 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee, Point, Fly: A Learning-Free VLM Framework for Universal Unmanned Aerial Navigation
Sep 26, 2025



We present See, Point, Fly (SPF), a training-free aerial vision-and-language navigation (AVLN) framework built atop vision-language models (VLMs). SPF is capable of navigating to any goal based on any type of free-form instructions in any kind of environment. In contrast to existing VLM-based approaches that treat action prediction as a text generation task, our key insight is to consider action prediction for AVLN as a 2D spatial grounding task. SPF harnesses VLMs to decompose vague language instructions into iterative annotation of 2D waypoints on the input image. Along with the predicted traveling distance, SPF transforms predicted 2D waypoints into 3D displacement vectors as action commands for UAVs. Moreover, SPF also adaptively adjusts the traveling distance to facilitate more efficient navigation. Notably, SPF performs navigation in a closed-loop control manner, enabling UAVs to follow dynamic targets in dynamic environments. SPF sets a new state of the art in DRL simulation benchmark, outperforming the previous best method by an absolute margin of 63%. In extensive real-world evaluations, SPF outperforms strong baselines by a large margin. We also conduct comprehensive ablation studies to highlight the effectiveness of our design choice. Lastly, SPF shows remarkable generalization to different VLMs. Project page: https://spf-web.pages.dev
DD-rPPGNet: De-interfering and Descriptive Feature Learning for Unsupervised rPPG Estimation
Jul 31, 2024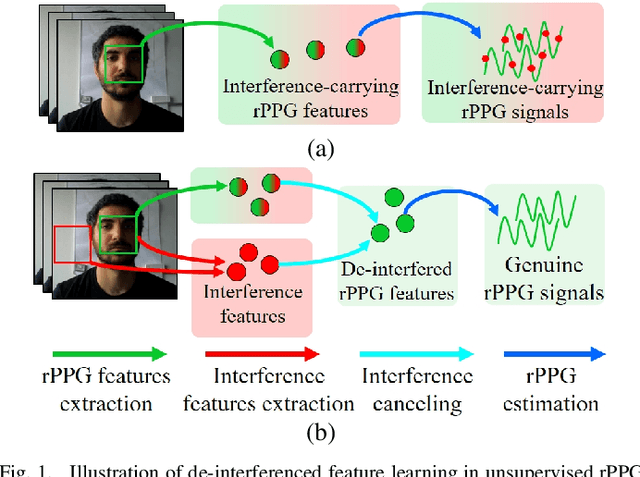
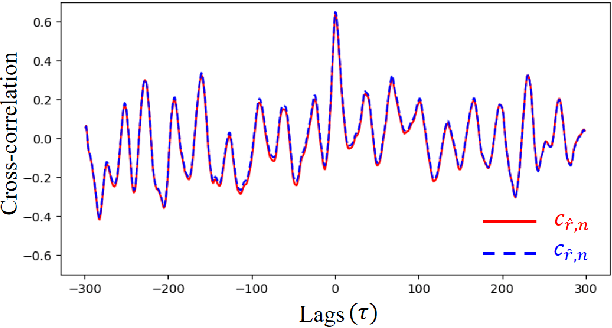
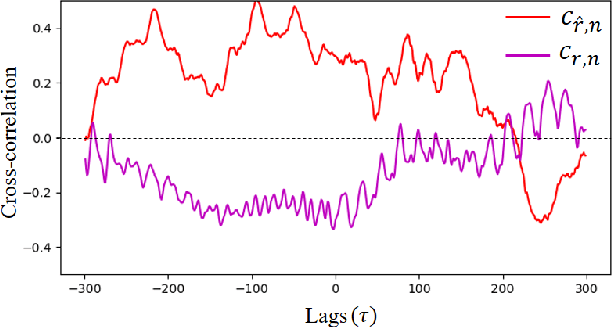
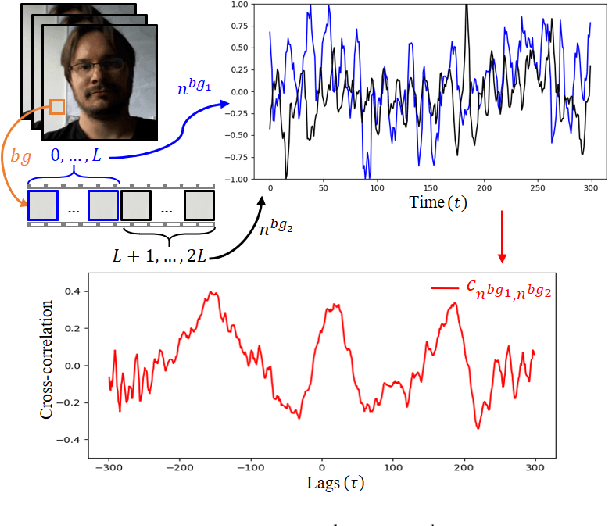
