 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Disentangled Audio Representations through Controlled Synthesis
Feb 16, 2024
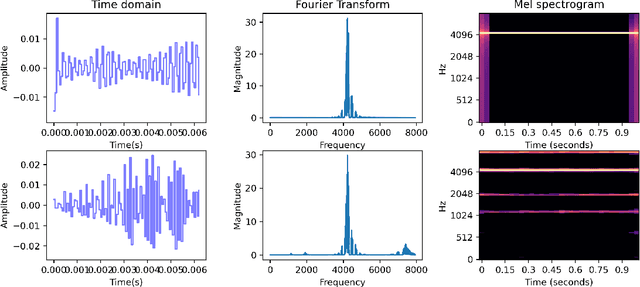

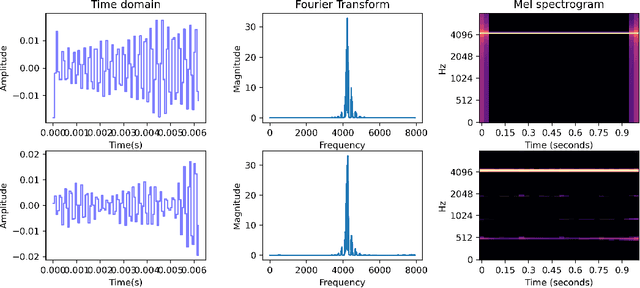
This paper tackles the scarcity of benchmarking data in disentangled auditory representation learning. We introduce SynTone, a synthetic dataset with explicit ground truth explanatory factors for evaluating disentanglement techniques. Benchmarking state-of-the-art methods on SynTone highlights its utility for method evaluation. Our results underscore strengths and limitations in audio disentanglement, motivating future research.
Show Me How It's Done: The Role of Explanations in Fine-Tuning Language Models
Feb 12, 2024



Our research demonstrates the significant benefits of using fine-tuning with explanations to enhance the performance of language models. Unlike prompting, which maintains the model's parameters, fine-tuning allows the model to learn and update its parameters during a training phase. In this study, we applied fine-tuning to various sized language models using data that contained explanations of the output rather than merely presenting the answers. We found that even smaller language models with as few as 60 million parameters benefited substantially from this approach. Interestingly, our results indicated that the detailed explanations were more beneficial to smaller models than larger ones, with the latter gaining nearly the same advantage from any form of explanation, irrespective of its length. Additionally, we demonstrate that the inclusion of explanations enables the models to solve tasks that they were not able to solve without explanations. Lastly, we argue that despite the challenging nature of adding explanations, samples that contain explanations not only reduce the volume of data required for training but also promote a more effective generalization by the model. In essence, our findings suggest that fine-tuning with explanations significantly bolsters the performance of large language models.
Learning Disentangled Speech Representations
Nov 04, 2023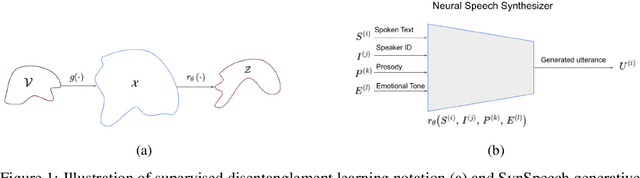
Disentangled representation learning from speech remains limited despite its importance in many application domains. A key challenge is the lack of speech datasets with known generative factors to evaluate methods. This paper proposes SynSpeech: a novel synthetic speech dataset with ground truth factors enabling research on disentangling speech representations. We plan to present a comprehensive study evaluating supervised techniques using established supervised disentanglement metrics. This benchmark dataset and framework address the gap in the rigorous evaluation of state-of-the-art disentangled speech representation learning methods. Our findings will provide insights to advance this underexplored area and enable more robust speech representations.
Understanding Self-Supervised Learning of Speech Representation via Invariance and Redundancy Reduction
Sep 07, 2023


