 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Conditional Diffusion Models for Forecasting Future Multiple Sclerosis Lesion Masks Conditioned on Treatments
Aug 09, 2025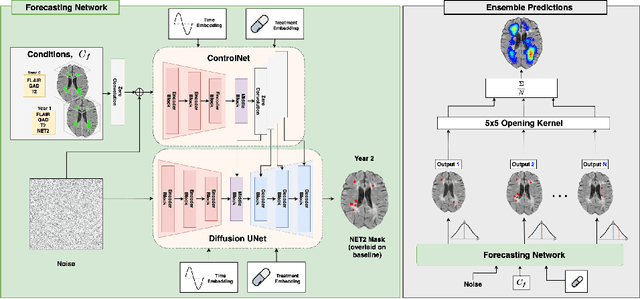
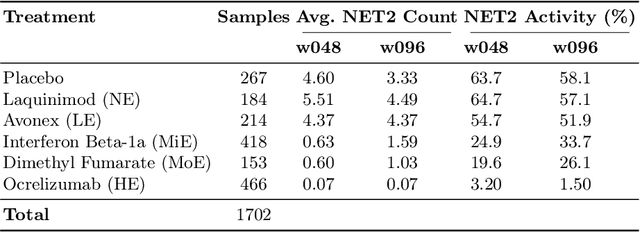
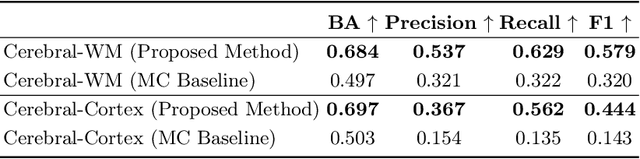
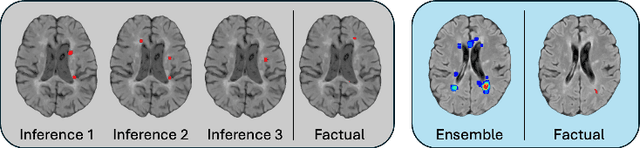
Image-based personalized medicine has the potential to transform healthcare, particularly for diseases that exhibit heterogeneous progression such as Multiple Sclerosis (MS). In this work, we introduce the first treatment-aware spatio-temporal diffusion model that is able to generate future masks demonstrating lesion evolution in MS. Our voxel-space approach incorporates multi-modal patient data, including MRI and treatment information, to forecast new and enlarging T2 (NET2) lesion masks at a future time point. Extensive experiments on a multi-centre dataset of 2131 patient 3D MRIs from randomized clinical trials for relapsing-remitting MS demonstrate that our generative model is able to accurately predict NET2 lesion masks for patients across six different treatments. Moreover, we demonstrate our model has the potential for real-world clinical applications through downstream tasks such as future lesion count and location estimation, binary lesion activity classification, and generating counterfactual future NET2 masks for several treatments with different efficacies. This work highlights the potential of causal, image-based generative models as powerful tools for advancing data-driven prognostics in MS.
The NaijaVoices Dataset: Cultivating Large-Scale, High-Quality, Culturally-Rich Speech Data for African Languages
May 26, 2025The development of high-performing, robust, and reliable speech technologies depends on large, high-quality datasets. However, African languages -- including our focus, Igbo, Hausa, and Yoruba -- remain under-represented due to insufficient data. Popular voice-enabled technologies do not support any of the 2000+ African languages, limiting accessibility for circa one billion people. While previous dataset efforts exist for the target languages, they lack the scale and diversity needed for robust speech models. To bridge this gap, we introduce the NaijaVoices dataset, a 1,800-hour speech-text dataset with 5,000+ speakers. We outline our unique data collection approach, analyze its acoustic diversity, and demonstrate its impact through finetuning experiments on automatic speech recognition, averagely achieving 75.86% (Whisper), 52.06% (MMS), and 42.33% (XLSR) WER improvements. These results highlight NaijaVoices' potential to advance multilingual speech processing for African languages.
