 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenAI-DrawIO-Creator: A Framework for Automated Diagram Generation
Jan 08, 2026Diagrams are crucial for communicating complex information, yet creating and modifying them remains a labor-intensive task. We present GenAI-DrawIO-Creator, a novel framework that leverages Large Language Models (LLMs) to automate diagram generation and manipulation in the structured XML format used by draw.io. Our system integrates Claude 3.7 to reason about structured visual data and produce valid diagram representations. Key contributions include a high-level system design enabling real-time diagram updates, specialized prompt engineering and error-checking to ensure well-formed XML outputs. We demonstrate a working prototype capable of generating accurate diagrams (such as network architectures and flowcharts) from natural language or code, and even replicating diagrams from images. Simulated evaluations show that our approach significantly reduces diagram creation time and produces outputs with high structural fidelity. Our results highlight the promise of Claude 3.7 in handling structured visual reasoning tasks and lay the groundwork for future research in AI-assisted diagramming applications.
U2-BENCH: Benchmarking Large Vision-Language Models on Ultrasound Understanding
May 23, 2025Ultrasound is a widely-used imaging modality critical to global healthcare, yet its interpretation remains challenging due to its varying image quality on operators, noises, and anatomical structures. Although large vision-language models (LVLMs) have demonstrated impressive multimodal capabilities across natural and medical domains, their performance on ultrasound remains largely unexplored. We introduce U2-BENCH, the first comprehensive benchmark to evaluate LVLMs on ultrasound understanding across classification, detection, regression, and text generation tasks. U2-BENCH aggregates 7,241 cases spanning 15 anatomical regions and defines 8 clinically inspired tasks, such as diagnosis, view recognition, lesion localization, clinical value estimation, and report generation, across 50 ultrasound application scenarios. We evaluate 20 state-of-the-art LVLMs, both open- and closed-source, general-purpose and medical-specific. Our results reveal strong performance on image-level classification, but persistent challenges in spatial reasoning and clinical language generation. U2-BENCH establishes a rigorous and unified testbed to assess and accelerate LVLM research in the uniquely multimodal domain of medical ultrasound imaging.
DehazeGS: Seeing Through Fog with 3D Gaussian Splatting
Jan 07, 2025

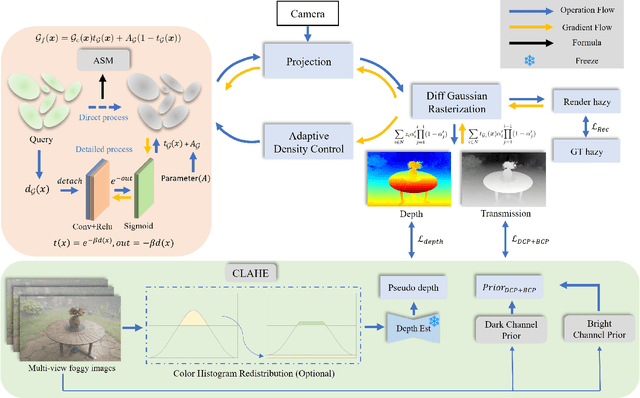

Current novel view synthesis tasks primarily rely on high-quality and clear images. However, in foggy scenes, scattering and attenuation can significantly degrade the reconstruction and rendering quality. Although NeRF-based dehazing reconstruction algorithms have been developed, their use of deep fully connected neural networks and per-ray sampling strategies leads to high computational costs. Moreover, NeRF's implicit representation struggles to recover fine details from hazy scenes. In contrast, recent advancements in 3D Gaussian Splatting achieve high-quality 3D scene reconstruction by explicitly modeling point clouds into 3D Gaussians. In this paper, we propose leveraging the explicit Gaussian representation to explain the foggy image formation process through a physically accurate forward rendering process. We introduce DehazeGS, a method capable of decomposing and rendering a fog-free background from participating media using only muti-view foggy images as input. We model the transmission within each Gaussian distribution to simulate the formation of fog. During this process, we jointly learn the atmospheric light and scattering coefficient while optimizing the Gaussian representation of the hazy scene. In the inference stage, we eliminate the effects of scattering and attenuation on the Gaussians and directly project them onto a 2D plane to obtain a clear view. Experiments on both synthetic and real-world foggy datasets demonstrate that DehazeGS achieves state-of-the-art performance in terms of both rendering quality and computational efficiency.
