 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestoration-Guided Kuzushiji Character Recognition Framework under Seal Interference
Feb 22, 2026Kuzushiji was one of the most popular writing styles in pre-modern Japan and was widely used in both personal letters and official documents. However, due to its highly cursive forms and extensive glyph variations, most modern Japanese readers cannot directly interpret Kuzushiji characters. Therefore, recent research has focused on developing automated Kuzushiji character recognition methods, which have achieved satisfactory performance on relatively clean Kuzushiji document images. However, existing methods struggle to maintain recognition accuracy under seal interference (e.g., when seals overlap characters), despite the frequent occurrence of seals in pre-modern Japanese documents. To address this challenge, we propose a three-stage restoration-guided Kuzushiji character recognition (RG-KCR) framework specifically designed to mitigate seal interference. We construct datasets for evaluating Kuzushiji character detection (Stage 1) and classification (Stage 3). Experimental results show that the YOLOv12-medium model achieves a precision of 98.0% and a recall of 93.3% on the constructed test set. We quantitatively evaluate the restoration performance of Stage 2 using PSNR and SSIM. In addition, we conduct an ablation study to demonstrate that Stage 2 improves the Top-1 accuracy of Metom, a Vision Transformer (ViT)-based Kuzushiji classifier employed in Stage 3, from 93.45% to 95.33%. The implementation code of this work is available at https://ruiyangju.github.io/RG-KCR.
GlassesGB: Controllable 2D GAN-Based Eyewear Personalization for 3D Gaussian Blendshapes Head Avatars
Jan 23, 2026Virtual try-on systems allow users to interactively try different products within VR scenarios. However, most existing VTON methods operate only on predefined eyewear templates and lack support for fine-grained, user-driven customization. While GlassesGAN enables personalized 2D eyewear design, its capability remains limited to 2D image generation. Motivated by the success of 3D Gaussian Blendshapes in head reconstruction, we integrate these two techniques and propose GlassesGB, a framework that supports customizable eyewear generation for 3D head avatars. GlassesGB effectively bridges 2D generative customization with 3D head avatar rendering, addressing the challenge in achieving personalized eyewear design for VR applications. The implementation code is available at https://ruiyangju.github.io/GlassesGB.
MFE-GAN: Efficient GAN-based Framework for Document Image Enhancement and Binarization with Multi-scale Feature Extraction
Dec 16, 2025



Document image enhancement and binarization are commonly performed prior to document analysis and recognition tasks for improving the efficiency and accuracy of optical character recognition (OCR) systems. This is because directly recognizing text in degraded documents, particularly in color images, often results in unsatisfactory recognition performance. To address these issues, existing methods train independent generative adversarial networks (GANs) for different color channels to remove shadows and noise, which, in turn, facilitates efficient text information extraction. However, deploying multiple GANs results in long training and inference times. To reduce both training and inference times of document image enhancement and binarization models, we propose MFE-GAN, an efficient GAN-based framework with multi-scale feature extraction (MFE), which incorporates Haar wavelet transformation (HWT) and normalization to process document images before feeding them into GANs for training. In addition, we present novel generators, discriminators, and loss functions to improve the model's performance, and we conduct ablation studies to demonstrate their effectiveness. Experimental results on the Benchmark, Nabuco, and CMATERdb datasets demonstrate that the proposed MFE-GAN significantly reduces the total training and inference times while maintaining comparable performance with respect to state-of-the-art (SOTA) methods. The implementation of this work is available at https://ruiyangju.github.io/MFE-GAN.
DKDS: A Benchmark Dataset of Degraded Kuzushiji Documents with Seals for Detection and Binarization
Nov 12, 2025Kuzushiji, a pre-modern Japanese cursive script, can currently be read and understood by only a few thousand trained experts in Japan. With the rapid development of deep learning, researchers have begun applying Optical Character Recognition (OCR) techniques to transcribe Kuzushiji into modern Japanese. Although existing OCR methods perform well on clean pre-modern Japanese documents written in Kuzushiji, they often fail to consider various types of noise, such as document degradation and seals, which significantly affect recognition accuracy. To the best of our knowledge, no existing dataset specifically addresses these challenges. To address this gap, we introduce the Degraded Kuzushiji Documents with Seals (DKDS) dataset as a new benchmark for related tasks. We describe the dataset construction process, which required the assistance of a trained Kuzushiji expert, and define two benchmark tracks: (1) text and seal detection and (2) document binarization. For the text and seal detection track, we provide baseline results using multiple versions of the You Only Look Once (YOLO) models for detecting Kuzushiji characters and seals. For the document binarization track, we present baseline results from traditional binarization algorithms, traditional algorithms combined with K-means clustering, and Generative Adversarial Network (GAN)-based methods. The DKDS dataset and the implementation code for baseline methods are available at https://ruiyangju.github.io/DKDS.
ToonifyGB: StyleGAN-based Gaussian Blendshapes for 3D Stylized Head Avatars
May 15, 2025The introduction of 3D Gaussian blendshapes has enabled the real-time reconstruction of animatable head avatars from monocular video. Toonify, a StyleGAN-based framework, has become widely used for facial image stylization. To extend Toonify for synthesizing diverse stylized 3D head avatars using Gaussian blendshapes, we propose an efficient two-stage framework, ToonifyGB. In Stage 1 (stylized video generation), we employ an improved StyleGAN to generate the stylized video from the input video frames, which addresses the limitation of cropping aligned faces at a fixed resolution as preprocessing for normal StyleGAN. This process provides a more stable video, which enables Gaussian blendshapes to better capture the high-frequency details of the video frames, and efficiently generate high-quality animation in the next stage. In Stage 2 (Gaussian blendshapes synthesis), we learn a stylized neutral head model and a set of expression blendshapes from the generated video. By combining the neutral head model with expression blendshapes, ToonifyGB can efficiently render stylized avatars with arbitrary expressions. We validate the effectiveness of ToonifyGB on the benchmark dataset using two styles: Arcane and Pixar.
FCE-YOLOv8: YOLOv8 with Feature Context Excitation Modules for Fracture Detection in Pediatric Wrist X-ray Images
Oct 01, 2024



