 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoCausal: How Far is Video Generation from World Model? A Causality Perspective
May 28, 2026As video diffusion models (VDMs) advance toward world models, a key question arises: do they truly understand causality, or merely overfit to statistical temporal patterns? Existing benchmarks mostly rely on synthetic data, limiting real-world generalization due to the sim-to-real gap. We present YoCausal, a two-level benchmark inspired by the Violation of Expectation (VoE) paradigm from cognitive science. By temporally reversing real-world videos at zero cost as natural counterfactual samples, YoCausal establishes an arbitrarily extensible evaluation protocol. Level 1 introduces the Reverse Surprise Index (RSI), quantifying arrow-of-time perception via denoising loss. Level 2 introduces the Causality Cognition Index (CCI), which leverages a VLM to stratify datasets into causal and non-causal subsets, disentangling genuine causal reasoning from temporal bias. Evaluation of 13 state-of-the-art VDMs reveals that perceiving the arrow of time does not imply understanding causality, and a significant gap persists relative to human-level causal cognition.
Pantheon360: Taming Digital Twin Generation via 3D-Aware 360° Video Diffusion
May 25, 2026Generating complete digital twins from videos requires precise camera control, global scene coverage, and strict spatial-temporal consistency constraints that remain challenging for perspective video generators due to their limited field of view (FoV). Their narrow FoV forces long or multi-view trajectories, amplifying cross-view inconsistency and temporal drift. We argue that 360° video generation offers a natural solution: panoramic coverage simplifies trajectory design and provides a strong global context for maintaining coherence. We introduce Pantheon360: Taming Digital Twin Generation via 3D-Aware 360° Video Diffusion, a controllable 360° video generation framework that synthesizes high-fidelity videos from sparse 360° inputs. The key idea is an explicit 3D Cache, reconstructed from the input, which serves as a geometric scaffold for any user-defined camera path. This allows the diffusion model to focus on photorealistic texture refinement while the 3D Cache enforces global geometric consistency. Experiments show that Pantheon360 achieves superior visual quality and unmatched geometric coherence, enabling reliable and flexible 360° scene generation for downstream simulation and digital-twin applications.
See, Point, Fly: A Learning-Free VLM Framework for Universal Unmanned Aerial Navigation
Sep 26, 2025



We present See, Point, Fly (SPF), a training-free aerial vision-and-language navigation (AVLN) framework built atop vision-language models (VLMs). SPF is capable of navigating to any goal based on any type of free-form instructions in any kind of environment. In contrast to existing VLM-based approaches that treat action prediction as a text generation task, our key insight is to consider action prediction for AVLN as a 2D spatial grounding task. SPF harnesses VLMs to decompose vague language instructions into iterative annotation of 2D waypoints on the input image. Along with the predicted traveling distance, SPF transforms predicted 2D waypoints into 3D displacement vectors as action commands for UAVs. Moreover, SPF also adaptively adjusts the traveling distance to facilitate more efficient navigation. Notably, SPF performs navigation in a closed-loop control manner, enabling UAVs to follow dynamic targets in dynamic environments. SPF sets a new state of the art in DRL simulation benchmark, outperforming the previous best method by an absolute margin of 63%. In extensive real-world evaluations, SPF outperforms strong baselines by a large margin. We also conduct comprehensive ablation studies to highlight the effectiveness of our design choice. Lastly, SPF shows remarkable generalization to different VLMs. Project page: https://spf-web.pages.dev
AuraFusion360: Augmented Unseen Region Alignment for Reference-based 360° Unbounded Scene Inpainting
Feb 07, 2025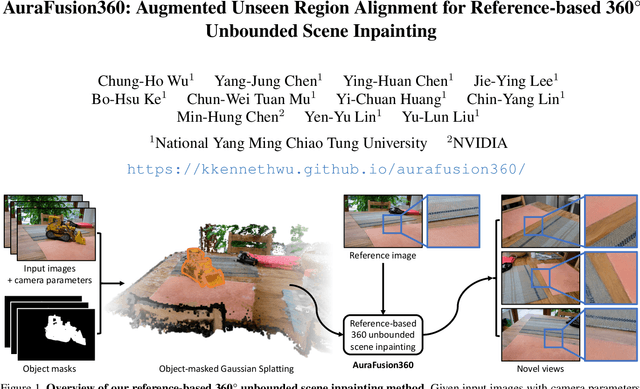
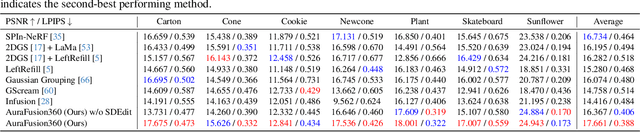