Remote Photoplethysmography (rPPG) aims to measure physiological signals and Heart Rate (HR) from facial videos. Recent unsupervised rPPG estimation methods have shown promising potential in estimating rPPG signals from facial regions without relying on ground truth rPPG signals. However, these methods seem oblivious to interference existing in rPPG signals and still result in unsatisfactory performance. In this paper, we propose a novel De-interfered and Descriptive rPPG Estimation Network (DD-rPPGNet) to eliminate the interference within rPPG features for learning genuine rPPG signals. First, we investigate the characteristics of local spatial-temporal similarities of interference and design a novel unsupervised model to estimate the interference. Next, we propose an unsupervised de-interfered method to learn genuine rPPG signals with two stages. In the first stage, we estimate the initial rPPG signals by contrastive learning from both the training data and their augmented counterparts. In the second stage, we use the estimated interference features to derive de-interfered rPPG features and encourage the rPPG signals to be distinct from the interference. In addition, we propose an effective descriptive rPPG feature learning by developing a strong 3D Learnable Descriptive Convolution (3DLDC) to capture the subtle chrominance changes for enhancing rPPG estimation. Extensive experiments conducted on five rPPG benchmark datasets demonstrate that the proposed DD-rPPGNet outperforms previous unsupervised rPPG estimation methods and achieves competitive performances with state-of-the-art supervised rPPG methods.
Fully Test-Time rPPG Estimation via Synthetic Signal-Guided Feature Learning
Jul 18, 2024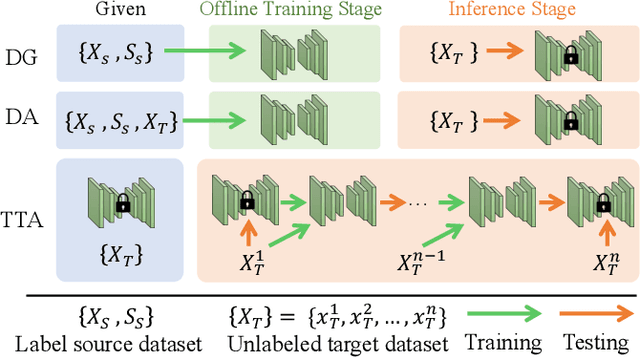
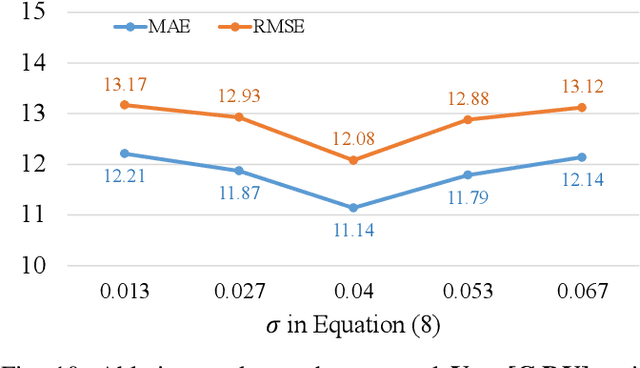
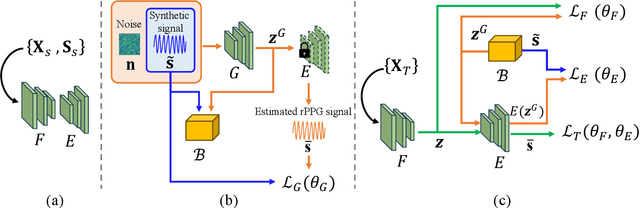
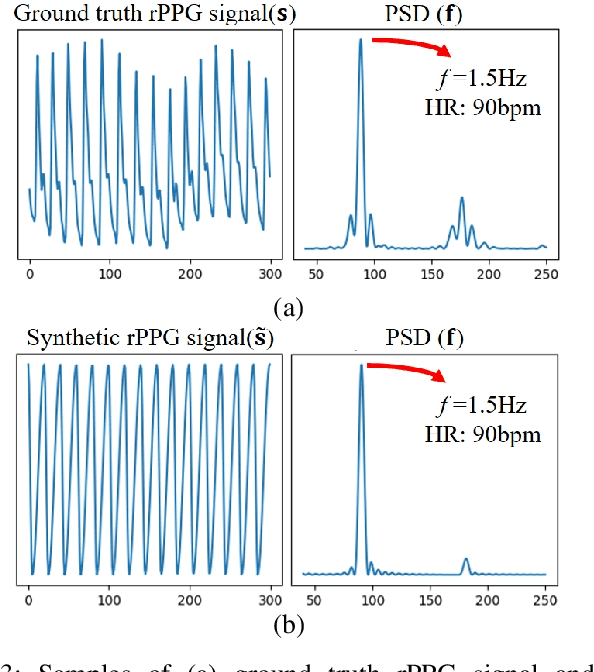
Many remote photoplethysmography (rPPG) estimation models have achieved promising performance on the training domain but often fail to measure the physiological signals or heart rates (HR) on test domains. Domain generalization (DG) or domain adaptation (DA) techniques are therefore adopted in the offline training stage to adapt the model to the unobserved