 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Evolving Curriculum for LLM Reasoning
May 20, 2025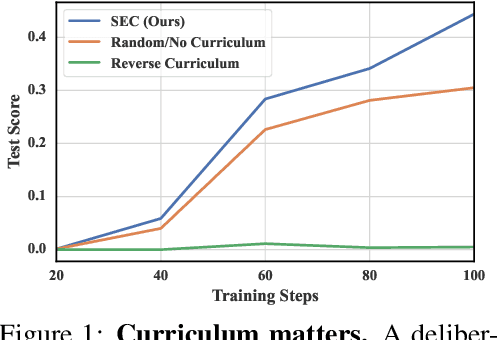
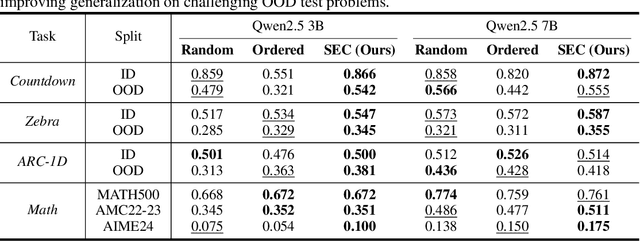
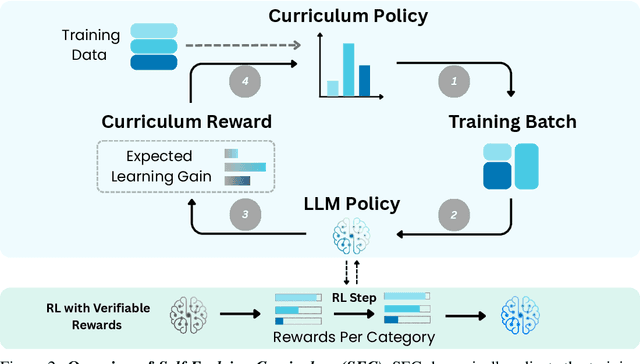
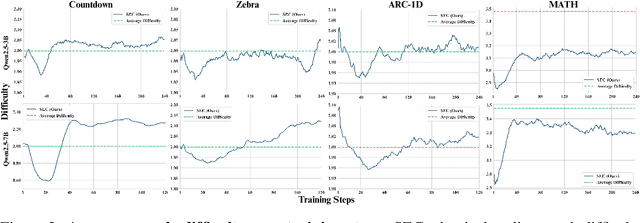
Reinforcement learning (RL) has proven effective for fine-tuning large language models (LLMs), significantly enhancing their reasoning abilities in domains such as mathematics and code generation. A crucial factor influencing RL fine-tuning success is the training curriculum: the order in which training problems are presented. While random curricula serve as common baselines, they remain suboptimal; manually designed curricula often rely heavily on heuristics, and online filtering methods can be computationally prohibitive. To address these limitations, we propose Self-Evolving Curriculum (SEC), an automatic curriculum learning method that learns a curriculum policy concurrently with the RL fine-tuning process. Our approach formulates curriculum selection as a non-stationary Multi-Armed Bandit problem, treating each problem category (e.g., difficulty level or problem type) as an individual arm. We leverage the absolute advantage from policy gradient methods as a proxy measure for immediate learning gain. At each training step, the curriculum policy selects categories to maximize this reward signal and is updated using the TD(0) method. Across three distinct reasoning domains: planning, inductive reasoning, and mathematics, our experiments demonstrate that SEC significantly improves models' reasoning capabilities, enabling better generalization to harder, out-of-distribution test problems. Additionally, our approach achieves better skill balance when fine-tuning simultaneously on multiple reasoning domains. These findings highlight SEC as a promising strategy for RL fine-tuning of LLMs.
