 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarbonSense: A Multimodal Dataset and Baseline for Carbon Flux Modelling
Jun 07, 2024



Terrestrial carbon fluxes provide vital information about our biosphere's health and its capacity to absorb anthropogenic CO$_2$ emissions. The importance of predicting carbon fluxes has led to the emerging field of data-driven carbon flux modelling (DDCFM), which uses statistical techniques to predict carbon fluxes from biophysical data. However, the field lacks a standardized dataset to promote comparisons between models. To address this gap, we present CarbonSense, the first machine learning-ready dataset for DDCFM. CarbonSense integrates measured carbon fluxes, meteorological predictors, and satellite imagery from 385 locations across the globe, offering comprehensive coverage and facilitating robust model training. Additionally, we provide a baseline model using a current state-of-the-art DDCFM approach and a novel transformer based model. Our experiments illustrate the potential gains that multimodal deep learning techniques can bring to this domain. By providing these resources, we aim to lower the barrier to entry for other deep learning researchers to develop new models and drive new advances in carbon flux modelling.
Simple and Scalable Strategies to Continually Pre-train Large Language Models
Mar 26, 2024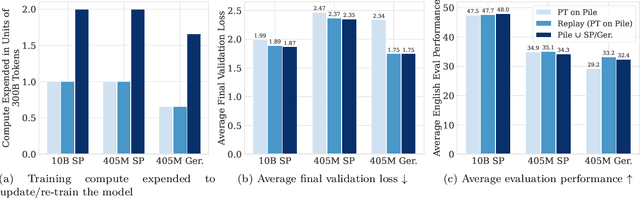
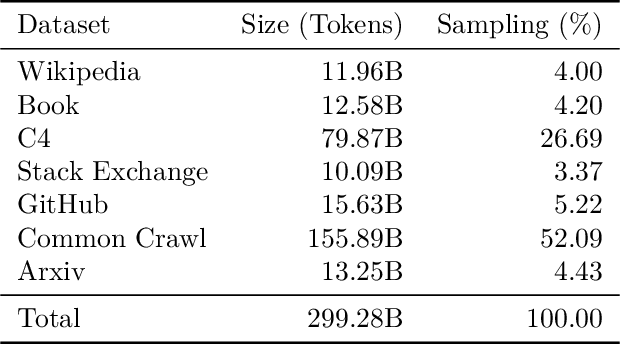
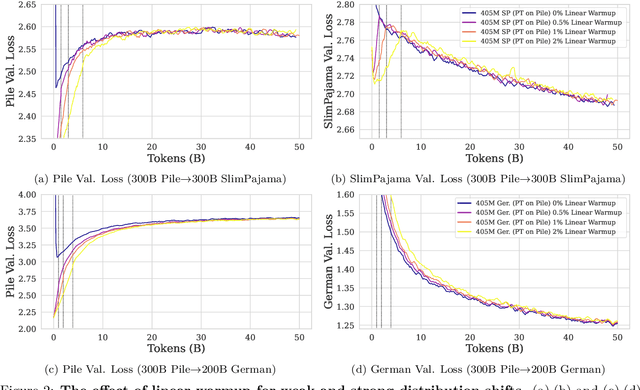
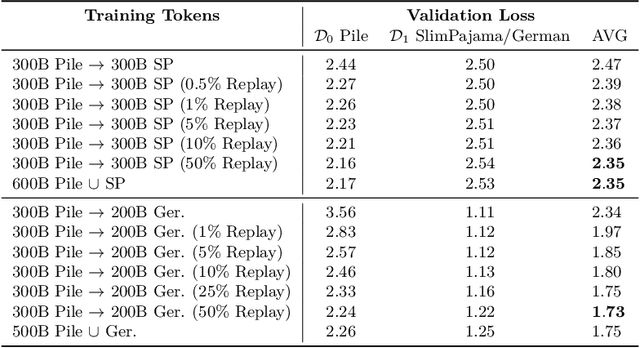
Large language models (LLMs) are routinely pre-trained on billions of tokens, only to start the process over again once new data becomes available. A much more efficient solution is to continually pre-train these models, saving significant compute compared to re-training. However, the distribution shift induced by new data typically results in degraded performance on previous data or poor adaptation to the new data. In this work, we show that a simple and scalable combination of learning rate (LR) re-warming, LR re-decaying, and replay of previous data is sufficient to match the performance of fully re-training from scratch on all available data, as measured by the final loss and the average score on several language model (LM) evaluation benchmarks. Specifically, we show this for a weak but realistic distribution shift between two commonly used LLM pre-training datasets (English$\rightarrow$English) and a stronger distribution shift (English$\rightarrow$German) at the $405$M parameter model scale with large dataset sizes (hundreds of billions of tokens). Selecting the weak but realistic shift for larger-scale experiments, we also find that our continual learning strategies match the re-training baseline for a 10B parameter LLM. Our results demonstrate that LLMs can be successfully updated via simple and scalable continual learning strategies, matching the re-training baseline using only a fraction of the compute. Finally, inspired by previous work, we propose alternatives to the cosine learning rate schedule that help circumvent forgetting induced by LR re-warming and that are not bound to a fixed token budget.