or observed test domain by referring to all the available source domain data. However, in rPPG estimation problems, the adapted model usually confronts challenges of estimating target data with various domain information, such as different video capturing settings, individuals of different age ranges, or of different HR distributions. In contrast, Test-Time Adaptation (TTA), by online adapting to unlabeled target data without referring to any source data, enables the model to adaptively estimate rPPG signals of various unseen domains. In this paper, we first propose a novel TTA-rPPG benchmark, which encompasses various domain information and HR distributions, to simulate the challenges encountered in rPPG estimation. Next, we propose a novel synthetic signal-guided rPPG estimation framework with a two-fold purpose. First, we design an effective spectral-based entropy minimization to enforce the rPPG model to learn new target domain information. Second, we develop a synthetic signal-guided feature learning, by synthesizing pseudo rPPG signals as pseudo ground-truths to guide a conditional generator to generate latent rPPG features. The synthesized rPPG signals and the generated rPPG features are used to guide the rPPG model to broadly cover various HR distributions. Our extensive experiments on the TTA-rPPG benchmark show that the proposed method achieves superior performance and outperforms previous DG and DA methods across most protocols of the proposed TTA-rPPG benchmark.
Novelty Driven Evolutionary Neural Architecture Search
Apr 01, 2022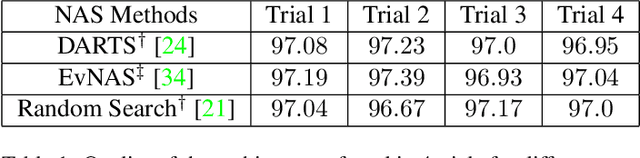
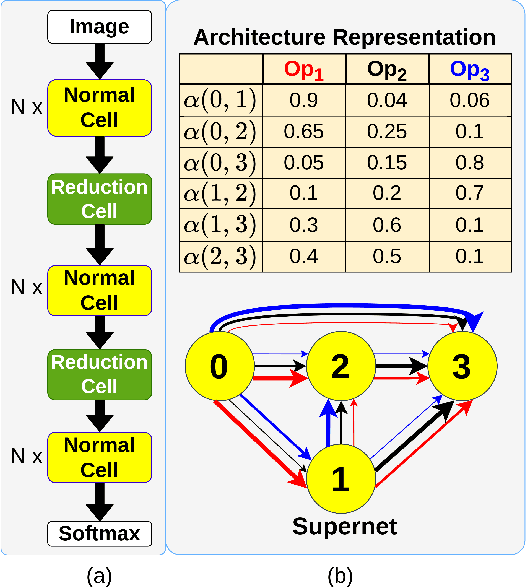
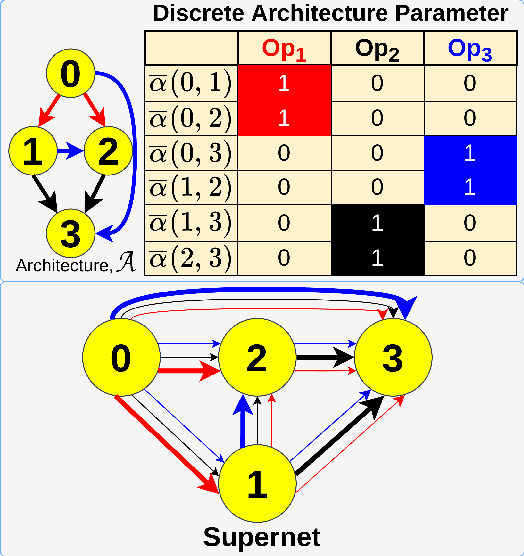
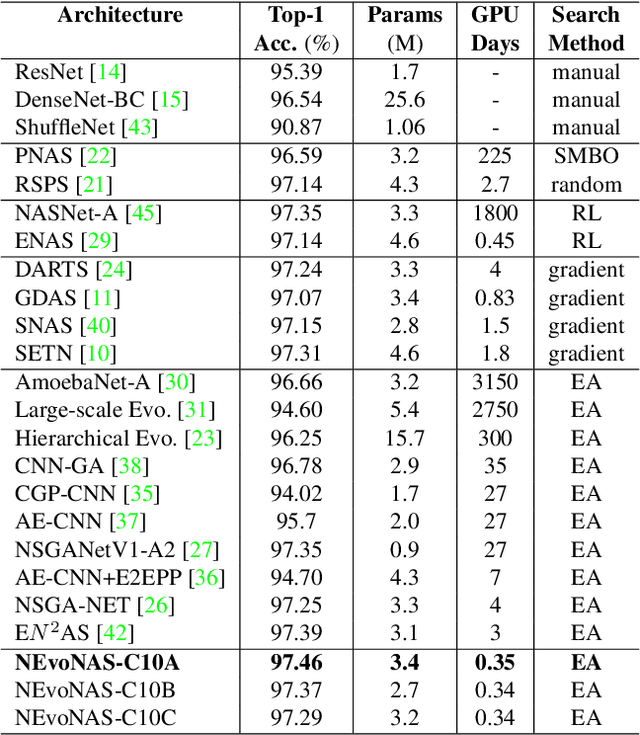