LLMs can learn self-restraint through iterative self-reflection
May 15, 2024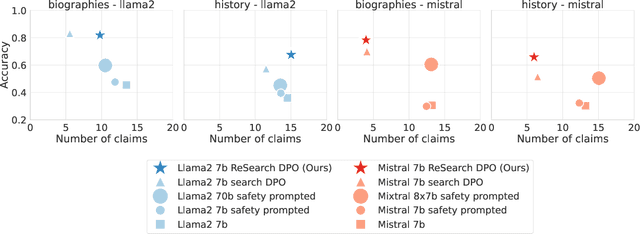

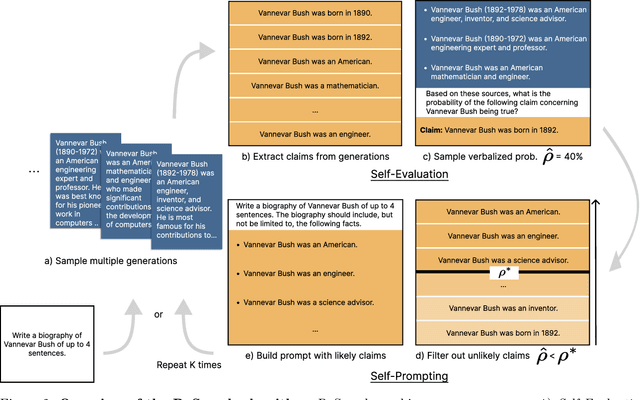

In order to be deployed safely, Large Language Models (LLMs) must be capable of dynamically adapting their behavior based on their level of knowledge and uncertainty associated with specific topics. This adaptive behavior, which we refer to as self-restraint, is non-trivial to teach since it depends on the internal knowledge of an LLM. By default, LLMs are trained to maximize the next token likelihood, which does not teach the model to modulate its answer based on its level of uncertainty. In order to learn self-restraint, we devise a utility function that can encourage the model to produce responses only when it is confident in them. This utility function can be used to score generation of different length and abstention. To optimize this function, we introduce ReSearch, a process of ``self-reflection'' consisting of iterative self-prompting and self-evaluation. We use the ReSearch algorithm to generate synthetic data on which we finetune our models. Compared to their original versions, our resulting models generate fewer \emph{hallucinations} overall at no additional inference cost, for both known and unknown topics, as the model learns to selectively restrain itself. In addition, our method elegantly incorporates the ability to abstain by augmenting the samples generated by the model during the search procedure with an answer expressing abstention.
Causal Discovery with Language Models as Imperfect Experts
Jul 05, 2023



Understanding the causal relationships that underlie a system is a fundamental prerequisite to accurate decision-making. In this work, we explore how expert knowledge can be used to improve the data-driven identification of causal graphs, beyond Markov equivalence classes. In doing so, we consider a setting where we can query an expert about the orientation of causal relationships between variables, but where the expert may provide erroneous information. We propose strategies for amending such expert knowledge based on consistency properties, e.g., acyclicity and conditional independencies in the equivalence class. We then report a case study, on real data, where a large language model is used as an imperfect expert.
Can large language models build causal graphs?
Mar 07, 2023



Building causal graphs can be a laborious process. To ensure all relevant causal pathways have been captured, researchers often have to discuss with clinicians and experts while also reviewing extensive relevant medical literature. By encoding common and medical knowledge, large language models (LLMs) represent an opportunity to ease this process by automatically scoring edges (i.e., connections between two variables) in potential graphs. LLMs however have been shown to be brittle to the choice of probing words, context, and prompts that the user employs. In this work, we evaluate if LLMs can be a useful tool in complementing causal graph development.
