 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToonifyGB: StyleGAN-based Gaussian Blendshapes for 3D Stylized Head Avatars
May 15, 2025The introduction of 3D Gaussian blendshapes has enabled the real-time reconstruction of animatable head avatars from monocular video. Toonify, a StyleGAN-based framework, has become widely used for facial image stylization. To extend Toonify for synthesizing diverse stylized 3D head avatars using Gaussian blendshapes, we propose an efficient two-stage framework, ToonifyGB. In Stage 1 (stylized video generation), we employ an improved StyleGAN to generate the stylized video from the input video frames, which addresses the limitation of cropping aligned faces at a fixed resolution as preprocessing for normal StyleGAN. This process provides a more stable video, which enables Gaussian blendshapes to better capture the high-frequency details of the video frames, and efficiently generate high-quality animation in the next stage. In Stage 2 (Gaussian blendshapes synthesis), we learn a stylized neutral head model and a set of expression blendshapes from the generated video. By combining the neutral head model with expression blendshapes, ToonifyGB can efficiently render stylized avatars with arbitrary expressions. We validate the effectiveness of ToonifyGB on the benchmark dataset using two styles: Arcane and Pixar.
Learning Conditional Random Fields with Augmented Observations for Partially Observed Action Recognition
Dec 05, 2018
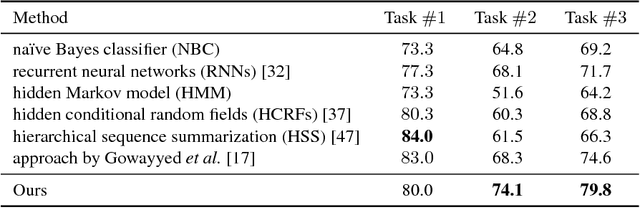
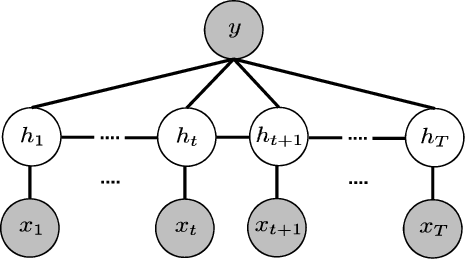
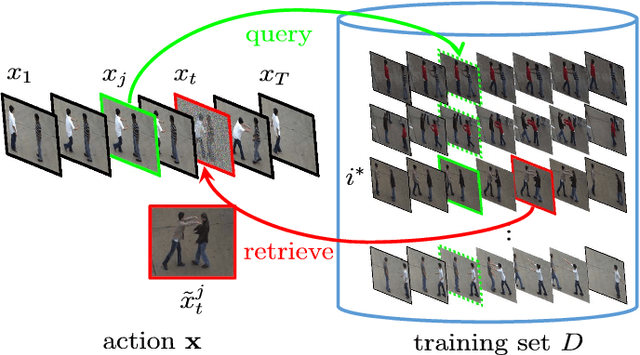
This paper aims at recognizing partially observed human actions in videos. Action videos acquired in uncontrolled environments often contain corrupt frames, which make actions partially observed. Furthermore, these frames can last for arbitrary lengths of time and appear irregularly. They are inconsistent with training data and degrade the performance of pre-trained action recognition systems. We present an approach to address this issue. For each training and testing actions, we divide it into segments and explore the mutual dependency between temporal segments. This property states that the similarity of two actions at one segment often implies their similarity at another. We augment each segment with extra alternatives retrieved from training data. The augmentation algorithm is designed in a way where a few alternatives are good enough to replace the original segment where corrupt frames occur. Our approach is developed upon hidden conditional random fields and leverages the flexibility of hidden variables for uncertainty handling. It turns out that our approach integrates corrupt segment detection and alternative selection into the process of prediction, and can recognize partially observed actions more accurately. It is evaluated on both fully observed actions and partially observed ones with either synthetic or real corrupt frames. The experimental results manifest its general applicability and superior performance, especially when corrupt frames are present in the action videos.