Evolutionary algorithms (EA) based neural architecture search (NAS) involves evaluating each architecture by training it from scratch, which is extremely time-consuming. This can be reduced by using a supernet for estimating the fitness of an architecture due to weight sharing among all architectures in the search space. However, the estimated fitness is very noisy due to the co-adaptation of the operations in the supernet which results in NAS methods getting trapped in local optimum. In this paper, we propose a method called NEvoNAS wherein the NAS problem is posed as a multi-objective problem with 2 objectives: (i) maximize architecture novelty, (ii) maximize architecture fitness/accuracy. The novelty search is used for maintaining a diverse set of solutions at each generation which helps avoiding local optimum traps while the architecture fitness is calculated using supernet. NSGA-II is used for finding the \textit{pareto optimal front} for the NAS problem and the best architecture in the pareto front is returned as the searched architecture. Exerimentally, NEvoNAS gives better results on 2 different search spaces while using significantly less computational resources as compared to previous EA-based methods. The code for our paper can be found in https://github.com/nightstorm0909/NEvoNAS.
Neural Architecture Search using Progressive Evolution
Mar 03, 2022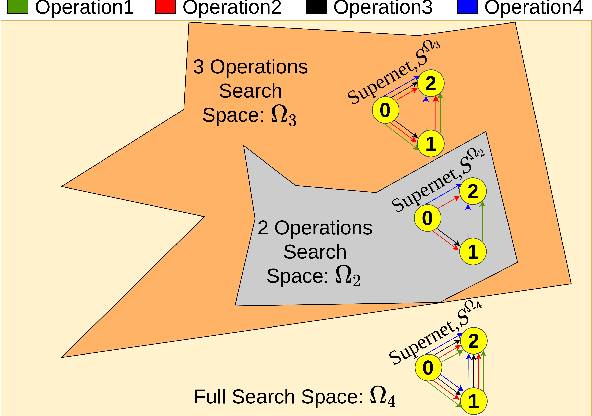
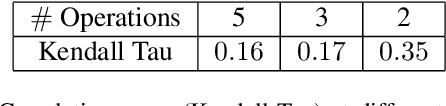
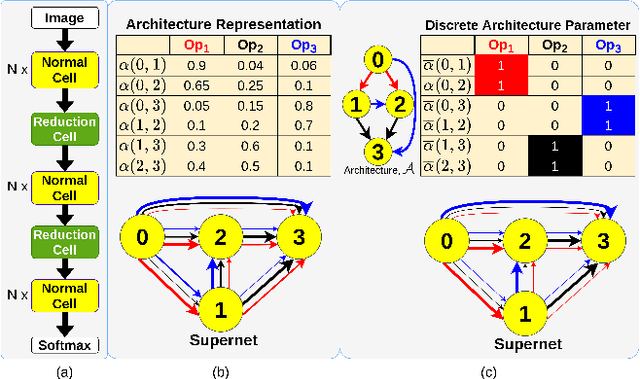
Vanilla neural architecture search using evolutionary algorithms (EA) involves evaluating each architecture by training it from scratch, which is extremely time-consuming. This can be reduced by using a supernet to estimate the fitness of every architecture in the search space due to its weight sharing nature. However, the estimated fitness is very noisy due to the co-adaptation of the operations in the supernet. In this work, we propose a method called pEvoNAS wherein the whole neural architecture search space is progressively reduced to smaller search space regions with good architectures. This is achieved by using a trained supernet for architecture evaluation during the architecture search using genetic algorithm to find search space regions with good architectures. Upon reaching the final