Children often suffer wrist trauma in daily life, while they usually need radiologists to analyze and interpret X-ray images before surgical treatment by surgeons. The development of deep learning has enabled neural networks to serve as computer-assisted diagnosis (CAD) tools to help doctors and experts in medical image diagnostics. Since the You Only Look Once Version-8 (YOLOv8) model has obtained the satisfactory success in object detection tasks, it has been applied to various fracture detection. This work introduces four variants of Feature Contexts Excitation-YOLOv8 (FCE-YOLOv8) model, each incorporating a different FCE module (i.e., modules of Squeeze-and-Excitation (SE), Global Context (GC), Gather-Excite (GE), and Gaussian Context Transformer (GCT)) to enhance the model performance. Experimental results on GRAZPEDWRI-DX dataset demonstrate that our proposed YOLOv8+GC-M3 model improves the mAP@50 value from 65.78% to 66.32%, outperforming the state-of-the-art (SOTA) model while reducing inference time. Furthermore, our proposed YOLOv8+SE-M3 model achieves the highest mAP@50 value of 67.07%, exceeding the SOTA performance. The implementation of this work is available at https://github.com/RuiyangJu/FCE-YOLOv8.
YOLOv8-ResCBAM: YOLOv8 Based on An Effective Attention Module for Pediatric Wrist Fracture Detection
Sep 27, 2024



Wrist trauma and even fractures occur frequently in daily life, particularly among children who account for a significant proportion of fracture cases. Before performing surgery, surgeons often request patients to undergo X-ray imaging first, and prepare for the surgery based on the analysis of the X-ray images. With the development of neural networks, You Only Look Once (YOLO) series models have been widely used in fracture detection for Computer-Assisted Diagnosis, where the YOLOv8 model has obtained the satisfactory results. Applying the attention modules to neural networks is one of the effective methods to improve the model performance. This paper proposes YOLOv8-ResCBAM, which incorporates Convolutional Block Attention Module integrated with resblock (ResCBAM) into the original YOLOv8 network architecture. The experimental results on the GRAZPEDWRI-DX dataset demonstrate that the mean Average Precision calculated at Intersection over Union threshold of 0.5 (mAP 50) of the proposed model increased from 63.6% of the original YOLOv8 model to 65.8%, which achieves the state-of-the-art performance. The implementation code is available at https://github.com/RuiyangJu/Fracture_Detection_Improved_YOLOv8.
ORB-SfMLearner: ORB-Guided Self-supervised Visual Odometry with Selective Online Adaptation
Sep 18, 2024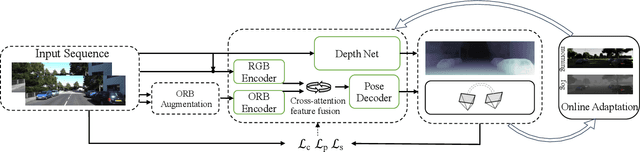


