 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFM: Interpolant-free Dual Flow Matching
Oct 11, 2024


Continuous normalizing flows (CNFs) can model data distributions with expressive infinite-length architectures. But this modeling involves computationally expensive process of solving an ordinary differential equation (ODE) during maximum likelihood training. Recently proposed flow matching (FM) framework allows to substantially simplify the training phase using a regression objective with the interpolated forward vector field. In this paper, we propose an interpolant-free dual flow matching (DFM) approach without explicit assumptions about the modeled vector field. DFM optimizes the forward and, additionally, a reverse vector field model using a novel objective that facilitates bijectivity of the forward and reverse transformations. Our experiments with the SMAP unsupervised anomaly detection show advantages of DFM when compared to the CNF trained with either maximum likelihood or FM objectives with the state-of-the-art performance metrics.
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference
Oct 06, 2024



In vision-language models (VLMs), visual tokens usually consume a significant amount of computational overhead, despite their sparser information density compared to text tokens. To address this, most existing methods learn a network to prune redundant visual tokens and require additional training data. Differently, we propose an efficient training-free token optimization mechanism dubbed SparseVLM without extra parameters or fine-tuning costs. Concretely, given that visual tokens complement text tokens in VLMs for linguistic reasoning, we select visual-relevant text tokens to rate the significance of vision tokens within the self-attention matrix extracted from the VLMs. Then we progressively prune irrelevant tokens. To maximize sparsity while retaining essential information, we introduce a rank-based strategy to adaptively determine the sparsification ratio for each layer, alongside a token recycling method that compresses pruned tokens into more compact representations. Experimental results show that our SparseVLM improves the efficiency of various VLMs across a range of image and video understanding tasks. In particular, LLaVA equipped with SparseVLM reduces 61% to 67% FLOPs with a compression ratio of 78% while maintaining 93% of the accuracy. Our code is available at https://github.com/Gumpest/SparseVLMs.
Fisher-aware Quantization for DETR Detectors with Critical-category Objectives
Jul 03, 2024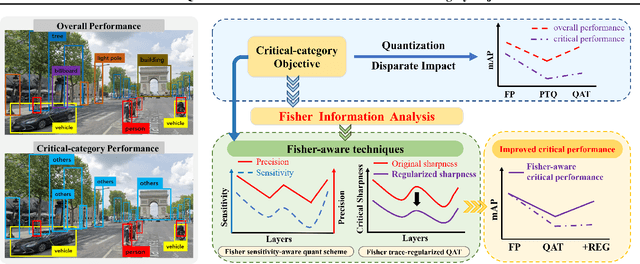


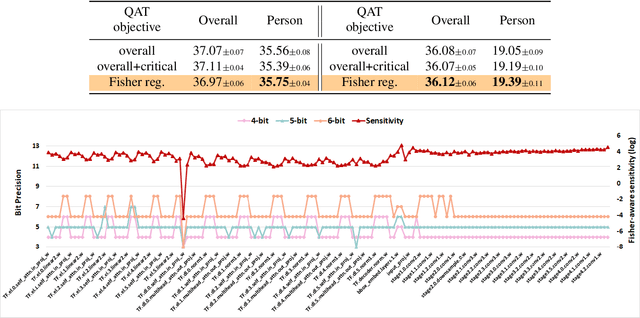
The impact of quantization on the overall performance of deep learning models is a well-studied problem. However, understanding and mitigating its effects on a more fine-grained level is still lacking, especially for harder tasks such as object detection with both classification and regression objectives. This work defines the performance for a subset of task-critical categories, i.e. the critical-category performance, as a crucial yet largely overlooked fine-grained objective for detection tasks. We analyze the impact of quantization at the category-level granularity, and propose methods to improve performance for the critical categories. Specifically, we find that certain critical categories have a higher sensitivity to quantization, and are prone to overfitting after quantization-aware training (QAT). To explain this, we provide theoretical and empirical links between their performance gaps and the corresponding loss landscapes with the Fisher information framework. Using this evidence, we apply a Fisher-aware mixed-precision quantization scheme, and a Fisher-trace regularization for the QAT on the critical-category loss landscape. The proposed methods improve critical-category metrics of the quantized transformer-based DETR detectors. They are even more significant in case of larger models and higher number of classes where the overfitting becomes more severe. For example, our methods lead to 10.4% and 14.5% mAP gains for, correspondingly, 4-bit DETR-R50 and Deformable DETR on the most impacted critical classes in the COCO Panoptic dataset.