CarbonSense: A Multimodal Dataset and Baseline for Carbon Flux Modelling
Jun 07, 2024



Terrestrial carbon fluxes provide vital information about our biosphere's health and its capacity to absorb anthropogenic CO$_2$ emissions. The importance of predicting carbon fluxes has led to the emerging field of data-driven carbon flux modelling (DDCFM), which uses statistical techniques to predict carbon fluxes from biophysical data. However, the field lacks a standardized dataset to promote comparisons between models. To address this gap, we present CarbonSense, the first machine learning-ready dataset for DDCFM. CarbonSense integrates measured carbon fluxes, meteorological predictors, and satellite imagery from 385 locations across the globe, offering comprehensive coverage and facilitating robust model training. Additionally, we provide a baseline model using a current state-of-the-art DDCFM approach and a novel transformer based model. Our experiments illustrate the potential gains that multimodal deep learning techniques can bring to this domain. By providing these resources, we aim to lower the barrier to entry for other deep learning researchers to develop new models and drive new advances in carbon flux modelling.
LLMs can learn self-restraint through iterative self-reflection
May 15, 2024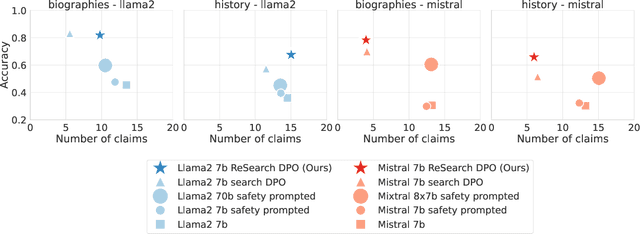

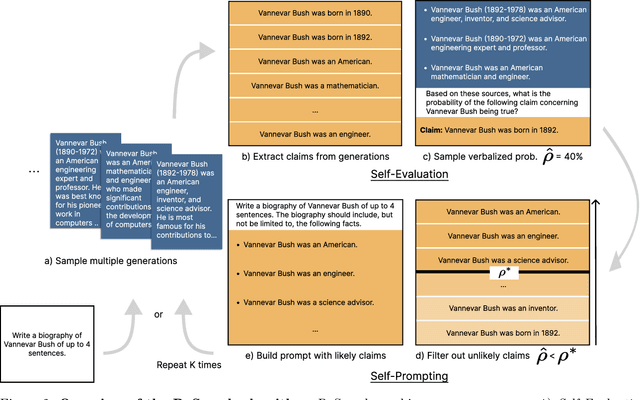

In order to be deployed safely, Large Language Models (LLMs) must be capable of dynamically adapting their behavior based on their level of knowledge and uncertainty associated with specific topics. This adaptive behavior, which we refer to as self-restraint, is non-trivial to teach since it depends on the internal knowledge of an LLM. By default, LLMs are trained to maximize the next token likelihood, which does not teach the model to modulate its answer based on its level of uncertainty. In order to learn self-restraint, we devise a utility function that can encourage the model to produce responses only when it is confident in them. This utility function can be used to score generation of different length and abstention. To optimize this function, we introduce ReSearch, a process of ``self-reflection'' consisting of iterative self-prompting and self-evaluation. We use the ReSearch algorithm to generate synthetic data on which we finetune our models. Compared to their original versions, our resulting models generate fewer \emph{hallucinations} overall at no additional inference cost, for both known and unknown topics, as the model learns to selectively restrain itself. In addition, our method elegantly incorporates the ability to abstain by augmenting the samples generated by the model during the search procedure with an answer expressing abstention.