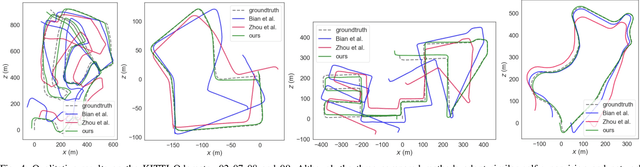
Deep visual odometry, despite extensive research, still faces limitations in accuracy and generalizability that prevent its broader application. To address these challenges, we propose an Oriented FAST and Rotated BRIEF (ORB)-guided visual odometry with selective online adaptation named ORB-SfMLearner. We present a novel use of ORB features for learning-based ego-motion estimation, leading to more robust and accurate results. We also introduce the cross-attention mechanism to enhance the explainability of PoseNet and have revealed that driving direction of the vehicle can be explained through attention weights, marking a novel exploration in this area. To improve generalizability, our selective online adaptation allows the network to rapidly and selectively adjust to the optimal parameters across different domains. Experimental results on KITTI and vKITTI datasets show that our method outperforms previous state-of-the-art deep visual odometry methods in terms of ego-motion accuracy and generalizability.
Efficient GANs for Document Image Binarization Based on DWT and Normalization
Jul 05, 2024



For document image binarization task, generative adversarial networks (GANs) can generate images where shadows and noise are effectively removed, which allow for text information extraction. The current state-of-the-art (SOTA) method proposes a three-stage network architecture that utilizes six GANs. Despite its excellent model performance, the SOTA network architecture requires long training and inference times. To overcome this problem, this work introduces an efficient GAN method based on the three-stage network architecture that incorporates the Discrete Wavelet Transformation and normalization to reduce the input image size, which in turns, decrease both training and inference times. In addition, this work presents novel generators, discriminators, and loss functions to improve the model's performance. Experimental results show that the proposed method reduces the training time by 10% and the inference time by 26% when compared to the SOTA method while maintaining the model performance at 73.79 of Avg-Score. Our implementation code is available on GitHub at https://github.com/RuiyangJu/Efficient_Document_Image_Binarization.
Global Context Modeling in YOLOv8 for Pediatric Wrist Fracture Detection
Jul 03, 2024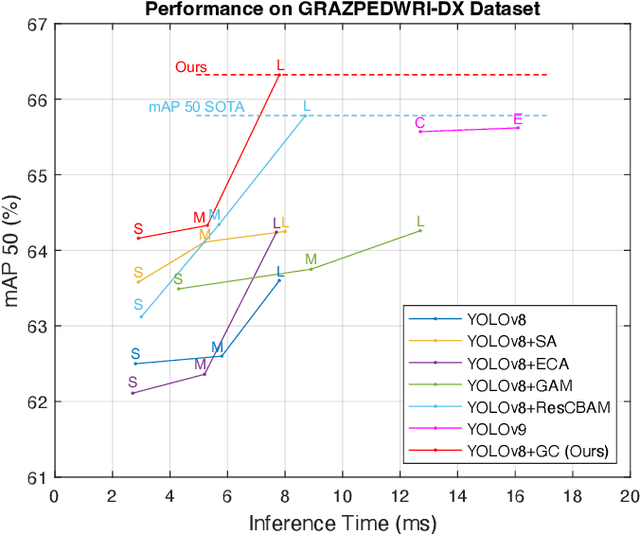

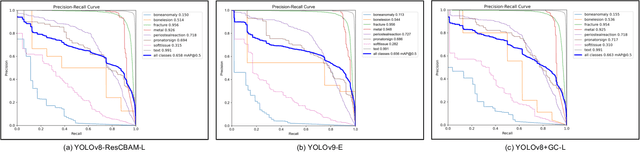
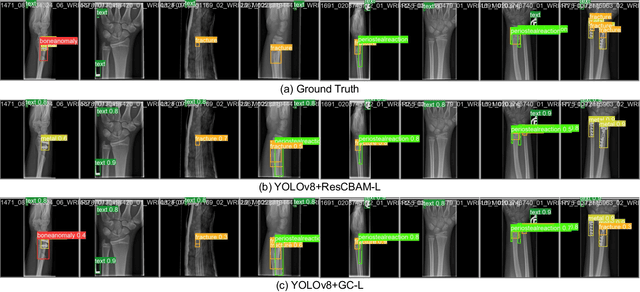
Children often suffer wrist injuries in daily life, while fracture injuring radiologists usually need to analyze and interpret X-ray images before surgical treatment by surgeons. The development of deep learning has enabled neural network models to work as computer-assisted diagnosis (CAD) tools to help doctors and experts in diagnosis. Since the YOLOv8 models have obtained the satisfactory success in object detection tasks, it has been applied to fracture detection. The Global Context (GC) block effectively models the global context in a lightweight way, and incorporating it into YOLOv8 can greatly improve the model performance. This paper proposes the YOLOv8+GC model for fracture detection, which is an improved version of the YOLOv8 model with the GC block. Experimental results demonstrate that compared to the original YOLOv8 model, the proposed YOLOv8-GC model increases the mean average precision calculated at intersection over union threshold of 0.5 (mAP 50) from 63.58% to 66.32% on the GRAZPEDWRI-DX dataset, achieving the state-of-the-art (SOTA) level. The implementation code for this work is available on GitHub at https://github.com/RuiyangJu/YOLOv8_Global_Context_Fracture_Detection.