ContextFlow++: Generalist-Specialist Flow-based Generative Models with Mixed-Variable Context Encoding
Jun 02, 2024



Normalizing flow-based generative models have been widely used in applications where the exact density estimation is of major importance. Recent research proposes numerous methods to improve their expressivity. However, conditioning on a context is largely overlooked area in the bijective flow research. Conventional conditioning with the vector concatenation is limited to only a few flow types. More importantly, this approach cannot support a practical setup where a set of context-conditioned (specialist) models are trained with the fixed pretrained general-knowledge (generalist) model. We propose ContextFlow++ approach to overcome these limitations using an additive conditioning with explicit generalist-specialist knowledge decoupling. Furthermore, we support discrete contexts by the proposed mixed-variable architecture with context encoders. Particularly, our context encoder for discrete variables is a surjective flow from which the context-conditioned continuous variables are sampled. Our experiments on rotated MNIST-R, corrupted CIFAR-10C, real-world ATM predictive maintenance and SMAP unsupervised anomaly detection benchmarks show that the proposed ContextFlow++ offers faster stable training and achieves higher performance metrics. Our code is publicly available at https://github.com/gudovskiy/contextflow.
VeCAF: VLM-empowered Collaborative Active Finetuning with Training Objective Awareness
Jan 15, 2024Finetuning a pretrained vision model (PVM) is a common technique for learning downstream vision tasks. The conventional finetuning process with the randomly sampled data points results in diminished training efficiency. To address this drawback, we propose a novel approach, VLM-empowered Collaborative Active Finetuning (VeCAF). VeCAF optimizes a parametric data selection model by incorporating the training objective of the model being tuned. Effectively, this guides the PVM towards the performance goal with improved data and computational efficiency. As vision-language models (VLMs) have achieved significant advancements by establishing a robust connection between image and language domains, we exploit the inherent semantic richness of the text embedding space and utilize text embedding of pretrained VLM models to augment PVM image features for better data selection and finetuning. Furthermore, the flexibility of text-domain augmentation gives VeCAF a unique ability to handle out-of-distribution scenarios without external augmented data. Extensive experiments show the leading performance and high efficiency of VeCAF that is superior to baselines in both in-distribution and out-of-distribution image classification tasks. On ImageNet, VeCAF needs up to 3.3x less training batches to reach the target performance compared to full finetuning and achieves 2.8% accuracy improvement over SOTA methods with the same number of batches.