FAD-SAR: A Novel Fishing Activity Detection System via Synthetic Aperture Radar Images Based on Deep Learning Method
Apr 28, 2024Illegal, unreported, and unregulated (IUU) fishing seriously affects various aspects of human life. However, current methods for detecting and monitoring IUU activities at sea have limitations. While Synthetic Aperture Radar (SAR) can complement existing vessel detection systems, extracting useful information from SAR images using traditional methods, especially for IUU fishing identification, poses challenges. This paper proposes a deep learning-based system for detecting fishing activities. We implemented this system on the xView3 dataset using six classical object detection models: Faster R-CNN, Cascade R-CNN, SSD, RetinaNet, FSAF, and FCOS. We applied improvement methods to enhance the performance of the Faster R-CNN model. Specifically, training the Faster R-CNN model using Online Hard Example Mining (OHEM) strategy improved the Avg-F1 value from 0.212 to 0.216, representing a 1.96% improvement.
Flood Data Analysis on SpaceNet 8 Using Apache Sedona
Apr 28, 2024



With the escalating frequency of floods posing persistent threats to human life and property, satellite remote sensing has emerged as an indispensable tool for monitoring flood hazards. SpaceNet8 offers a unique opportunity to leverage cutting-edge artificial intelligence technologies to assess these hazards. A significant contribution of this research is its application of Apache Sedona, an advanced platform specifically designed for the efficient and distributed processing of large-scale geospatial data. This platform aims to enhance the efficiency of error analysis, a critical aspect of improving flood damage detection accuracy. Based on Apache Sedona, we introduce a novel approach that addresses the challenges associated with inaccuracies in flood damage detection. This approach involves the retrieval of cases from historical flood events, the adaptation of these cases to current scenarios, and the revision of the model based on clustering algorithms to refine its performance. Through the replication of both the SpaceNet8 baseline and its top-performing models, we embark on a comprehensive error analysis. This analysis reveals several main sources of inaccuracies. To address these issues, we employ data visual interpretation and histogram equalization techniques, resulting in significant improvements in model metrics. After these enhancements, our indicators show a notable improvement, with precision up by 5%, F1 score by 2.6%, and IoU by 4.5%. This work highlights the importance of advanced geospatial data processing tools, such as Apache Sedona. By improving the accuracy and efficiency of flood detection, this research contributes to safeguarding public safety and strengthening infrastructure resilience in flood-prone areas, making it a valuable addition to the field of remote sensing and disaster management.
Self-Supervised Learning for Building Damage Assessment from Large-scale xBD Satellite Imagery Benchmark Datasets
