 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving generalization in reinforcement learning through forked agents
Dec 14, 2022An eco-system of agents each having their own policy with some, but limited, generalizability has proven to be a reliable approach to increase generalization across procedurally generated environments. In such an approach, new agents are regularly added to the eco-system when encountering a new environment that is outside of the scope of the eco-system. The speed of adaptation and general effectiveness of the eco-system approach highly depends on the initialization of new agents. In this paper we propose different techniques for such initialization and study their impact.
Improving adaptability to new environments and removing catastrophic forgetting in Reinforcement Learning by using an eco-system of agents
Apr 13, 2022

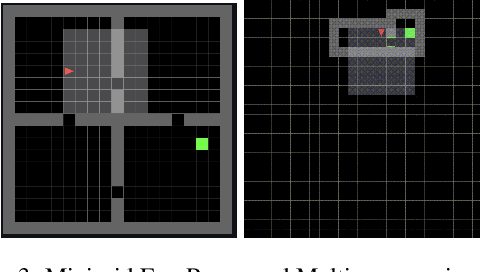
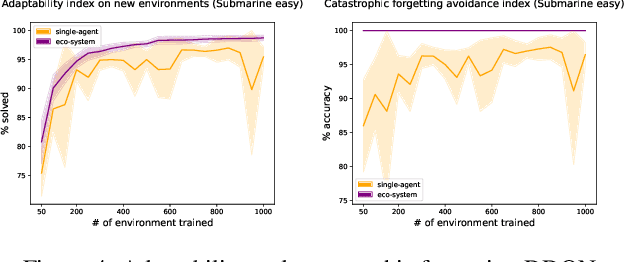
Adapting a Reinforcement Learning (RL) agent to an unseen environment is a difficult task due to typical over-fitting on the training environment. RL agents are often capable of solving environments very close to the trained environment, but when environments become substantially different, their performance quickly drops. When agents are retrained on new environments, a second issue arises: there is a risk of catastrophic forgetting, where the performance on previously seen environments is seriously hampered. This paper proposes a novel approach that exploits an ecosystem of agents to address both concerns. Hereby, the (limited) adaptive power of individual agents is harvested to build a highly adaptive ecosystem. This allows to transfer part of the workload from learning to inference. An evaluation of the approach on two distinct distributions of environments shows that our approach outperforms state-of-the-art techniques in terms of adaptability/generalization as well as avoids catastrophic forgetting.
A Machine With Human-Like Memory Systems
Apr 04, 2022
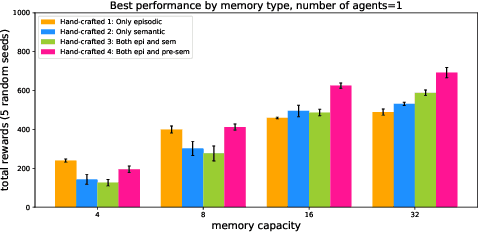
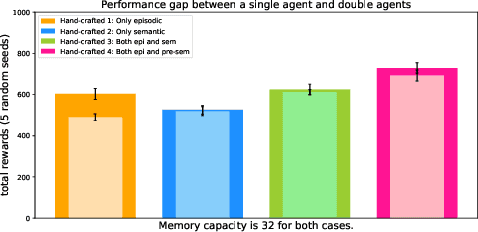
Inspired by the cognitive science theory, we explicitly model an agent with both semantic and episodic memory systems, and show that it is better than having just one of the two memory systems. In order to show this, we have designed and released our own challenging environment, "the Room", compatible with OpenAI Gym, where an agent has to properly learn how to encode, store, and retrieve memories to maximize its rewards. The Room environment allows for a hybrid intelligence setup where machines and humans can collaborate. We show that two agents collaborating with each other results in better performance than one agent acting alone. We have open-sourced our code and models at https://github.com/tae898/explicit-memory.