reduced search space, the supernet is then used to search for the best architecture in that search space using evolution. The search is also enhanced by using weight inheritance wherein the supernet for the smaller search space inherits its weights from previous trained supernet for the bigger search space. Exerimentally, pEvoNAS gives better results on CIFAR-10 and CIFAR-100 while using significantly less computational resources as compared to previous EA-based methods. The code for our paper can be found in https://github.com/nightstorm0909/pEvoNAS
Neural Architecture Search using Covariance Matrix Adaptation Evolution Strategy
Jul 15, 2021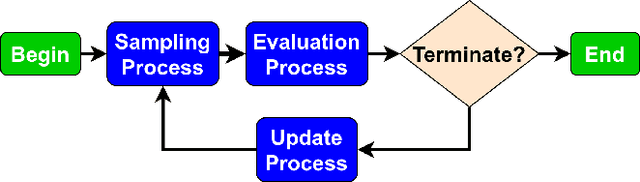
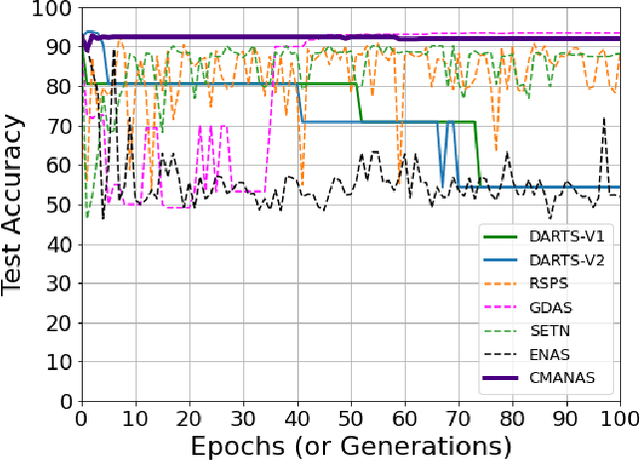
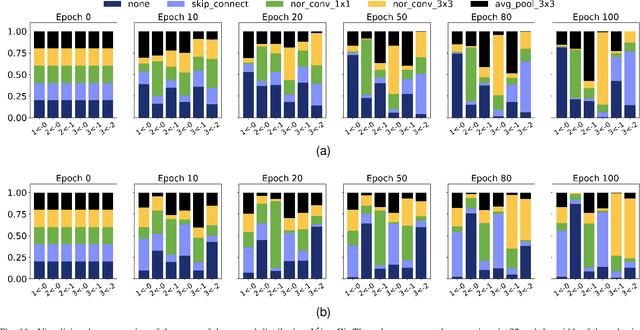
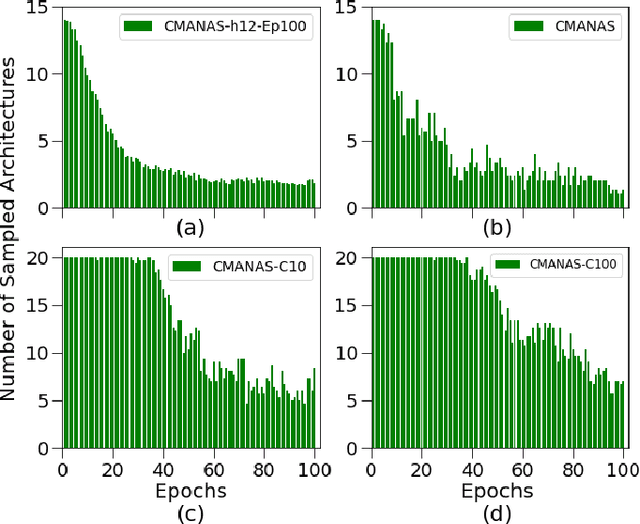
Evolution-based neural architecture search requires high computational resources, resulting in long search time. In this work, we propose a framework of applying the Covariance Matrix Adaptation Evolution Strategy (CMA-ES) to the neural architecture search problem called CMANAS, which achieves better results than previous evolution-based methods while reducing the search time significantly. The architectures are modelled using a normal distribution, which is updated using CMA-ES based on the fitness of the sampled population. We used the accuracy of a trained one shot model (OSM) on the validation data as a prediction of the fitness of an individual architecture to reduce the search time. We also used an architecture-fitness table (AF table) for keeping record of the already evaluated architecture, thus further reducing the search time. CMANAS finished the architecture search on CIFAR-10 with the top-1 test accuracy of 97.44% in 0.45 GPU day and on CIFAR-100 with the top-1 test accuracy of 83.24% for 0.6 GPU day on a single GPU. The top architectures from the searches on CIFAR-10 and CIFAR-100 were then transferred to ImageNet, achieving the top-5 accuracy of 92.6% and 92.1%, respectively.