To Know Where We Are: Vision-Based Positioning in Outdoor Environments
Jun 19, 2015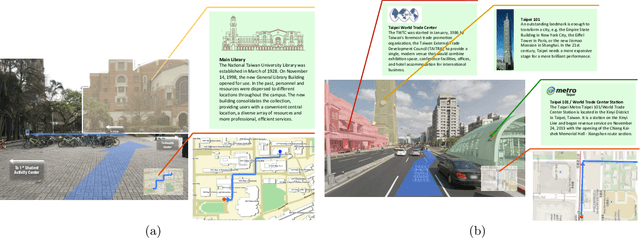
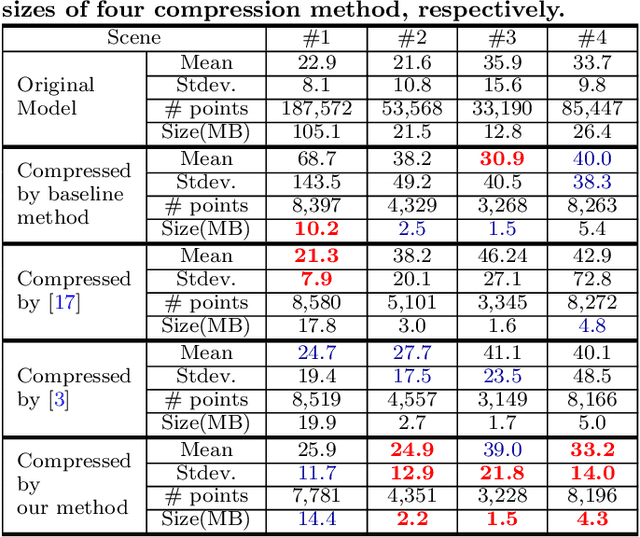
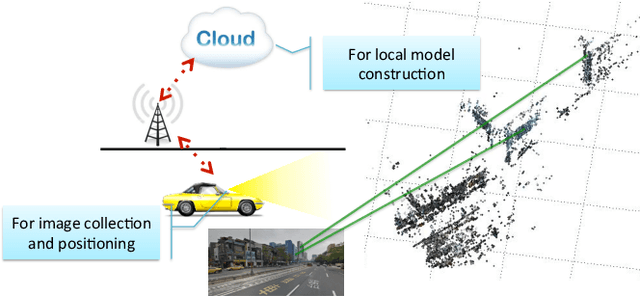
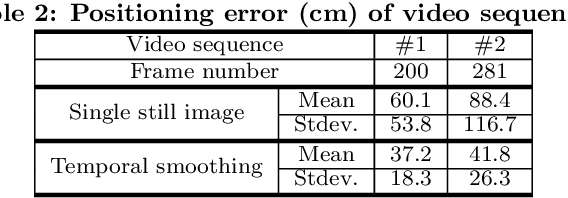
Augmented reality (AR) displays become more and more popular recently, because of its high intuitiveness for humans and high-quality head-mounted display have rapidly developed. To achieve such displays with augmented information, highly accurate image registration or ego-positioning are required, but little attention have been paid for out-door environments. This paper presents a method for ego-positioning in outdoor environments with low cost monocular cameras. To reduce the computational and memory requirements as well as the communication overheads, we formulate the model compression algorithm as a weighted k-cover problem for better preserving model structures. Specifically for real-world vision-based positioning applications, we consider the issues with large scene change and propose a model update algorithm to tackle these problems. A long- term positioning dataset with more than one month, 106 sessions, and 14,275 images is constructed. Based on both local and up-to-date models constructed in our approach, extensive experimental results show that high positioning accuracy (mean ~ 30.9cm, stdev. ~ 15.4cm) can be achieved, which outperforms existing vision-based algorithms.