Efficient Deweather Mixture-of-Experts with Uncertainty-aware Feature-wise Linear Modulation
Dec 27, 2023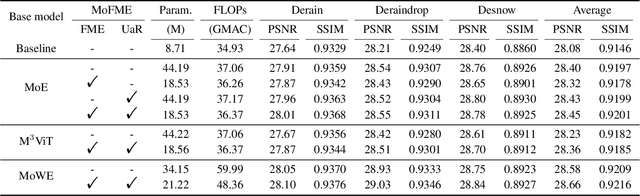
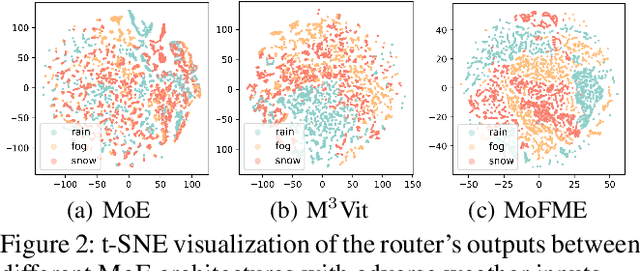
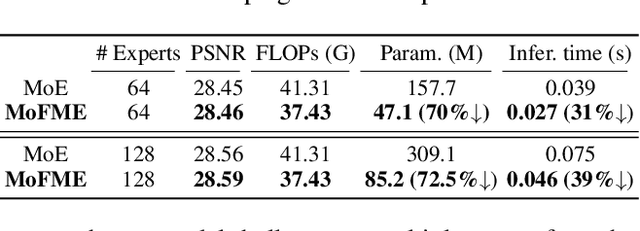
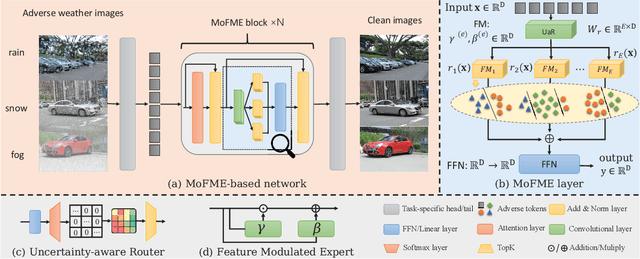
The Mixture-of-Experts (MoE) approach has demonstrated outstanding scalability in multi-task learning including low-level upstream tasks such as concurrent removal of multiple adverse weather effects. However, the conventional MoE architecture with parallel Feed Forward Network (FFN) experts leads to significant parameter and computational overheads that hinder its efficient deployment. In addition, the naive MoE linear router is suboptimal in assigning task-specific features to multiple experts which limits its further scalability. In this work, we propose an efficient MoE architecture with weight sharing across the experts. Inspired by the idea of linear feature modulation (FM), our architecture implicitly instantiates multiple experts via learnable activation modulations on a single shared expert block. The proposed Feature Modulated Expert (FME) serves as a building block for the novel Mixture-of-Feature-Modulation-Experts (MoFME) architecture, which can scale up the number of experts with low overhead. We further propose an Uncertainty-aware Router (UaR) to assign task-specific features to different FM modules with well-calibrated weights. This enables MoFME to effectively learn diverse expert functions for multiple tasks. The conducted experiments on the multi-deweather task show that our MoFME outperforms the baselines in the image restoration quality by 0.1-0.2 dB and achieves SOTA-compatible performance while saving more than 72% of parameters and 39% inference time over the conventional MoE counterpart. Experiments on the downstream segmentation and classification tasks further demonstrate the generalizability of MoFME to real open-world applications.
Split-Ensemble: Efficient OOD-aware Ensemble via Task and Model Splitting
Dec 14, 2023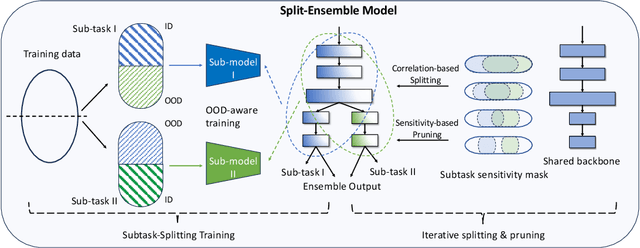
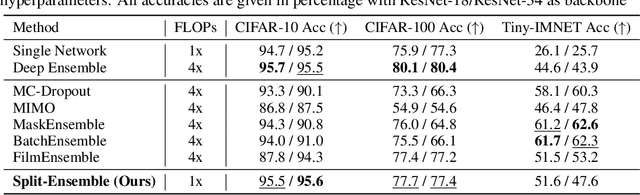
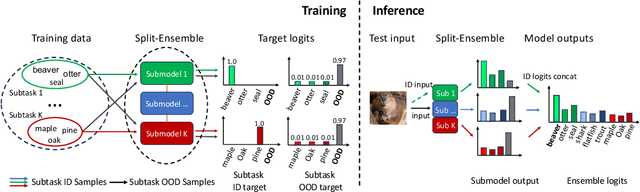
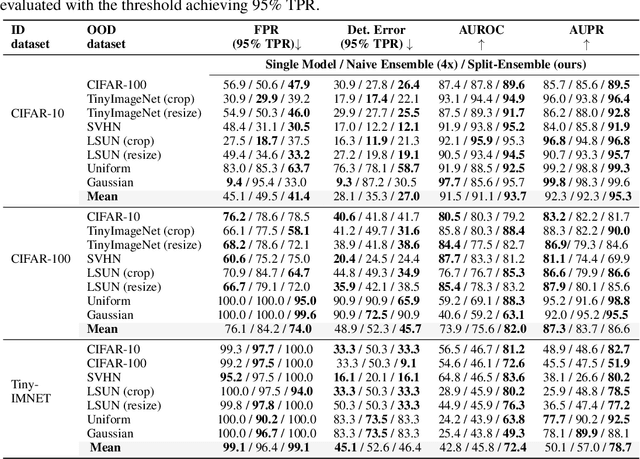