Evolving Neural Architecture Using One Shot Model
Dec 23, 2020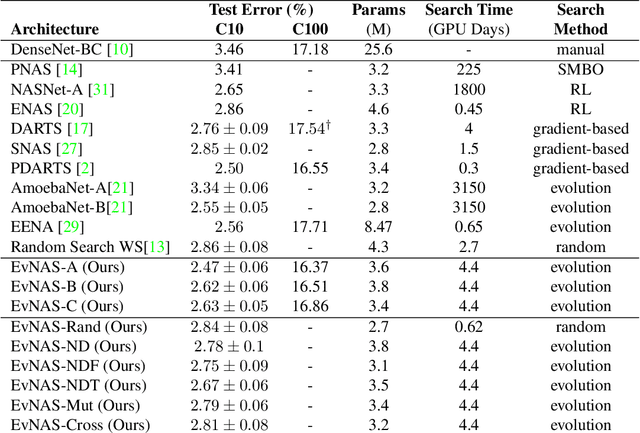
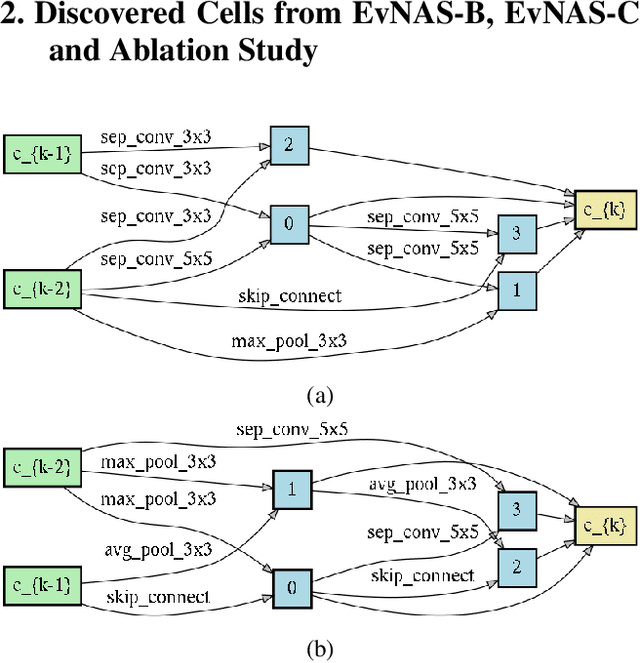
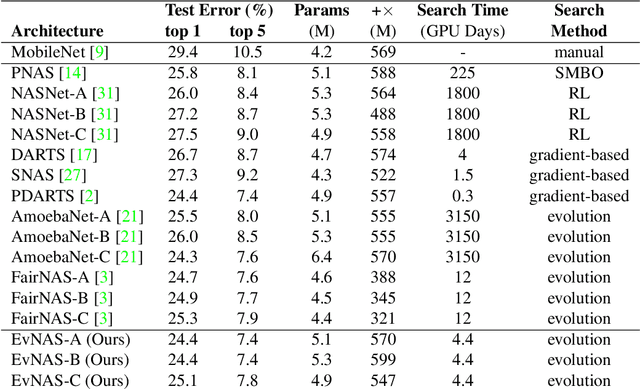
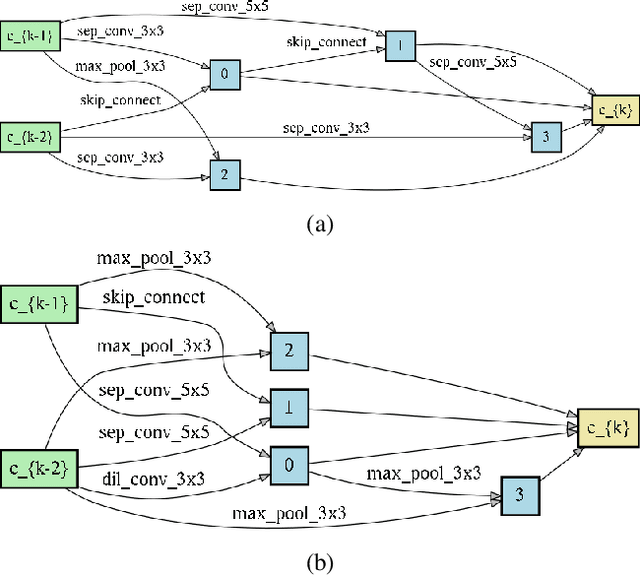
Neural Architecture Search (NAS) is emerging as a new research direction which has the potential to replace the hand-crafted neural architectures designed for specific tasks. Previous evolution based architecture search requires high computational resources resulting in high search time. In this work, we propose a novel way of applying a simple genetic algorithm to the NAS problem called EvNAS (Evolving Neural Architecture using One Shot Model) which reduces the search time significantly while still achieving better result than previous evolution based methods. The architectures are represented by using the architecture parameter of the one shot model which results in the weight sharing among the architectures for a given population of architectures and also weight inheritance from one generation to the next generation of architectures. We propose a decoding technique for the architecture parameter which is used to divert majority of the gradient information towards the given architecture and is also used for improving the performance prediction of the given architecture from the one shot model during the search process. Furthermore, we use the accuracy of the partially trained architecture on the validation data as a prediction of its fitness in order to reduce the search time. EvNAS searches for the architecture on the proxy dataset i.e. CIFAR-10 for 4.4 GPU day on a single GPU and achieves top-1 test error of 2.47% with 3.63M parameters which is then transferred to CIFAR-100 and ImageNet achieving top-1 error of 16.37% and top-5 error of 7.4% respectively. All of these results show the potential of evolutionary methods in solving the architecture search problem.
