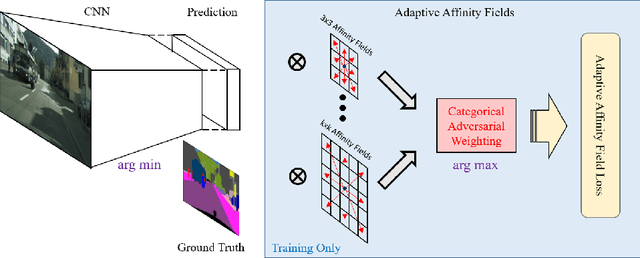
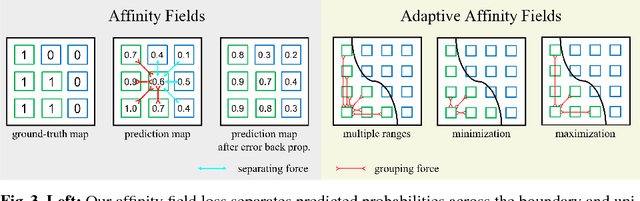
Semantic segmentation has made much progress with increasingly powerful pixel-wise classifiers and incorporating structural priors via Conditional Random Fields (CRF) or Generative Adversarial Networks (GAN). We propose a simpler alternative that learns to verify the spatial structure of segmentation during training only. Unlike existing approaches that enforce semantic labels on individual pixels and match labels between neighbouring pixels, we propose the concept of Adaptive Affinity Fields (AAF) to capture and match the semantic relations between neighbouring pixels in the label space. We use adversarial learning to select the optimal affinity field size for each semantic category. It is formulated as a minimax problem, optimizing our segmentation neural network in a best worst-case learning scenario. AAF is versatile for representing structures as a collection of pixel-centric relations, easier to train than GAN and more efficient than CRF without run-time inference. Our extensive evaluations on PASCAL VOC 2012, Cityscapes, and GTA5 datasets demonstrate its above-par segmentation performance and robust generalization across domains.
Adversarial Structure Matching Loss for Image Segmentation
May 18, 2018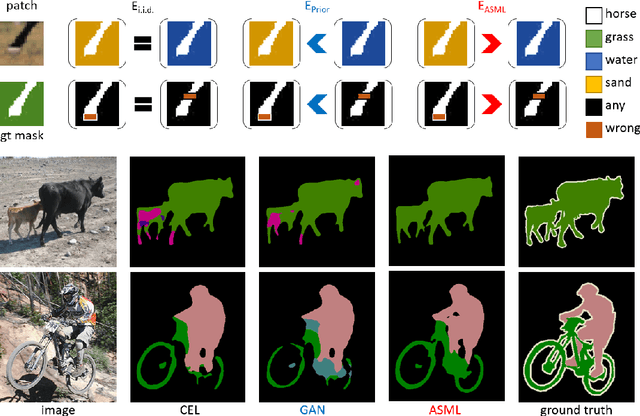
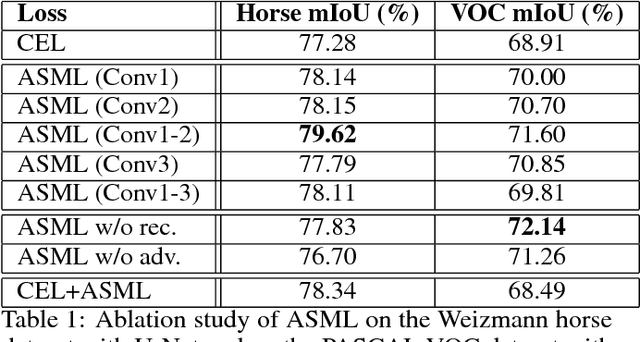
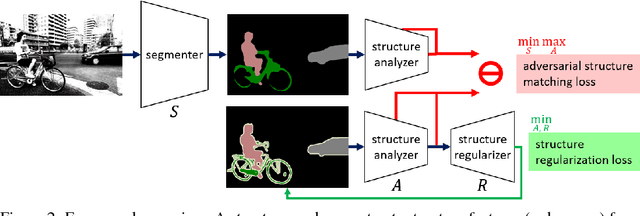
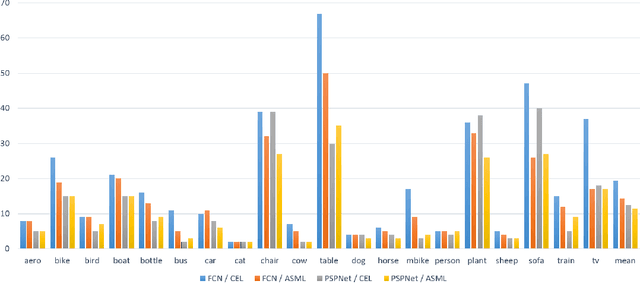
The per-pixel cross-entropy loss (CEL) has been widely used in structured output prediction tasks as a spatial extension of generic image classification. However, its i.i.d. assumption neglects the structural regularity present in natural images. Various attempts have been made to incorporate structural reasoning mostly through structure priors in a cooperative way where co-occuring patterns are encouraged. We, on the other hand, approach this problem from an opposing angle and propose a new framework for training such structured prediction networks via an adversarial process, in which we train a structure analyzer that provides the supervisory signals, the adversarial structure matching loss (ASML). The structure analyzer is trained to maximize ASML, or to exaggerate recurring structural mistakes usually among co-occurring patterns. On the contrary, the structured output prediction network is trained to reduce those mistakes and is thus enabled to distinguish fine-grained structures. As a result, training structured output prediction networks using ASML reduces contextual confusion among objects and improves boundary localization. We demonstrate that ASML outperforms its counterpart CEL especially in context and boundary aspects on figure-ground segmentation and semantic segmentation tasks with various base architectures, such as FCN, U-Net, DeepLab, and PSPNet.