Unsupervised Model-based Pre-training for Data-efficient Control from Pixels
Sep 24, 2022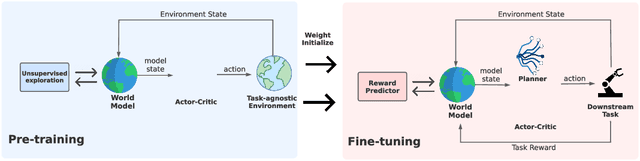
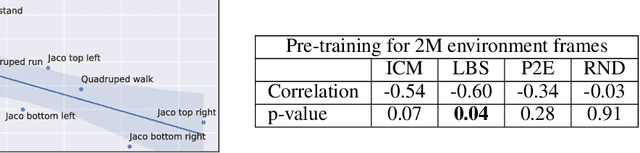
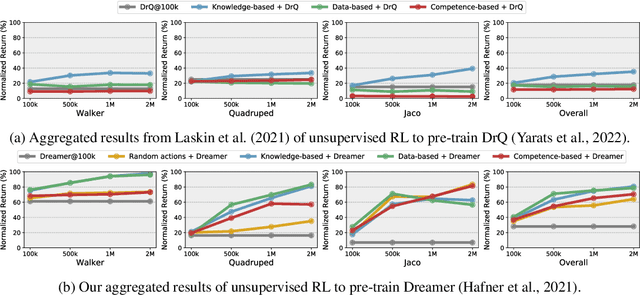
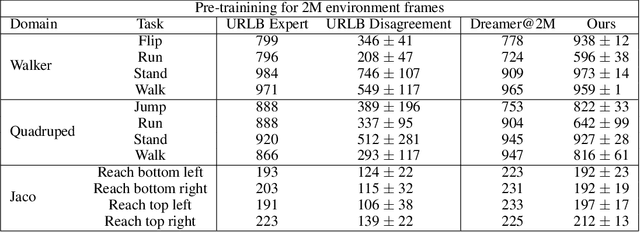
Controlling artificial agents from visual sensory data is an arduous task. Reinforcement learning (RL) algorithms can succeed in this but require large amounts of interactions between the agent and the environment. To alleviate the issue, unsupervised RL proposes to employ self-supervised interaction and learning, for adapting faster to future tasks. Yet, whether current unsupervised strategies improve generalization capabilities is still unclear, especially in visual control settings. In this work, we design an effective unsupervised RL strategy for data-efficient visual control. First, we show that world models pre-trained with data collected using unsupervised RL can facilitate adaptation for future tasks. Then, we analyze several design choices to adapt efficiently, effectively reusing the agents' pre-trained components, and learning and planning in imagination, with our hybrid planner, which we dub Dyna-MPC. By combining the findings of a large-scale empirical study, we establish an approach that strongly improves performance on the Unsupervised RL Benchmark, requiring 20$\times$ less data to match the performance of supervised methods. The approach also demonstrates robust performance on the Real-Word RL benchmark, hinting that the approach generalizes to noisy environments.
Beyond Target Networks: Improving Deep $Q$-learning with Functional Regularization
Jun 07, 2021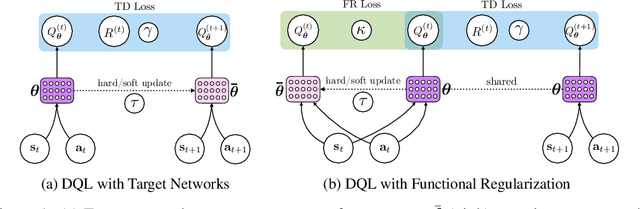
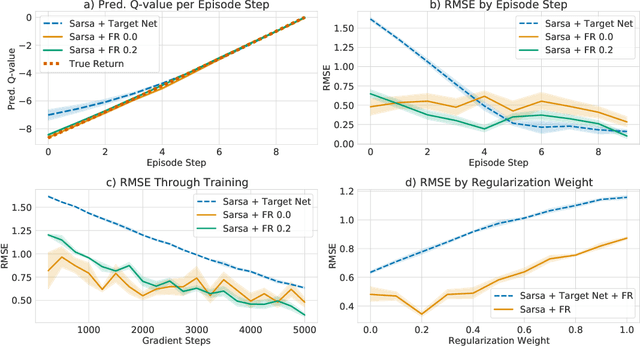

Target networks are at the core of recent success in Reinforcement Learning. They stabilize the training by using old parameters to estimate the $Q$-values, but this also limits the propagation of newly-encountered rewards which could ultimately slow down the training. In this work, we propose an alternative training method based on functional regularization which does not have this deficiency. Unlike target networks, our method uses up-to-date parameters to estimate the target $Q$-values, thereby speeding up training while maintaining stability. Surprisingly, in some cases, we can show that target networks are a special, restricted type of functional regularizers. Using this approach, we show empirical improvements in sample efficiency and performance across a range of Atari and simulated robotics environments.
