 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAST: Concurrent Recognition and Segmentation with Adaptive Segment Tokens
Paper and Code
Oct 04, 2022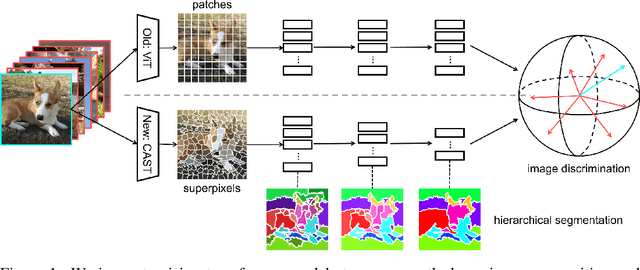
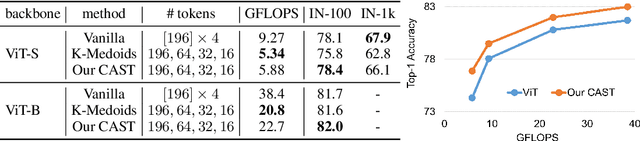
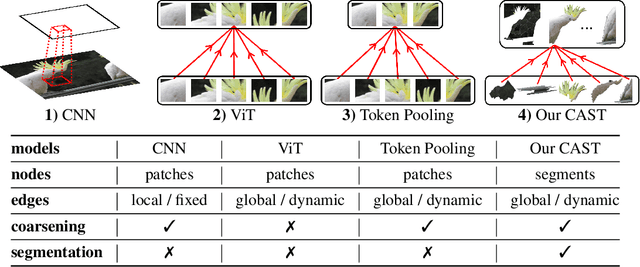

Recognizing an image and segmenting it into coherent regions are often treated as separate tasks. Human vision, however, has a general sense of segmentation hierarchy before recognition occurs. We are thus inspired to learn image recognition with hierarchical image segmentation based entirely on unlabeled images. Our insight is to learn fine-to-coarse features concurrently at superpixels, segments, and full image levels, enforcing consistency and goodness of feature induced segmentations while maximizing discrimination among image instances. Our model innovates vision transformers on three aspects. 1) We use adaptive segment tokens instead of fixed-shape patch tokens. 2) We create a token hierarchy by inserting graph pooling between transformer blocks, naturally producing consistent multi-scale segmentations while increasing the segment size and reducing the number of tokens. 3) We produce hierarchical image segmentation for free while training for recognition by maximizing image-wise discrimination. Our work delivers the first concurrent recognition and hierarchical segmentation model without any supervision. Validated on ImageNet and PASCAL VOC, it achieves better recognition and segmentation with higher computational efficiency.