IF-Net: An Illumination-invariant Feature Network
Aug 10, 2020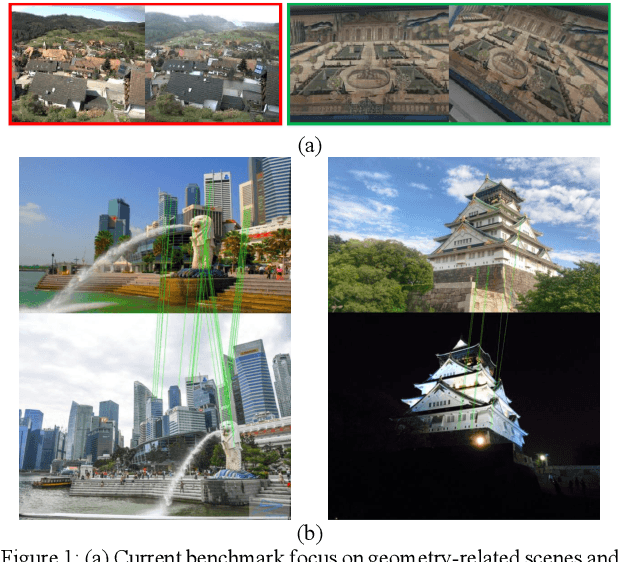
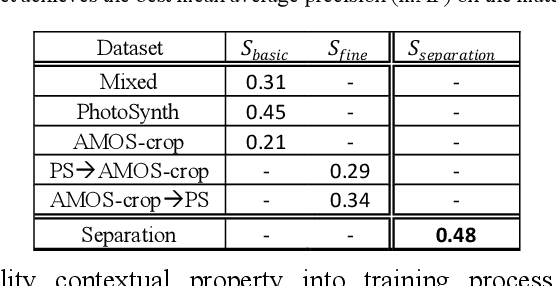


Feature descriptor matching is a critical step is many computer vision applications such as image stitching, image retrieval and visual localization. However, it is often affected by many practical factors which will degrade its performance. Among these factors, illumination variations are the most influential one, and especially no previous descriptor learning works focus on dealing with this problem. In this paper, we propose IF-Net, aimed to generate a robust and generic descriptor under crucial illumination changes conditions. We find out not only the kind of training data important but also the order it is presented. To this end, we investigate several dataset scheduling methods and propose a separation training scheme to improve the matching accuracy. Further, we propose a ROI loss and hard-positive mining strategy along with the training scheme, which can strengthen the ability of generated descriptor dealing with large illumination change conditions. We evaluate our approach on public patch matching benchmark and achieve the best results compared with several state-of-the-arts methods. To show the practicality, we further evaluate IF-Net on the task of visual localization under large illumination changes scenes, and achieves the best localization accuracy.