Jun 01, 2022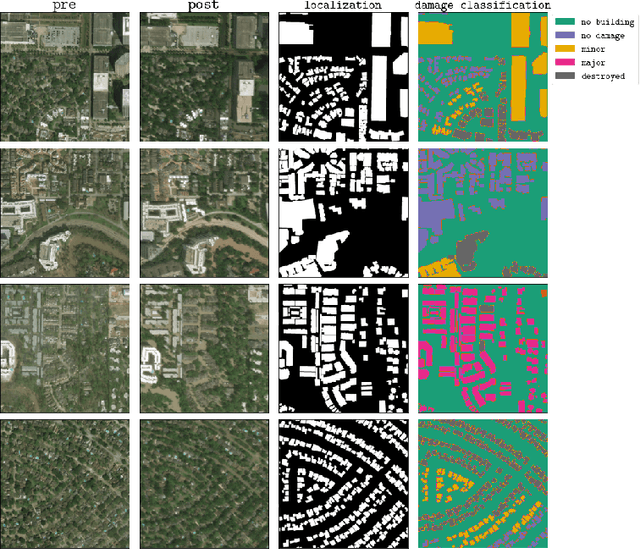
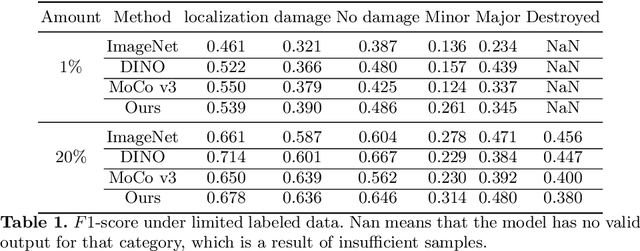
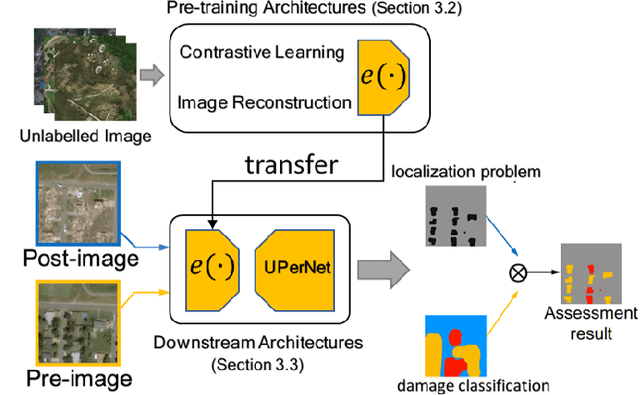
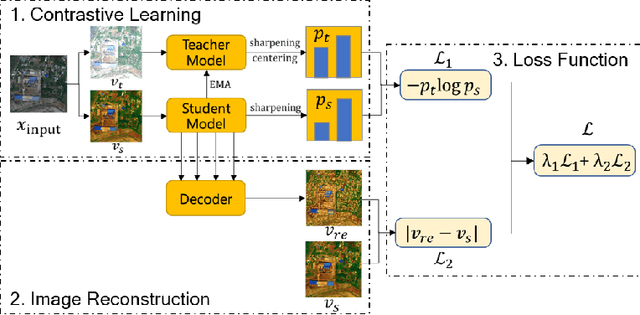
In the field of post-disaster assessment, for timely and accurate rescue and localization after a disaster, people need to know the location of damaged buildings. In deep learning, some scholars have proposed methods to make automatic and highly accurate building damage assessments by remote sensing images, which are proved to be more efficient than assessment by domain experts. However, due to the lack of a large amount of labeled data, these kinds of tasks can suffer from being able to do an accurate assessment, as the efficiency of deep learning models relies highly on labeled data. Although existing semi-supervised and unsupervised studies have made breakthroughs in this area, none of them has completely solved this problem. Therefore, we propose adopting a self-supervised comparative learning approach to address the task without the requirement of labeled data. We constructed a novel asymmetric twin network architecture and tested its performance on the xBD dataset. Experiment results of our model show the improvement compared to baseline and commonly used methods. We also demonstrated the potential of self-supervised methods for building damage recognition awareness.
Cross-Domain Object Detection with Mean-Teacher Transformer
May 03, 2022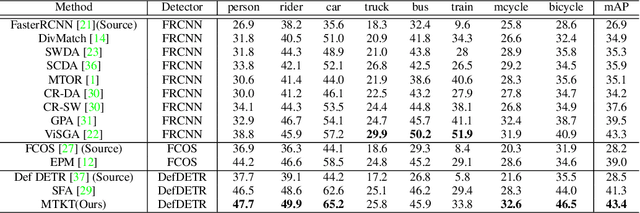
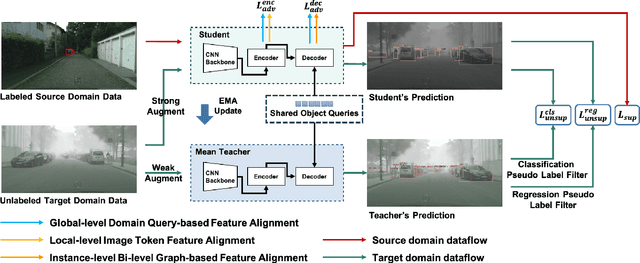
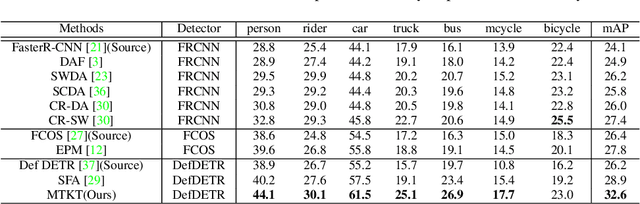
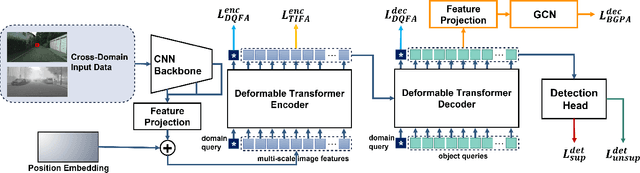
Recently, DEtection TRansformer (DETR), an end-to-end object detection pipeline, has achieved promising performance. However, it requires large-scale labeled data and suffers from domain shift, especially when no labeled data is available in the target domain. To solve this problem, we propose an end-to-end cross-domain detection transformer based on the mean teacher knowledge transfer (MTKT), which transfers knowledge between domains via pseudo labels. To improve the quality of pseudo labels in the target domain, which is a crucial factor for better domain adaptation, we design three levels of source-target feature alignment strategies based on the architecture of the Transformer, including domain query-based feature alignment (DQFA), bi-level-graph-based prototype alignment (BGPA), and token-wise image feature alignment (TIFA). These three levels of feature alignment match the global, local, and instance features between source and target, respectively. With these strategies, more accurate pseudo labels can be obtained, and knowledge can be better transferred from source to target, thus improving the cross-domain capability of the detection transformer. Extensive experiments demonstrate that our proposed method achieves state-of-the-art performance on three domain adaptation scenarios, especially the result of Sim10k to Cityscapes scenario is remarkably improved from 52.6 mAP to 57.9 mAP. Code will be released.