 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Structure Matching Loss for Image Segmentation
Paper and Code
May 18, 2018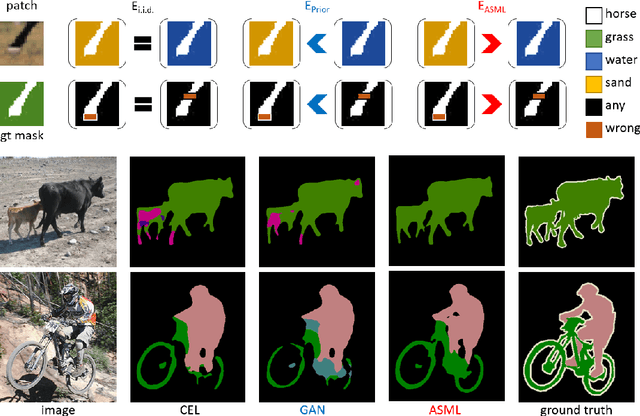
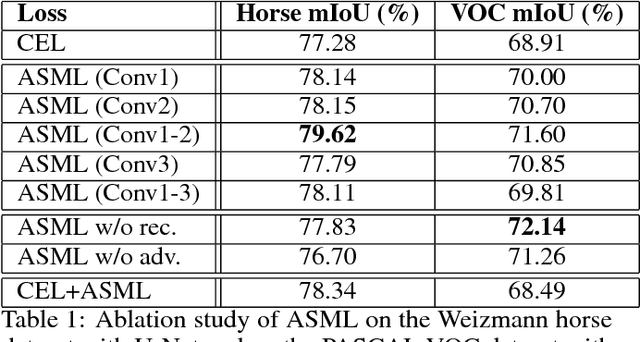
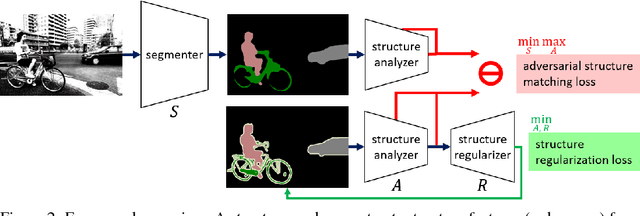
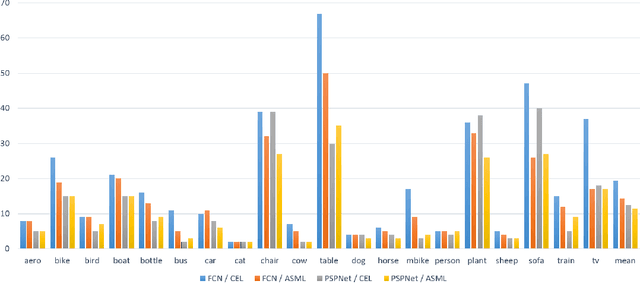
The per-pixel cross-entropy loss (CEL) has been widely used in structured output prediction tasks as a spatial extension of generic image classification. However, its i.i.d. assumption neglects the structural regularity present in natural images. Various attempts have been made to incorporate structural reasoning mostly through structure priors in a cooperative way where co-occuring patterns are encouraged. We, on the other hand, approach this problem from an opposing angle and propose a new framework for training such structured prediction networks via an adversarial process, in which we train a structure analyzer that provides the supervisory signals, the adversarial structure matching loss (ASML). The structure analyzer is trained to maximize ASML, or to exaggerate recurring structural mistakes usually among co-occurring patterns. On the contrary, the structured output prediction network is trained to reduce those mistakes and is thus enabled to distinguish fine-grained structures. As a result, training structured output prediction networks using ASML reduces contextual confusion among objects and improves boundary localization. We demonstrate that ASML outperforms its counterpart CEL especially in context and boundary aspects on figure-ground segmentation and semantic segmentation tasks with various base architectures, such as FCN, U-Net, DeepLab, and PSPNet.