Continual Pre-Training of Large Language Models: How to (re)warm your model?
Aug 08, 2023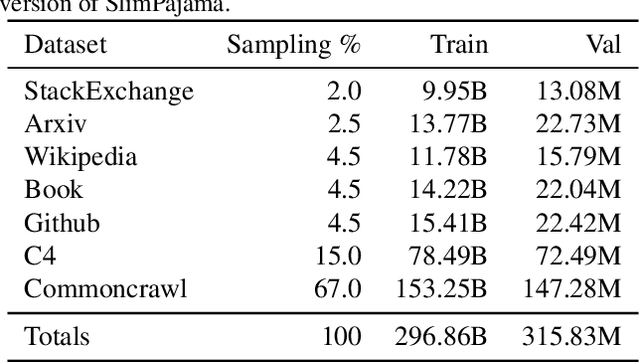
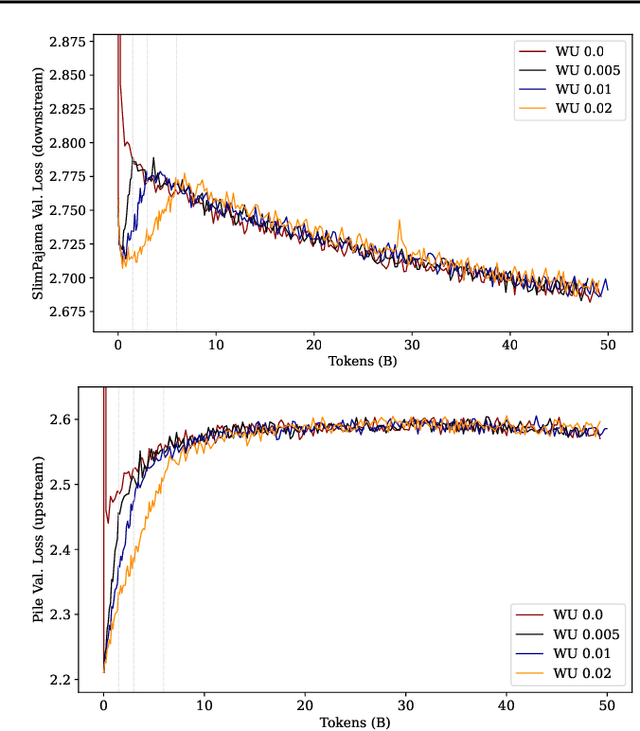
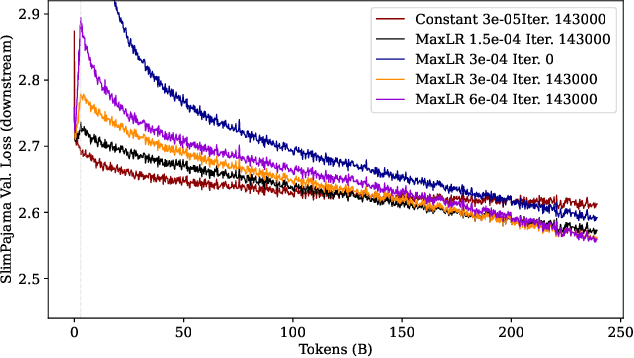
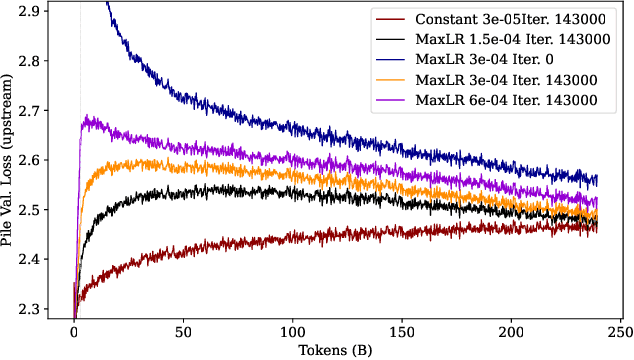
Large language models (LLMs) are routinely pre-trained on billions of tokens, only to restart the process over again once new data becomes available. A much cheaper and more efficient solution would be to enable the continual pre-training of these models, i.e. updating pre-trained models with new data instead of re-training them from scratch. However, the distribution shift induced by novel data typically results in degraded performance on past data. Taking a step towards efficient continual pre-training, in this work, we examine the effect of different warm-up strategies. Our hypothesis is that the learning rate must be re-increased to improve compute efficiency when training on a new dataset. We study the warmup phase of models pre-trained on the Pile (upstream data, 300B tokens) as we continue to pre-train on SlimPajama (downstream data, 297B tokens), following a linear warmup and cosine decay schedule. We conduct all experiments on the Pythia 410M language model architecture and evaluate performance through validation perplexity. We experiment with different pre-training checkpoints, various maximum learning rates, and various warmup lengths. Our results show that while rewarming models first increases the loss on upstream and downstream data, in the longer run it improves the downstream performance, outperforming models trained from scratch$\unicode{x2013}$even for a large downstream dataset.
Receptive Field Refinement for Convolutional Neural Networks Reliably Improves Predictive Performance
Nov 26, 2022Minimal changes to neural architectures (e.g. changing a single hyperparameter in a key layer), can lead to significant gains in predictive performance in Convolutional Neural Networks (CNNs). In this work, we present a new approach to receptive field analysis that can yield these types of theoretical and empirical performance gains across twenty well-known CNN architectures examined in our experiments. By further developing and formalizing the analysis of receptive field expansion in convolutional neural networks, we can predict unproductive layers in an automated manner before ever training a model. This allows us to optimize the parameter-efficiency of a given architecture at low cost. Our method is computationally simple and can be done in an automated manner or even manually with minimal effort for most common architectures. We demonstrate the effectiveness of this approach by increasing parameter efficiency across past and current top-performing CNN-architectures. Specifically, our approach is able to improve ImageNet1K performance across a wide range of well-known, state-of-the-art (SOTA) model classes, including: VGG Nets, MobileNetV1, MobileNetV3, NASNet A (mobile), MnasNet, EfficientNet, and ConvNeXt - leading to a new SOTA result for each model class.