Uncertainty estimation is crucial for machine learning models to detect out-of-distribution (OOD) inputs. However, the conventional discriminative deep learning classifiers produce uncalibrated closed-set predictions for OOD data. A more robust classifiers with the uncertainty estimation typically require a potentially unavailable OOD dataset for outlier exposure training, or a considerable amount of additional memory and compute to build ensemble models. In this work, we improve on uncertainty estimation without extra OOD data or additional inference costs using an alternative Split-Ensemble method. Specifically, we propose a novel subtask-splitting ensemble training objective, where a common multiclass classification task is split into several complementary subtasks. Then, each subtask's training data can be considered as OOD to the other subtasks. Diverse submodels can therefore be trained on each subtask with OOD-aware objectives. The subtask-splitting objective enables us to share low-level features across submodels to avoid parameter and computational overheads. In particular, we build a tree-like Split-Ensemble architecture by performing iterative splitting and pruning from a shared backbone model, where each branch serves as a submodel corresponding to a subtask. This leads to improved accuracy and uncertainty estimation across submodels under a fixed ensemble computation budget. Empirical study with ResNet-18 backbone shows Split-Ensemble, without additional computation cost, improves accuracy over a single model by 0.8%, 1.8%, and 25.5% on CIFAR-10, CIFAR-100, and Tiny-ImageNet, respectively. OOD detection for the same backbone and in-distribution datasets surpasses a single model baseline by, correspondingly, 2.2%, 8.1%, and 29.6% mean AUROC. Codes will be publicly available at https://antonioo-c.github.io/projects/split-ensemble
Concurrent Misclassification and Out-of-Distribution Detection for Semantic Segmentation via Energy-Based Normalizing Flow
May 16, 2023Recent semantic segmentation models accurately classify test-time examples that are similar to a training dataset distribution. However, their discriminative closed-set approach is not robust in practical data setups with distributional shifts and out-of-distribution (OOD) classes. As a result, the predicted probabilities can be very imprecise when used as confidence scores at test time. To address this, we propose a generative model for concurrent in-distribution misclassification (IDM) and OOD detection that relies on a normalizing flow framework. The proposed flow-based detector with an energy-based inputs (FlowEneDet) can extend previously deployed segmentation models without their time-consuming retraining. Our FlowEneDet results in a low-complexity architecture with marginal increase in the memory footprint. FlowEneDet achieves promising results on Cityscapes, Cityscapes-C, FishyScapes and SegmentMeIfYouCan benchmarks in IDM/OOD detection when applied to pretrained DeepLabV3+ and SegFormer semantic segmentation models.