Language Models Can Reduce Asymmetry in Information Markets
Mar 21, 2024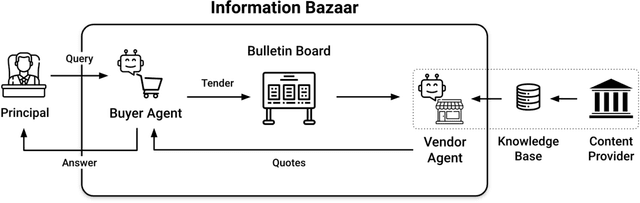

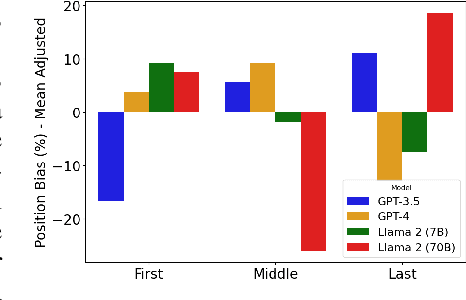
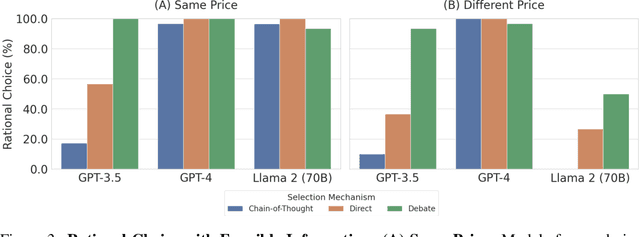
This work addresses the buyer's inspection paradox for information markets. The paradox is that buyers need to access information to determine its value, while sellers need to limit access to prevent theft. To study this, we introduce an open-source simulated digital marketplace where intelligent agents, powered by language models, buy and sell information on behalf of external participants. The central mechanism enabling this marketplace is the agents' dual capabilities: they not only have the capacity to assess the quality of privileged information but also come equipped with the ability to forget. This ability to induce amnesia allows vendors to grant temporary access to proprietary information, significantly reducing the risk of unauthorized retention while enabling agents to accurately gauge the information's relevance to specific queries or tasks. To perform well, agents must make rational decisions, strategically explore the marketplace through generated sub-queries, and synthesize answers from purchased information. Concretely, our experiments (a) uncover biases in language models leading to irrational behavior and evaluate techniques to mitigate these biases, (b) investigate how price affects demand in the context of informational goods, and (c) show that inspection and higher budgets both lead to higher quality outcomes.
ArK: Augmented Reality with Knowledge Interactive Emergent Ability
May 01, 2023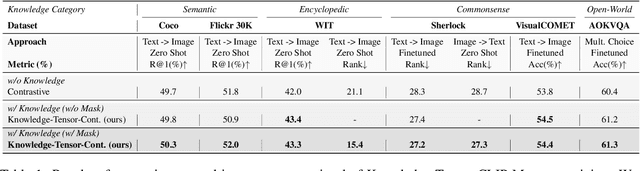
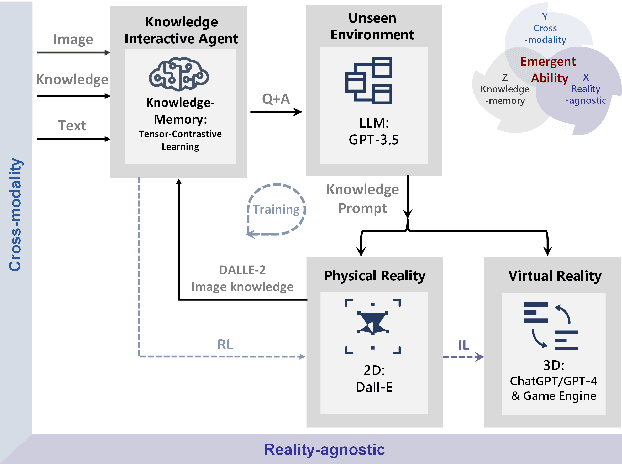

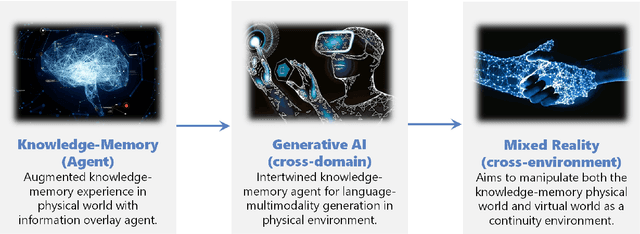
Despite the growing adoption of mixed reality and interactive AI agents, it remains challenging for these systems to generate high quality 2D/3D scenes in unseen environments. The common practice requires deploying an AI agent to collect large amounts of data for model training for every new task. This process is costly, or even impossible, for many domains. In this study, we develop an infinite agent that learns to transfer knowledge memory from general foundation models (e.g. GPT4, DALLE) to novel domains or scenarios for scene understanding and generation in the physical or virtual world. The heart of our approach is an emerging mechanism, dubbed Augmented Reality with Knowledge Inference Interaction (ArK), which leverages knowledge-memory to generate scenes in unseen physical world and virtual reality environments. The knowledge interactive emergent ability (Figure 1) is demonstrated as the observation learns i) micro-action of cross-modality: in multi-modality models to collect a large amount of relevant knowledge memory data for each interaction task (e.g., unseen scene understanding) from the physical reality; and ii) macro-behavior of reality-agnostic: in mix-reality environments to improve interactions that tailor to different characterized roles, target variables, collaborative information, and so on. We validate the effectiveness of ArK on the scene generation and editing tasks. We show that our ArK approach, combined with large foundation models, significantly improves the quality of generated 2D/3D scenes, compared to baselines, demonstrating the potential benefit of incorporating ArK in generative AI for applications such as metaverse and gaming simulation.
