 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSize Matters
Feb 09, 2021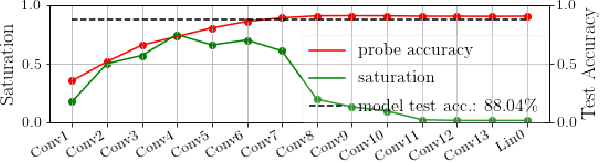
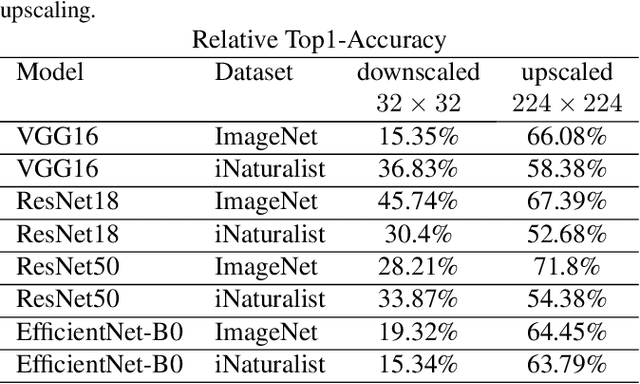
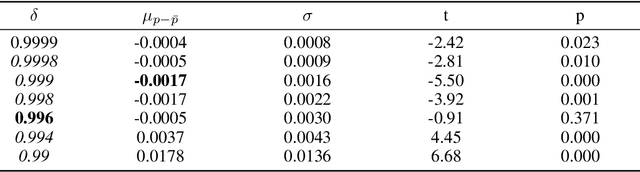
Fully convolutional neural networks can process input of arbitrary size by applying a combination of downsampling and pooling. However, we find that fully convolutional image classifiers are not agnostic to the input size but rather show significant differences in performance: presenting the same image at different scales can result in different outcomes. A closer look reveals that there is no simple relationship between input size and model performance (no `bigger is better'), but that each each network has a preferred input size, for which it shows best results. We investigate this phenomenon by applying different methods, including spectral analysis of layer activations and probe classifiers, showing that there are characteristic features depending on the network architecture. From this we find that the size of discriminatory features is critically influencing how the inference process is distributed among the layers.
Feature Space Saturation during Training
Jun 18, 2020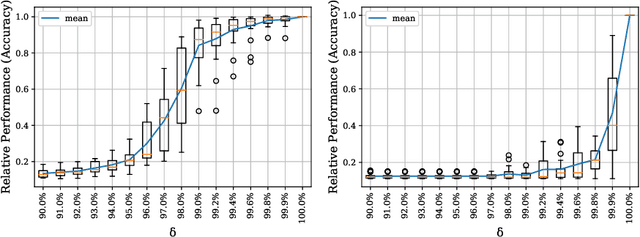
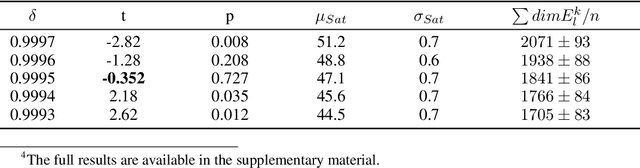
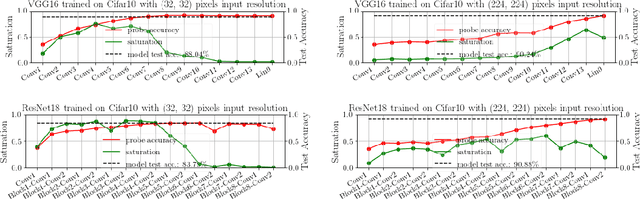
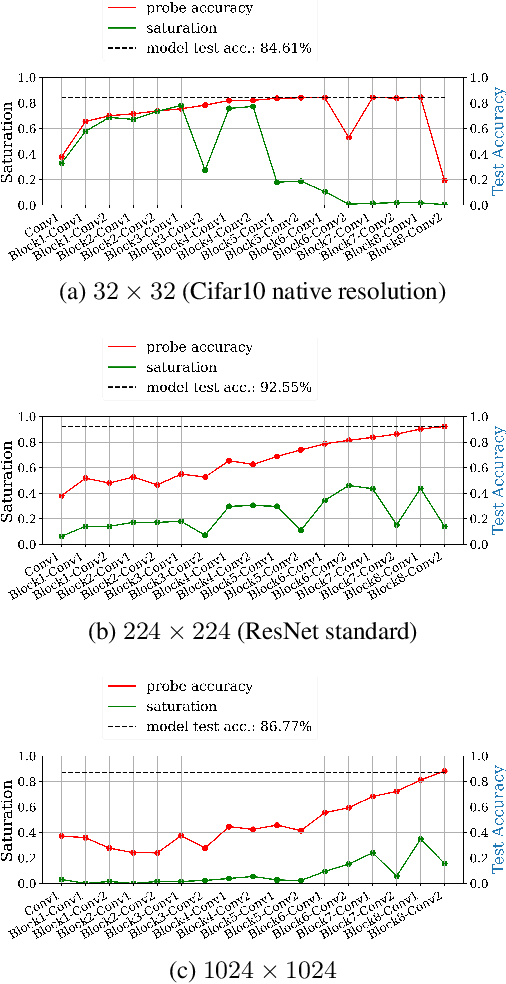
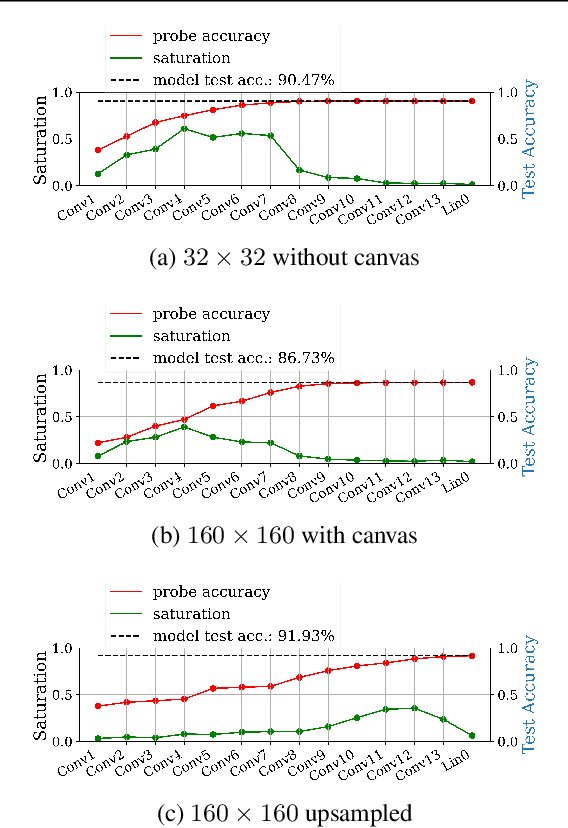
We propose layer saturation - a simple, online-computable method for analyzing the information processing in neural networks. First, we show that a layer's output can be restricted to the eigenspace of its variance matrix without performance loss. We propose a computationally lightweight method for approximating the variance matrix during training. From the dimension of its lossless eigenspace we derive layer saturation - the ratio between the eigenspace dimension and layer width. We show that saturation seems to indicate which layers contribute to network performance. We demonstrate how to alter layer saturation in a neural network by changing network depth, filter sizes and input resolution. Furthermore, we show that well-chosen input resolution increases network performance by distributing the inference process more evenly across the network.