Component Transfer Learning for Deep RL Based on Abstract Representations
Nov 22, 2021

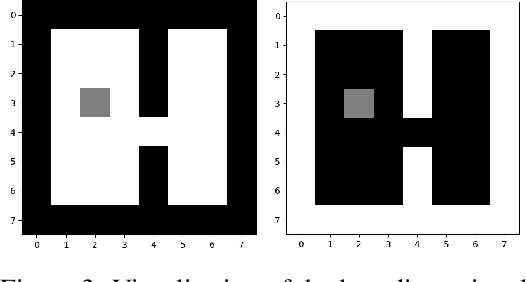

In this work we investigate a specific transfer learning approach for deep reinforcement learning in the context where the internal dynamics between two tasks are the same but the visual representations differ. We learn a low-dimensional encoding of the environment, meant to capture summarizing abstractions, from which the internal dynamics and value functions are learned. Transfer is then obtained by freezing the learned internal dynamics and value functions, thus reusing the shared low-dimensional embedding space. When retraining the encoder for transfer, we make several observations: (i) in some cases, there are local minima that have small losses but a mismatching embedding space, resulting in poor task performance and (ii) in the absence of local minima, the output of the encoder converges in our experiments to the same embedding space, which leads to a fast and efficient transfer as compared to learning from scratch. The local minima are caused by the reduced degree of freedom of the optimization process caused by the frozen models. We also find that the transfer performance is heavily reliant on the base model; some base models often result in a successful transfer, whereas other base models often result in a failing transfer.
Deep Reinforcement Learning Versus Evolution Strategies: A Comparative Survey
Sep 28, 2021
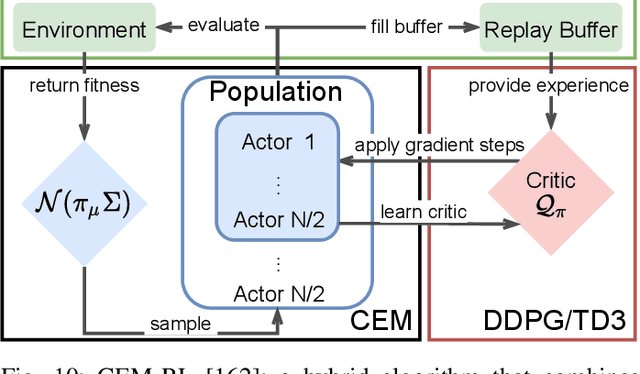
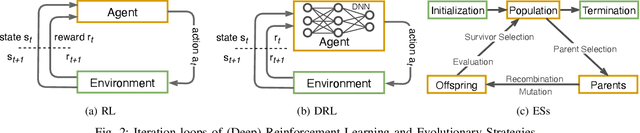
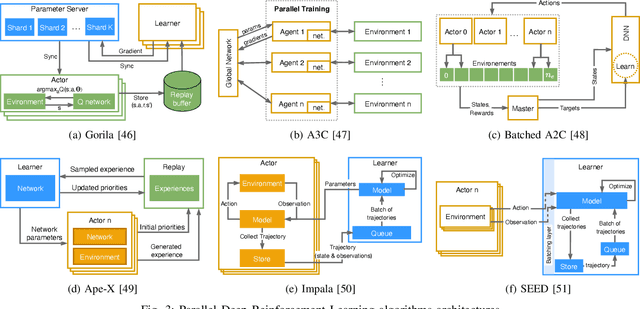
Deep Reinforcement Learning (DRL) and Evolution Strategies (ESs) have surpassed human-level control in many sequential decision-making problems, yet many open challenges still exist. To get insights into the strengths and weaknesses of DRL versus ESs, an analysis of their respective capabilities and limitations is provided. After presenting their fundamental concepts and algorithms, a comparison is provided on key aspects such as scalability, exploration, adaptation to dynamic environments, and multi-agent learning. Then, the benefits of hybrid algorithms that combine concepts from DRL and ESs are highlighted. Finally, to have an indication about how they compare in real-world applications, a survey of the literature for the set of applications they support is provided.