To Know Where We Are: Vision-Based Positioning in Outdoor Environments
Jun 19, 2015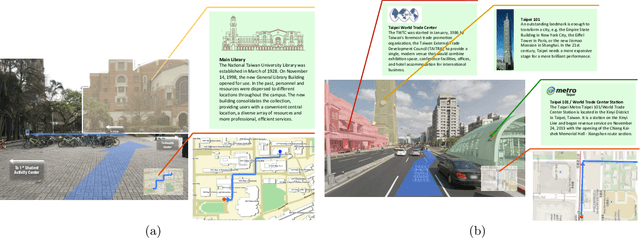
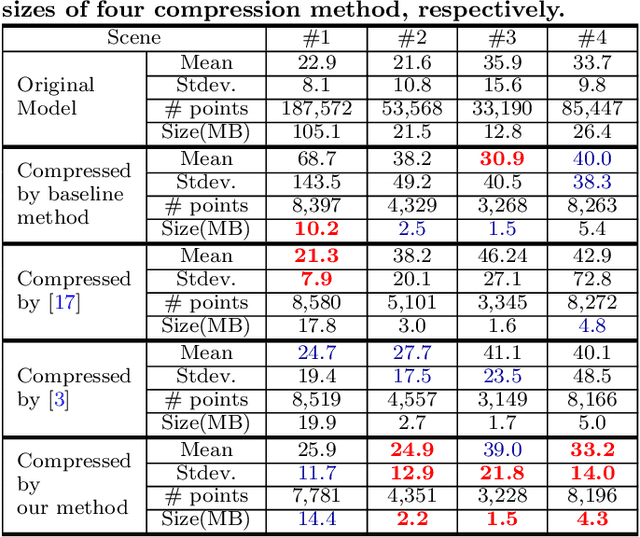
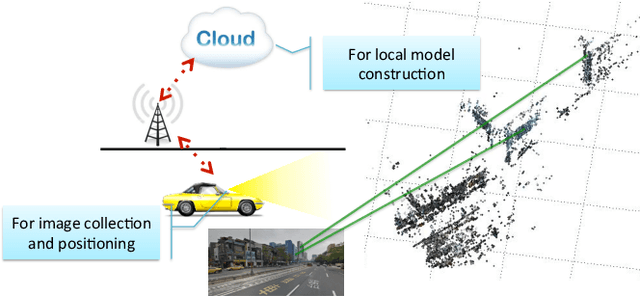
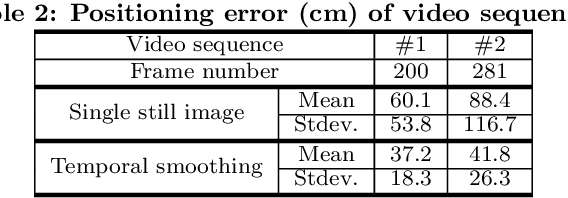
Augmented reality (AR) displays become more and more popular recently, because of its high intuitiveness for humans and high-quality head-mounted display have rapidly developed. To achieve such displays with augmented information, highly accurate image registration or ego-positioning are required, but little attention have been paid for out-door environments. This paper presents a method for ego-positioning in outdoor environments with low cost monocular cameras. To reduce the computational and memory requirements as well as the communication overheads, we formulate the model compression algorithm as a weighted k-cover problem for better preserving model structures. Specifically for real-world vision-based positioning applications, we consider the issues with large scene change and propose a model update algorithm to tackle these problems. A long- term positioning dataset with more than one month, 106 sessions, and 14,275 images is constructed. Based on both local and up-to-date models constructed in our approach, extensive experimental results show that high positioning accuracy (mean ~ 30.9cm, stdev. ~ 15.4cm) can be achieved, which outperforms existing vision-based algorithms.