Iterative Amortized Policy Optimization
Oct 20, 2020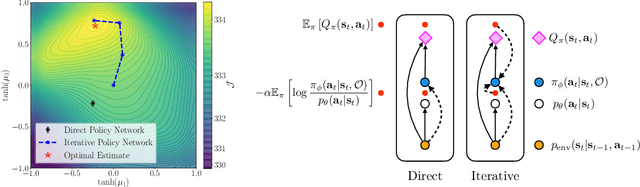
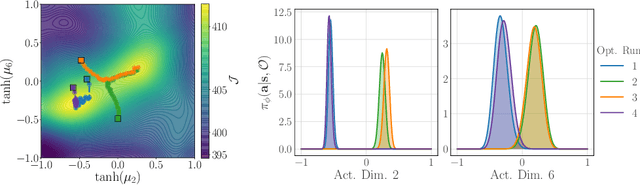
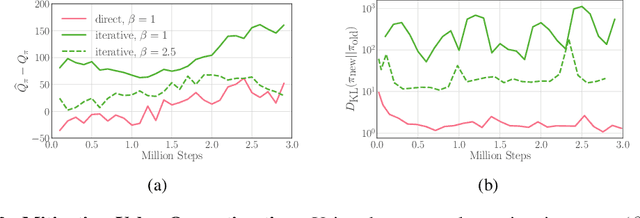
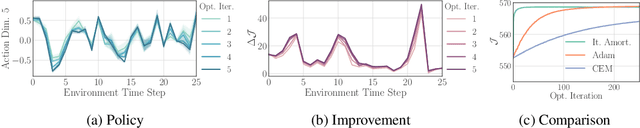
Policy networks are a central feature of deep reinforcement learning (RL) algorithms for continuous control, enabling the estimation and sampling of high-value actions. From the variational inference perspective on RL, policy networks, when employed with entropy or KL regularization, are a form of amortized optimization, optimizing network parameters rather than the policy distributions directly. However, this direct amortized mapping can empirically yield suboptimal policy estimates. Given this perspective, we consider the more flexible class of iterative amortized optimizers. We demonstrate that the resulting technique, iterative amortized policy optimization, yields performance improvements over conventional direct amortization methods on benchmark continuous control tasks.
Adaptive Stochastic Dual Coordinate Ascent for Conditional Random Fields
Jul 10, 2018



This work investigates the training of conditional random fields (CRFs) via the stochastic dual coordinate ascent (SDCA) algorithm of Shalev-Shwartz and Zhang (2016). SDCA enjoys a linear convergence rate and a strong empirical performance for binary classification problems. However, it has never been used to train CRFs. Yet it benefits from an `exact' line search with a single marginalization oracle call, unlike previous approaches. In this paper, we adapt SDCA to train CRFs, and we enhance it with an adaptive non-uniform sampling strategy based on block duality gaps. We perform experiments on four standard sequence prediction tasks. SDCA demonstrates performances on par with the state of the art, and improves over it on three of the four datasets, which have in common the use of sparse features.
Reward Estimation for Variance Reduction in Deep Reinforcement Learning
May 09, 2018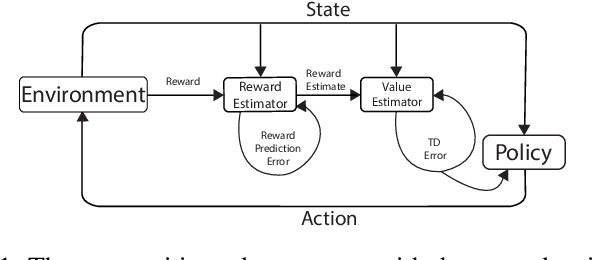
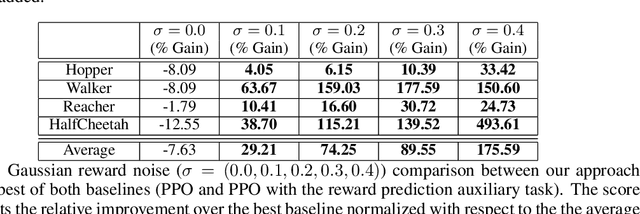
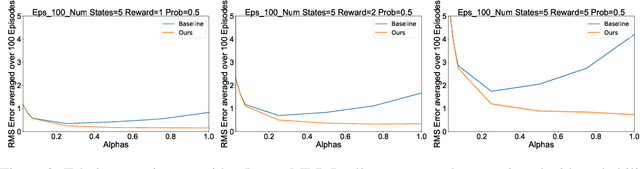

In reinforcement learning (RL), stochastic environments can make learning a policy difficult due to high degrees of variance. As such, variance reduction methods have been investigated in other works, such as advantage estimation and control-variates estimation. Here, we propose to learn a separate reward estimator to train the value function, to help reduce variance caused by a noisy reward signal. This results in theoretical reductions in variance in the tabular case, as well as empirical improvements in both the function approximation and tabular settings in environments where rewards are stochastic. To do so, we use a modified version of Advantage Actor Critic (A2C) on variations of Atari games.