Should You Go Deeper? Optimizing Convolutional Neural Network Architectures without Training by Receptive Field Analysis
Jun 23, 2021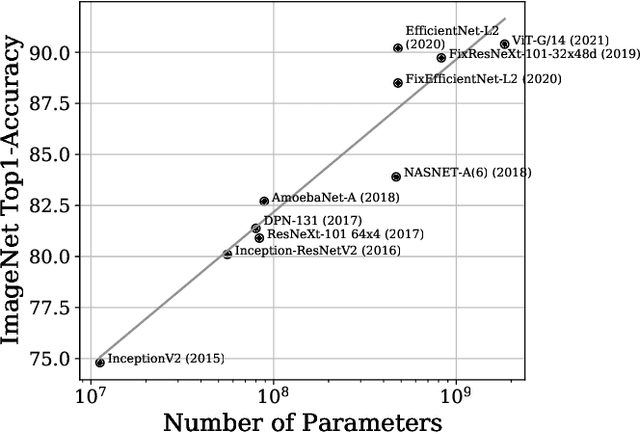
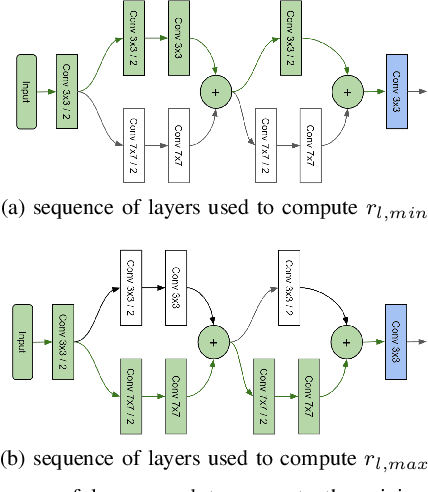
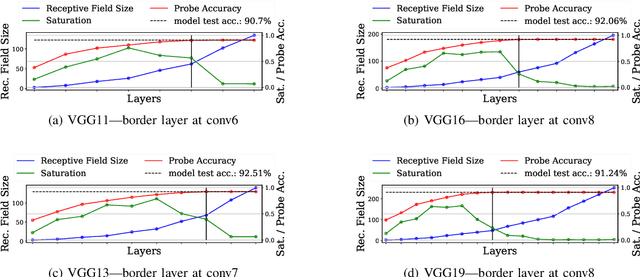
Applying artificial neural networks (ANN) to specific tasks, researchers, programmers, and other specialists usually overshot the number of convolutional layers in their designs. By implication, these ANNs hold too many parameters, which needed unnecessarily trained without impacting the result. The features, a convolutional layer can process, are strictly limited by its receptive field. By layer-wise analyzing the expansion of the receptive fields, we can reliably predict sequences of layers that will not contribute qualitatively to the inference in thegiven ANN architecture. Based on these analyses, we propose design strategies to resolve these inefficiencies, optimizing the explainability and the computational performance of ANNs. Since neither the strategies nor the analysis requires training of the actual model, these insights allow for a very efficient design process of ANNs architectures which might be automated in the future.