RandomNet: Towards Fully Automatic Neural Architecture Design for Multimodal Learning
Mar 02, 2020
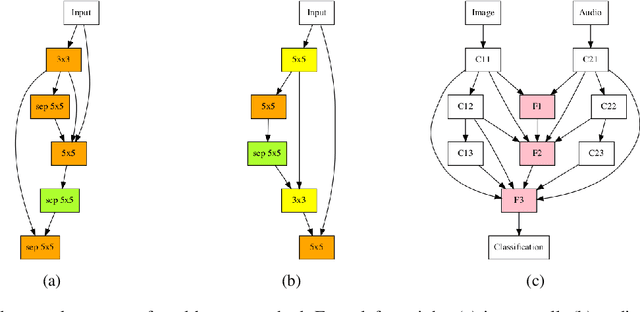

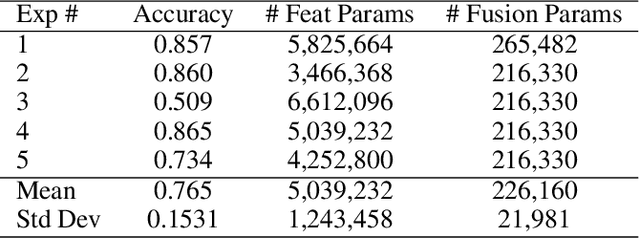
Almost all neural architecture search methods are evaluated in terms of performance (i.e. test accuracy) of the model structures that it finds. Should it be the only metric for a good autoML approach? To examine aspects beyond performance, we propose a set of criteria aimed at evaluating the core of autoML problem: the amount of human intervention required to deploy these methods into real world scenarios. Based on our proposed evaluation checklist, we study the effectiveness of a random search strategy for fully automated multimodal neural architecture search. Compared to traditional methods that rely on manually crafted feature extractors, our method selects each modality from a large search space with minimal human supervision. We show that our proposed random search strategy performs close to the state of the art on the AV-MNIST dataset while meeting the desirable characteristics for a fully automated design process.
An Introduction to Deep Reinforcement Learning
Dec 03, 2018
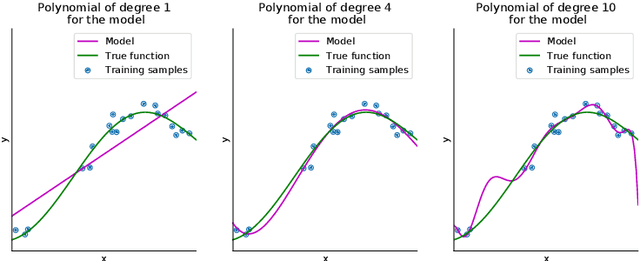
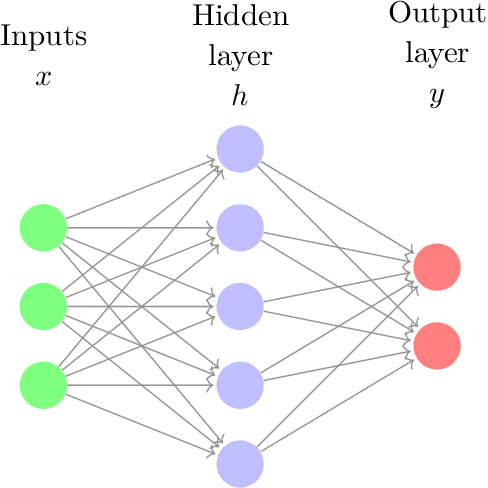
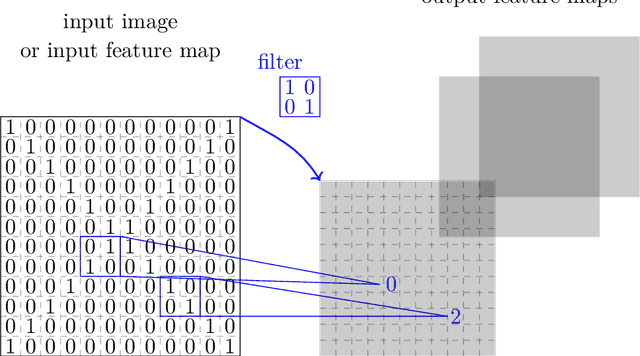
Deep reinforcement learning is the combination of reinforcement learning (RL) and deep learning. This field of research has been able to solve a wide range of complex decision-making tasks that were previously out of reach for a machine. Thus, deep RL opens up many new applications in domains such as healthcare, robotics, smart grids, finance, and many more. This manuscript provides an introduction to deep reinforcement learning models, algorithms and techniques. Particular focus is on the aspects related to generalization and how deep RL can be used for practical applications. We assume the reader is familiar with basic machine learning concepts.