A General Purpose Neural Architecture for Geospatial Systems
Nov 04, 2022
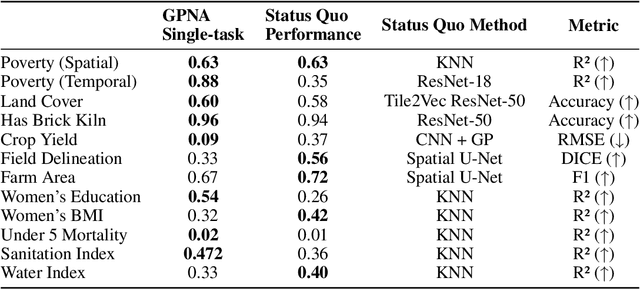
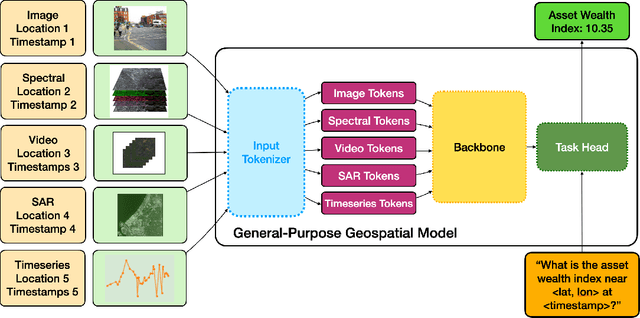
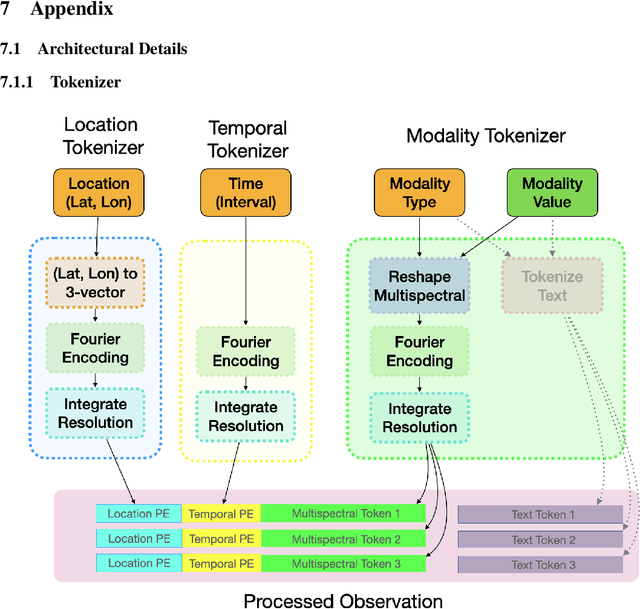
Geospatial Information Systems are used by researchers and Humanitarian Assistance and Disaster Response (HADR) practitioners to support a wide variety of important applications. However, collaboration between these actors is difficult due to the heterogeneous nature of geospatial data modalities (e.g., multi-spectral images of various resolutions, timeseries, weather data) and diversity of tasks (e.g., regression of human activity indicators or detecting forest fires). In this work, we present a roadmap towards the construction of a general-purpose neural architecture (GPNA) with a geospatial inductive bias, pre-trained on large amounts of unlabelled earth observation data in a self-supervised manner. We envision how such a model may facilitate cooperation between members of the community. We show preliminary results on the first step of the roadmap, where we instantiate an architecture that can process a wide variety of geospatial data modalities and demonstrate that it can achieve competitive performance with domain-specific architectures on tasks relating to the U.N.'s Sustainable Development Goals.