Exploring the Properties and Evolution of Neural Network Eigenspaces during Training
Jun 18, 2021
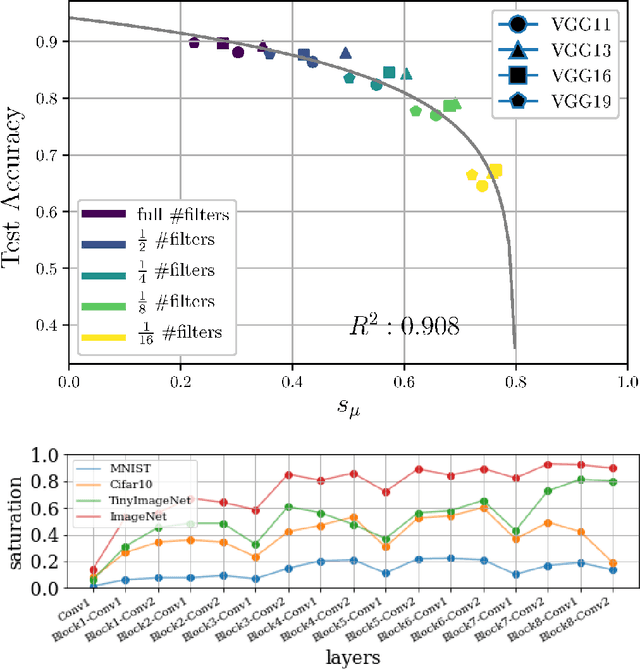
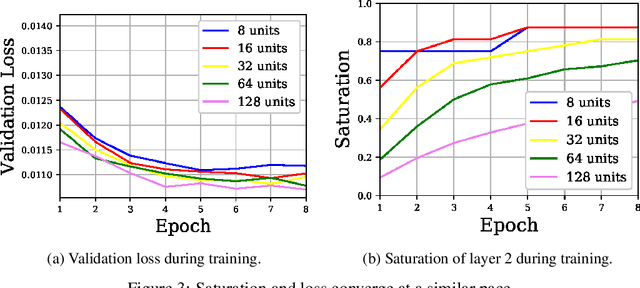
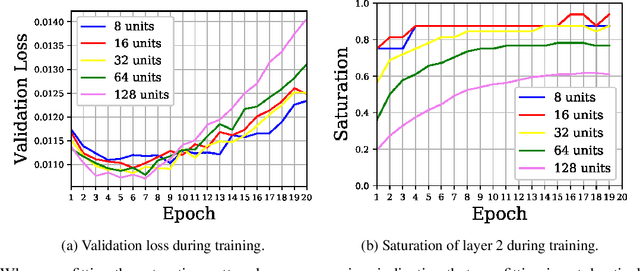
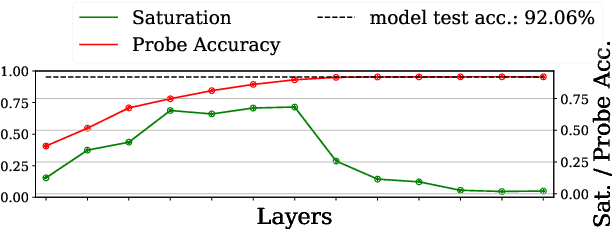
In this work we explore the information processing inside neural networks using logistic regression probes \cite{probes} and the saturation metric \cite{featurespace_saturation}. We show that problem difficulty and neural network capacity affect the predictive performance in an antagonistic manner, opening the possibility of detecting over- and under-parameterization of neural networks for a given task. We further show that the observed effects are independent from previously reported pathological patterns like the ``tail pattern'' described in \cite{featurespace_saturation}. Finally we are able to show that saturation patterns converge early during training, allowing for a quicker cycle time during analysis
Size Matters