Reward Estimation for Variance Reduction in Deep Reinforcement Learning
May 09, 2018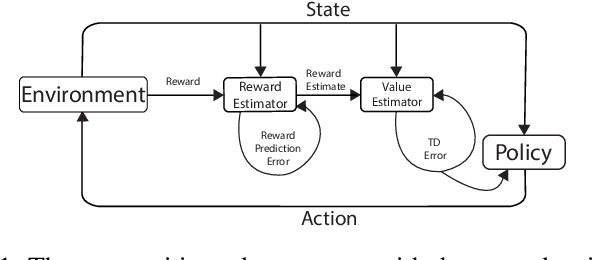
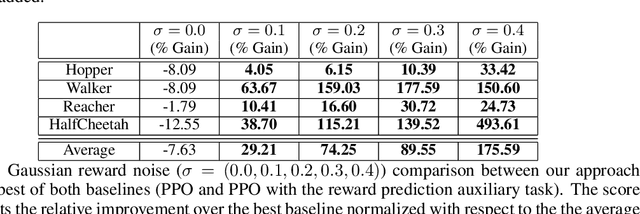
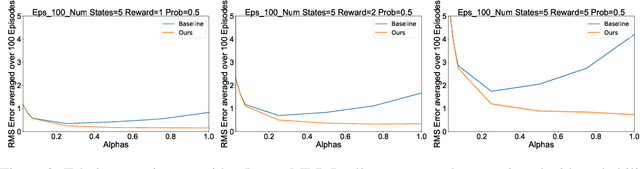

In reinforcement learning (RL), stochastic environments can make learning a policy difficult due to high degrees of variance. As such, variance reduction methods have been investigated in other works, such as advantage estimation and control-variates estimation. Here, we propose to learn a separate reward estimator to train the value function, to help reduce variance caused by a noisy reward signal. This results in theoretical reductions in variance in the tabular case, as well as empirical improvements in both the function approximation and tabular settings in environments where rewards are stochastic. To do so, we use a modified version of Advantage Actor Critic (A2C) on variations of Atari games.
On overfitting and asymptotic bias in batch reinforcement learning with partial observability
Sep 22, 2017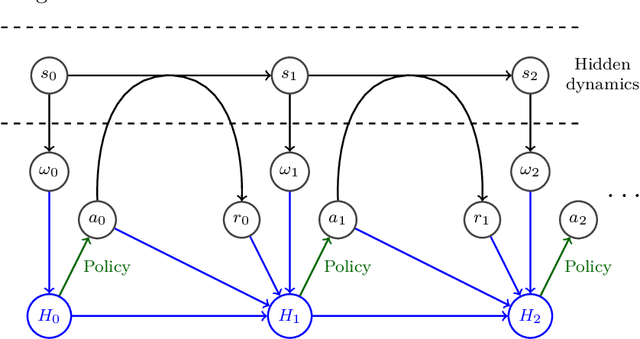

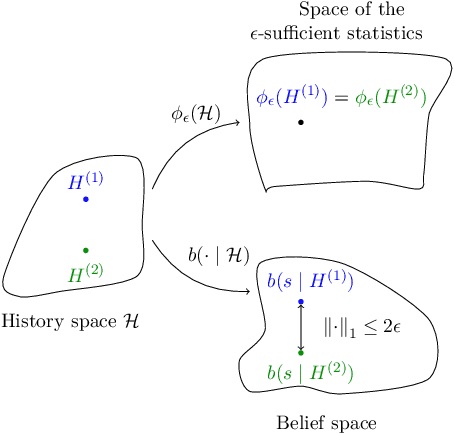
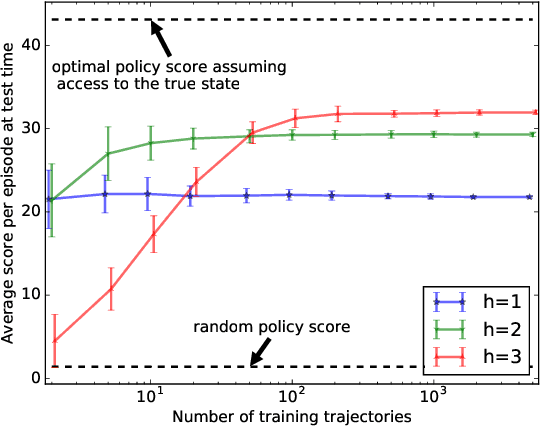
This paper stands in the context of reinforcement learning with partial observability and limited data. In this setting, we focus on the tradeoff between asymptotic bias (suboptimality with unlimited data) and overfitting (additional suboptimality due to limited data), and theoretically show that while potentially increasing the asymptotic bias, a smaller state representation decreases the risk of overfitting. Our analysis relies on expressing the quality of a state representation by bounding L1 error terms of the associated belief states. Theoretical results are empirically illustrated when the state representation is a truncated history of observations. Finally, we also discuss and empirically illustrate how using function approximators and adapting the discount factor may enhance the tradeoff between asymptotic bias and overfitting.