Neural Attentive Circuits
Oct 19, 2022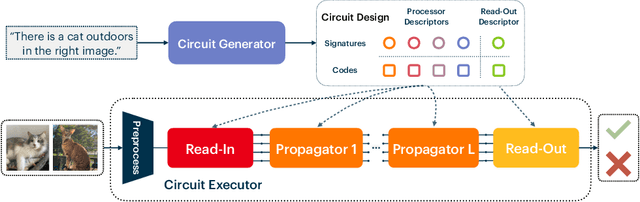
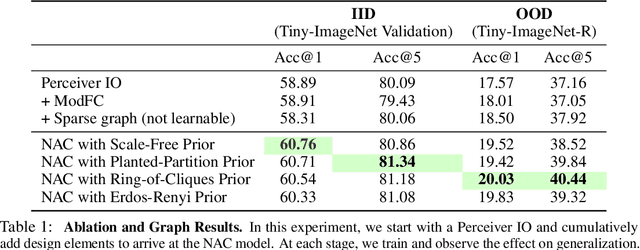
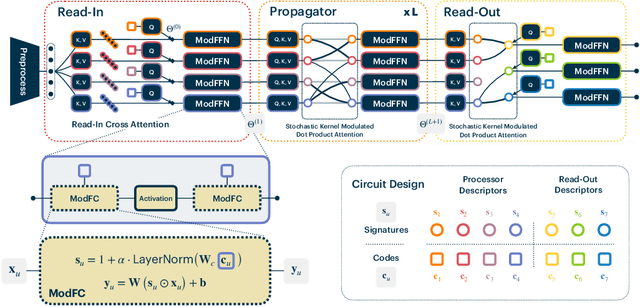

Recent work has seen the development of general purpose neural architectures that can be trained to perform tasks across diverse data modalities. General purpose models typically make few assumptions about the underlying data-structure and are known to perform well in the large-data regime. At the same time, there has been growing interest in modular neural architectures that represent the data using sparsely interacting modules. These models can be more robust out-of-distribution, computationally efficient, and capable of sample-efficient adaptation to new data. However, they tend to make domain-specific assumptions about the data, and present challenges in how module behavior (i.e., parameterization) and connectivity (i.e., their layout) can be jointly learned. In this work, we introduce a general purpose, yet modular neural architecture called Neural Attentive Circuits (NACs) that jointly learns the parameterization and a sparse connectivity of neural modules without using domain knowledge. NACs are best understood as the combination of two systems that are jointly trained end-to-end: one that determines the module configuration and the other that executes it on an input. We demonstrate qualitatively that NACs learn diverse and meaningful module configurations on the NLVR2 dataset without additional supervision. Quantitatively, we show that by incorporating modularity in this way, NACs improve upon a strong non-modular baseline in terms of low-shot adaptation on CIFAR and CUBs dataset by about 10%, and OOD robustness on Tiny ImageNet-R by about 2.5%. Further, we find that NACs can achieve an 8x speedup at inference time while losing less than 3% performance. Finally, we find NACs to yield competitive results on diverse data modalities spanning point-cloud classification, symbolic processing and text-classification from ASCII bytes, thereby confirming its general purpose nature.
