 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomNet: Towards Fully Automatic Neural Architecture Design for Multimodal Learning
Paper and Code
Mar 02, 2020
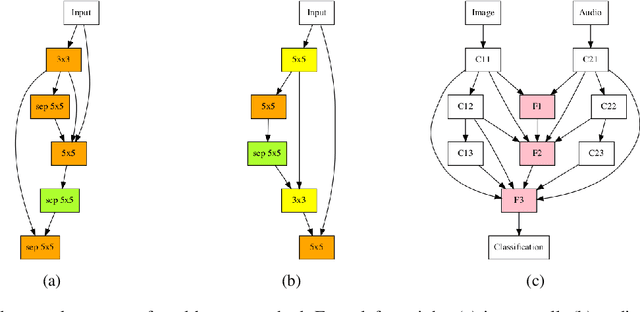

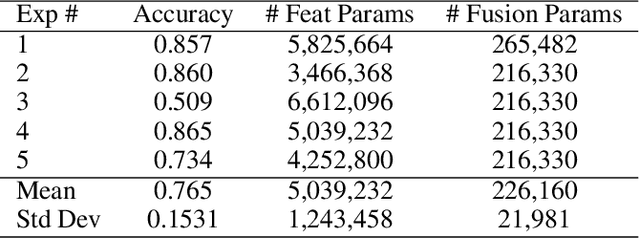
Almost all neural architecture search methods are evaluated in terms of performance (i.e. test accuracy) of the model structures that it finds. Should it be the only metric for a good autoML approach? To examine aspects beyond performance, we propose a set of criteria aimed at evaluating the core of autoML problem: the amount of human intervention required to deploy these methods into real world scenarios. Based on our proposed evaluation checklist, we study the effectiveness of a random search strategy for fully automated multimodal neural architecture search. Compared to traditional methods that rely on manually crafted feature extractors, our method selects each modality from a large search space with minimal human supervision. We show that our proposed random search strategy performs close to the state of the art on the AV-MNIST dataset while meeting the desirable characteristics for a fully automated design process.