Feb 09, 2021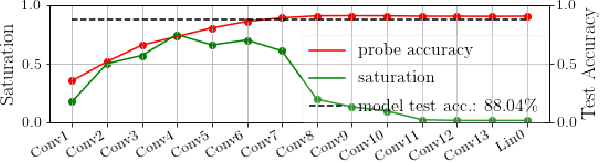
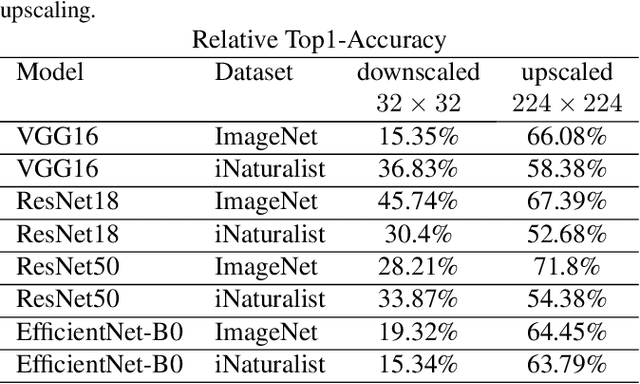
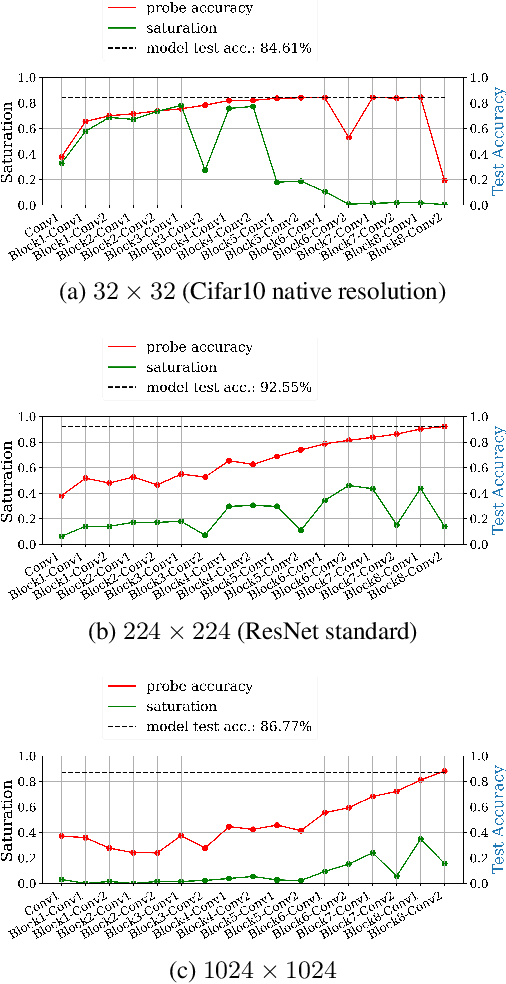
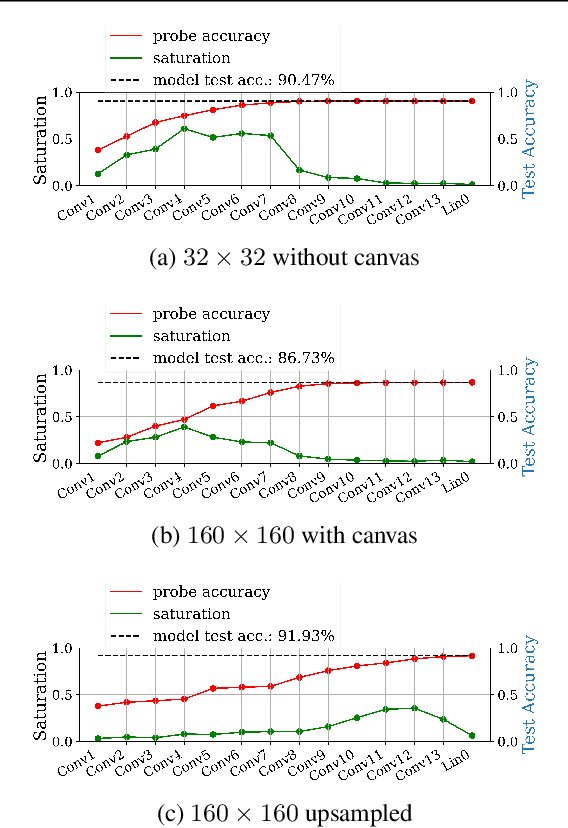
Fully convolutional neural networks can process input of arbitrary size by applying a combination of downsampling and pooling. However, we find that fully convolutional image classifiers are not agnostic to the input size but rather show significant differences in performance: presenting the same image at different scales can result in different outcomes. A closer look reveals that there is no simple relationship between input size and model performance (no `bigger is better'), but that each each network has a preferred input size, for which it shows best results. We investigate this phenomenon by applying different methods, including spectral analysis of layer activations and probe classifiers, showing that there are characteristic features depending on the network architecture. From this we find that the size of discriminatory features is critically influencing how the inference process is distributed among the layers.