Workflow Discovery from Dialogues in the Low Data Regime
May 24, 2022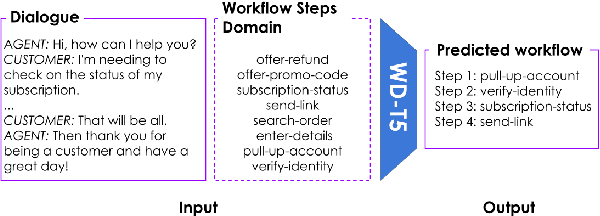

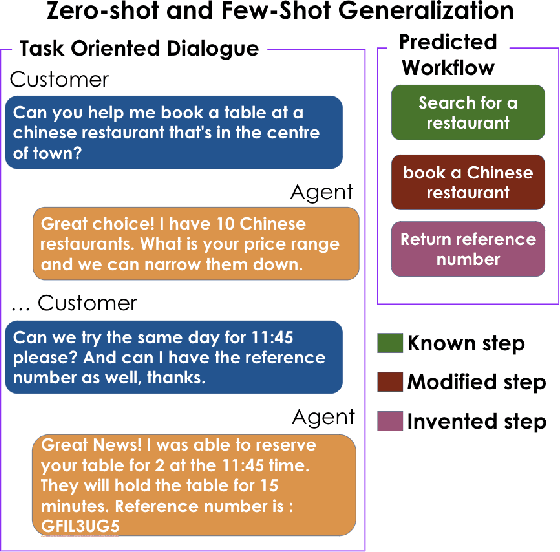

Text-based dialogues are now widely used to solve real-world problems. In cases where solution strategies are already known, they can sometimes be codified into workflows and used to guide humans or artificial agents through the task of helping clients. We are interested in the situation where a formal workflow may not yet exist, but we wish to discover the steps of actions that have been taken to resolve problems. We examine a novel transformer-based approach for this situation and we present experiments where we summarize dialogues in the Action-Based Conversations Dataset (ABCD) with workflows. Since the ABCD dialogues were generated using known workflows to guide agents we can evaluate our ability to extract such workflows using ground truth sequences of action steps, organized as workflows. We propose and evaluate an approach that conditions models on the set of allowable action steps and we show that using this strategy we can improve workflow discovery (WD) performance. Our conditioning approach also improves zero-shot and few-shot WD performance when transferring learned models to entirely new domains (i.e. the MultiWOZ setting). Further, a modified variant of our architecture achieves state-of-the-art performance on the related but different problems of Action State Tracking (AST) and Cascading Dialogue Success (CDS) on the ABCD.
Learned Image Compression for Machine Perception
Nov 03, 2021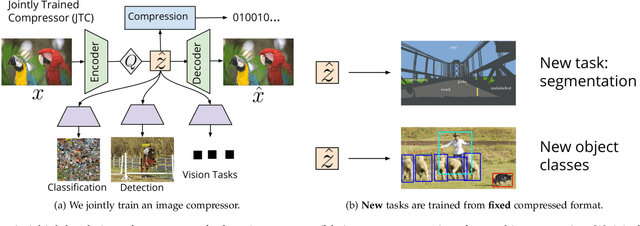
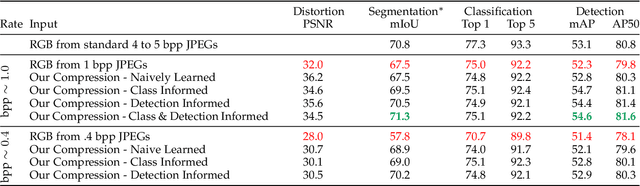
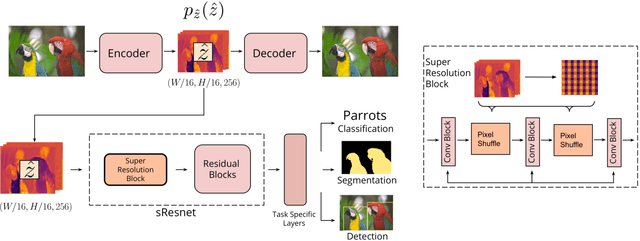

Recent work has shown that learned image compression strategies can outperform standard hand-crafted compression algorithms that have been developed over decades of intensive research on the rate-distortion trade-off. With growing applications of computer vision, high quality image reconstruction from a compressible representation is often a secondary objective. Compression that ensures high accuracy on computer vision tasks such as image segmentation, classification, and detection therefore has the potential for significant impact across a wide variety of settings. In this work, we develop a framework that produces a compression format suitable for both human perception and machine perception. We show that representations can be learned that simultaneously optimize for compression and performance on core vision tasks. Our approach allows models to be trained directly from compressed representations, and this approach yields increased performance on new tasks and in low-shot learning settings. We present results that improve upon segmentation and detection performance compared to standard high quality JPGs, but with representations that are four to ten times smaller in terms of bits per pixel. Further, unlike naive compression methods, at a level ten times smaller than standard JEPGs, segmentation and detection models trained from our format suffer only minor degradation in performance.