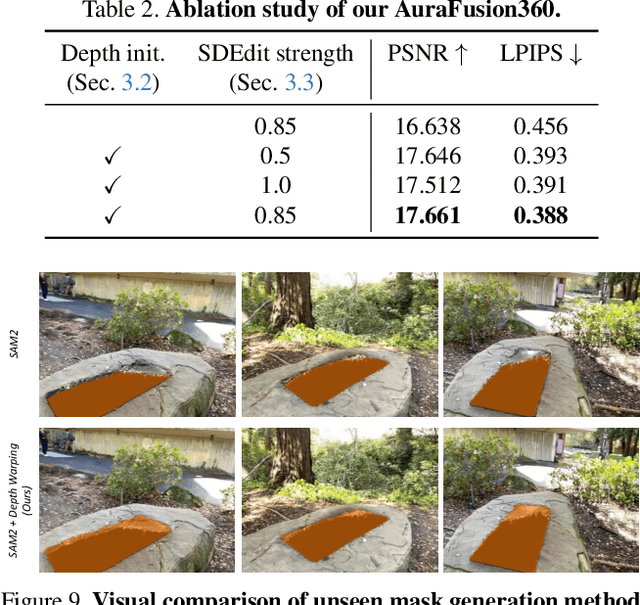
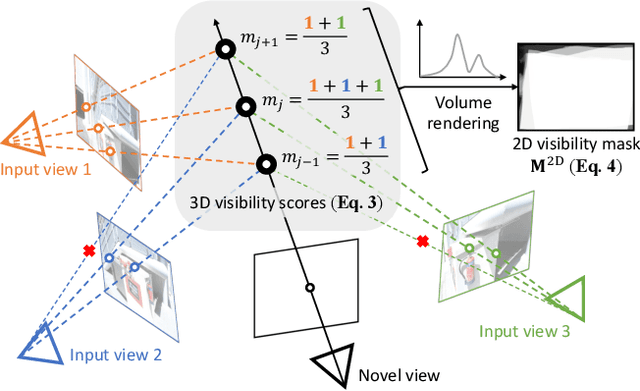
Three-dimensional scene inpainting is crucial for applications from virtual reality to architectural visualization, yet existing methods struggle with view consistency and geometric accuracy in 360{\deg} unbounded scenes. We present AuraFusion360, a novel reference-based method that enables high-quality object removal and hole filling in 3D scenes represented by Gaussian Splatting. Our approach introduces (1) depth-aware unseen mask generation for accurate occlusion identification, (2) Adaptive Guided Depth Diffusion, a zero-shot method for accurate initial point placement without requiring additional training, and (3) SDEdit-based detail enhancement for multi-view coherence. We also introduce 360-USID, the first comprehensive dataset for 360{\deg} unbounded scene inpainting with ground truth. Extensive experiments demonstrate that AuraFusion360 significantly outperforms existing methods, achieving superior perceptual quality while maintaining geometric accuracy across dramatic viewpoint changes. See our project page for video results and the dataset at https://kkennethwu.github.io/aurafusion360/.
SpectroMotion: Dynamic 3D Reconstruction of Specular Scenes
Oct 22, 2024



We present SpectroMotion, a novel approach that combines 3D Gaussian Splatting (3DGS) with physically-based rendering (PBR) and deformation fields to reconstruct dynamic specular scenes. Previous methods extending 3DGS to model dynamic scenes have struggled to accurately represent specular surfaces. Our method addresses this limitation by introducing a residual correction technique for accurate surface normal computation during deformation, complemented by a deformable environment map that adapts to time-varying lighting conditions. We implement a coarse-to-fine training strategy that significantly enhances both scene geometry and specular color prediction. We demonstrate that our model outperforms prior methods for view synthesis of scenes containing dynamic specular objects and that it is the only existing 3DGS method capable of synthesizing photorealistic real-world dynamic specular scenes, outperforming state-of-the-art methods in rendering complex, dynamic, and specular scenes.
BoostMVSNeRFs: Boosting MVS-based NeRFs to Generalizable View Synthesis in Large-scale Scenes
Jul 22, 2024


While Neural Radiance Fields (NeRFs) have demonstrated exceptional quality, their protracted training duration remains a limitation. Generalizable and MVS-based NeRFs, although capable of mitigating training time, often incur tradeoffs in quality. This paper presents a novel approach called BoostMVSNeRFs to enhance the rendering quality of MVS-based NeRFs in large-scale scenes. We first identify limitations in MVS-based NeRF methods, such as restricted viewport coverage and artifacts due to limited input views. Then, we address these limitations by proposing a new method that selects and combines multiple cost volumes during volume rendering. Our method does not require training and can adapt to any MVS-based NeRF methods in a feed-forward fashion to improve rendering quality. Furthermore, our approach is also end-to-end trainable, allowing fine-tuning on specific scenes. We demonstrate the effectiveness of our method through experiments on large-scale datasets, showing significant rendering quality improvements in large-scale scenes and unbounded outdoor scenarios. We release the source code of BoostMVSNeRFs at https://su-terry.github.io/BoostMVSNeRFs/.