Bayesian Nonparametric Modeling of Heterogeneous Groups of Censored Data
Dec 02, 2016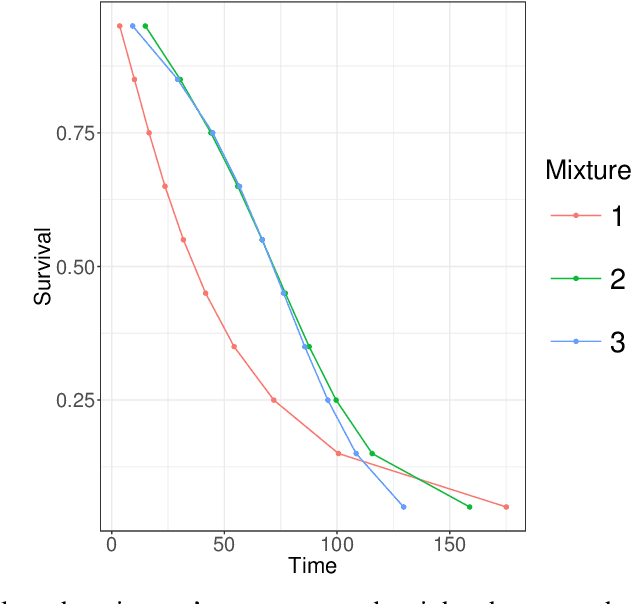
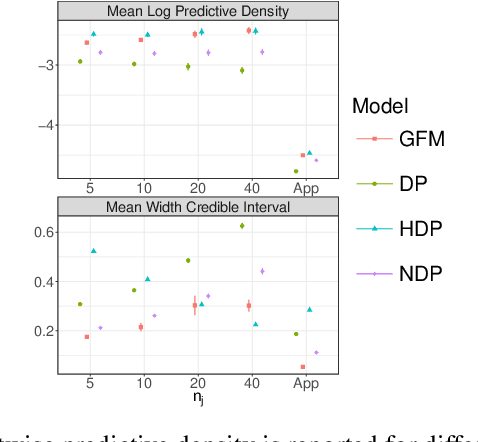
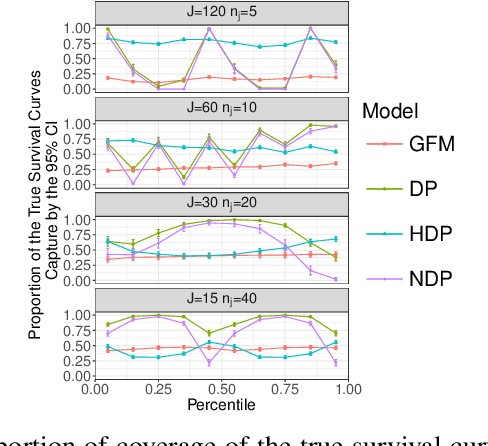

Datasets containing large samples of time-to-event data arising from several small heterogeneous groups are commonly encountered in statistics. This presents problems as they cannot be pooled directly due to their heterogeneity or analyzed individually because of their small sample size. Bayesian nonparametric modelling approaches can be used to model such datasets given their ability to flexibly share information across groups. In this paper, we will compare three popular Bayesian nonparametric methods for modelling the survival functions of heterogeneous groups. Specifically, we will first compare the modelling accuracy of the Dirichlet process, the hierarchical Dirichlet process, and the nested Dirichlet process on simulated datasets of different sizes, where group survival curves differ in shape or in expectation. We, then, will compare the models on a real-world injury dataset.