Feature Space Saturation during Training
Jun 18, 2020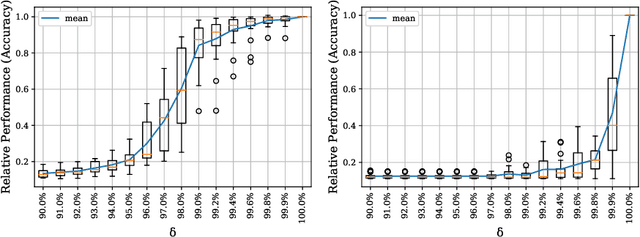
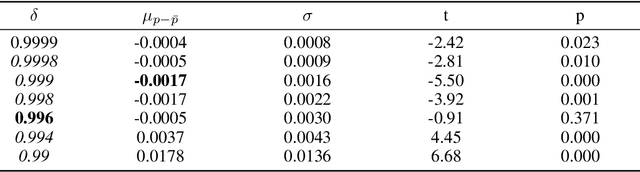
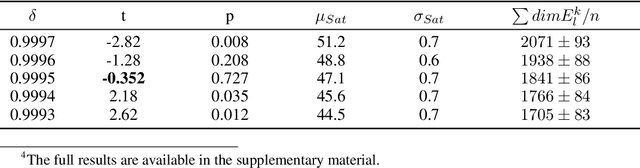
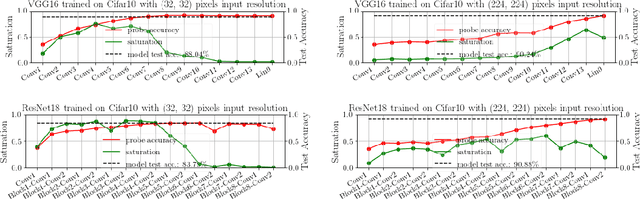
We propose layer saturation - a simple, online-computable method for analyzing the information processing in neural networks. First, we show that a layer's output can be restricted to the eigenspace of its variance matrix without performance loss. We propose a computationally lightweight method for approximating the variance matrix during training. From the dimension of its lossless eigenspace we derive layer saturation - the ratio between the eigenspace dimension and layer width. We show that saturation seems to indicate which layers contribute to network performance. We demonstrate how to alter layer saturation in a neural network by changing network depth, filter sizes and input resolution. Furthermore, we show that well-chosen input resolution increases network performance by distributing the inference process more evenly across the network.
Spectral Analysis of Latent Representations
Jul 19, 2019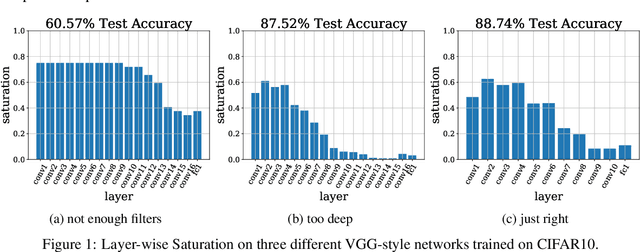
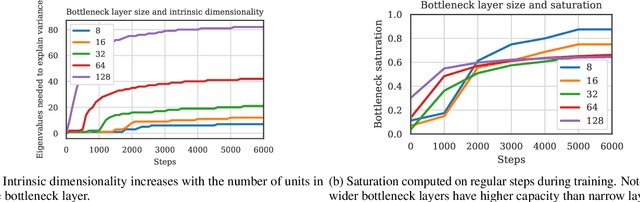
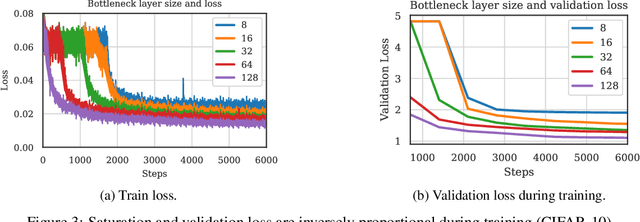
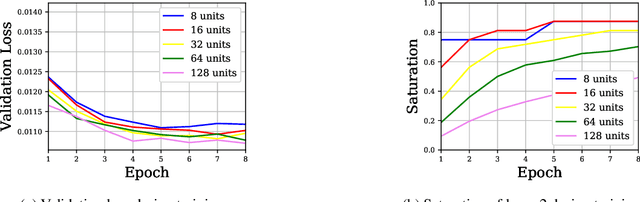
We propose a metric, Layer Saturation, defined as the proportion of the number of eigenvalues needed to explain 99% of the variance of the latent representations, for analyzing the learned representations of neural network layers. Saturation is based on spectral analysis and can be computed efficiently, making live analysis of the representations practical during training. We provide an outlook for future applications of this metric by outlining the behaviour of layer saturation in different neural architectures and problems. We further show that saturation is related to the generalization and predictive performance of neural networks.