Cross-Domain Object Detection with Mean-Teacher Transformer
May 03, 2022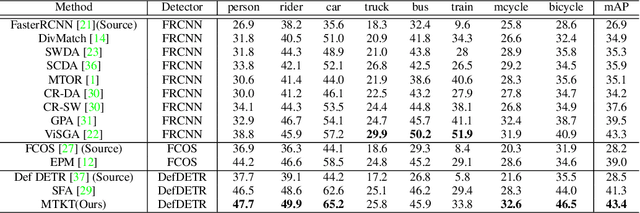
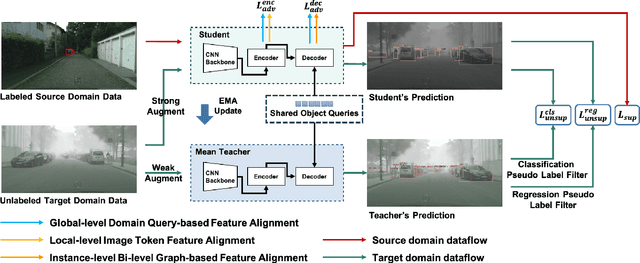
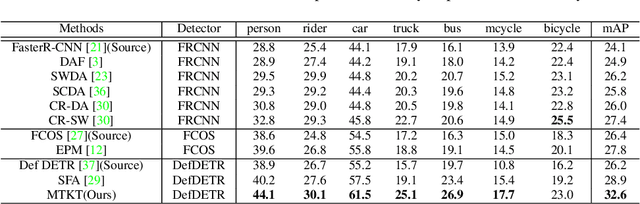
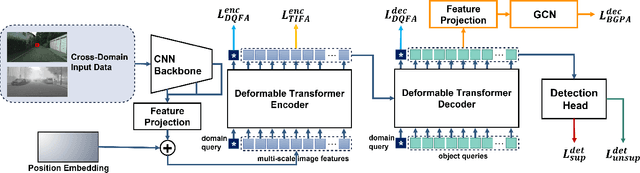
Recently, DEtection TRansformer (DETR), an end-to-end object detection pipeline, has achieved promising performance. However, it requires large-scale labeled data and suffers from domain shift, especially when no labeled data is available in the target domain. To solve this problem, we propose an end-to-end cross-domain detection transformer based on the mean teacher knowledge transfer (MTKT), which transfers knowledge between domains via pseudo labels. To improve the quality of pseudo labels in the target domain, which is a crucial factor for better domain adaptation, we design three levels of source-target feature alignment strategies based on the architecture of the Transformer, including domain query-based feature alignment (DQFA), bi-level-graph-based prototype alignment (BGPA), and token-wise image feature alignment (TIFA). These three levels of feature alignment match the global, local, and instance features between source and target, respectively. With these strategies, more accurate pseudo labels can be obtained, and knowledge can be better transferred from source to target, thus improving the cross-domain capability of the detection transformer. Extensive experiments demonstrate that our proposed method achieves state-of-the-art performance on three domain adaptation scenarios, especially the result of Sim10k to Cityscapes scenario is remarkably improved from 52.6 mAP to 57.9 mAP. Code will be released.
RandomNet: Towards Fully Automatic Neural Architecture Design for Multimodal Learning
Mar 02, 2020
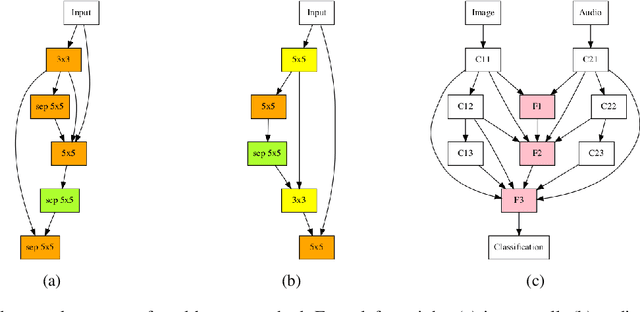

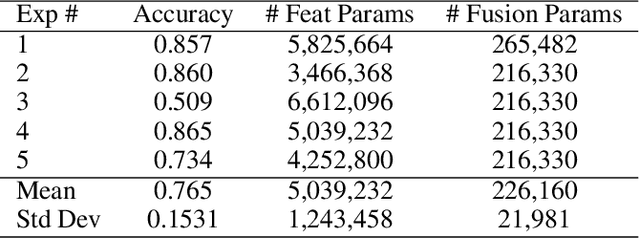
Almost all neural architecture search methods are evaluated in terms of performance (i.e. test accuracy) of the model structures that it finds. Should it be the only metric for a good autoML approach? To examine aspects beyond performance, we propose a set of criteria aimed at evaluating the core of autoML problem: the amount of human intervention required to deploy these methods into real world scenarios. Based on our proposed evaluation checklist, we study the effectiveness of a random search strategy for fully automated multimodal neural architecture search. Compared to traditional methods that rely on manually crafted feature extractors, our method selects each modality from a large search space with minimal human supervision. We show that our proposed random search strategy performs close to the state of the art on the AV-MNIST dataset while meeting the desirable characteristics for a fully automated design process.