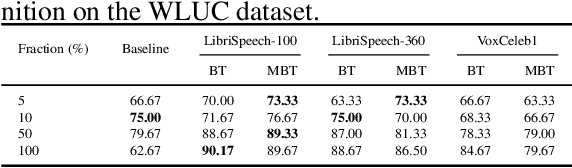
The choice of the objective function is crucial in emerging high-quality representations from self-supervised learning. This paper investigates how different formulations of the Barlow Twins (BT) objective impact downstream task performance for speech data. We propose Modified Barlow Twins (MBT) with normalized latents to enforce scale-invariance and evaluate on speaker identification, gender recognition and keyword spotting tasks. Our results show MBT improves representation generalization over original BT, especially when fine-tuning with limited target data. This highlights the importance of designing objectives that encourage invariant and transferable representations. Our analysis provides insights into how the BT learning objective can be tailored to produce speech representations that excel when adapted to new downstream tasks. This study is an important step towards developing reusable self-supervised speech representations.
Investigating Pre-trained Language Models on Cross-Domain Datasets, a Step Closer to General AI
Jun 21, 2023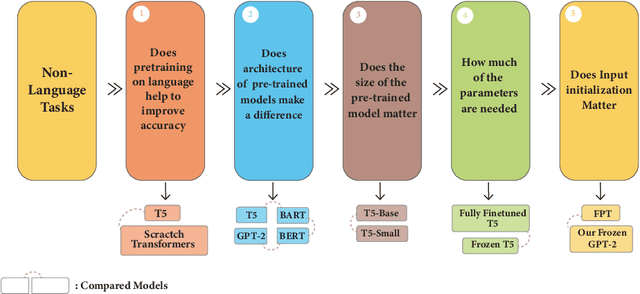

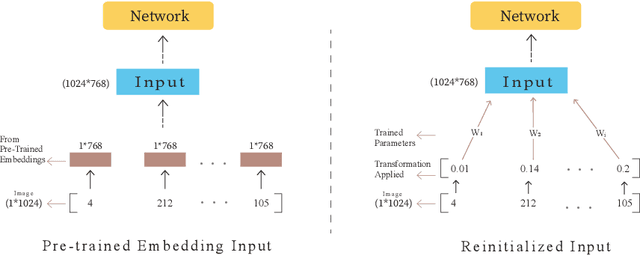

Pre-trained language models have recently emerged as a powerful tool for fine-tuning a variety of language tasks. Ideally, when models are pre-trained on large amount of data, they are expected to gain implicit knowledge. In this paper, we investigate the ability of pre-trained language models to generalize to different non-language tasks. In particular, we test them on tasks from different domains such as computer vision, reasoning on hierarchical data, and protein fold prediction. The four pre-trained models that we used, T5, BART, BERT, and GPT-2 achieve outstanding results. They all have similar performance and they outperform transformers that are trained from scratch by a large margin. For instance, pre-trained language models perform better on the Listops dataset, with an average accuracy of 58.7\%, compared to transformers trained from scratch, which have an average accuracy of 29.0\%. The significant improvement demonstrated across three types of datasets suggests that pre-training on language helps the models to acquire general knowledge, bringing us a step closer to general AI. We also showed that reducing the number of parameters in pre-trained language models does not have a great impact as the performance drops slightly when using T5-Small instead of T5-Base. In fact, when using only 2\% of the parameters, we achieved a great improvement compared to training from scratch. Finally, in contrast to prior work, we find out that using pre-trained embeddings for the input layer is necessary to achieve the desired results.
Opening the Black Box: Analyzing Attention Weights and Hidden States in Pre-trained Language Models for Non-language Tasks
Jun 21, 2023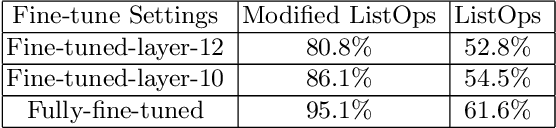


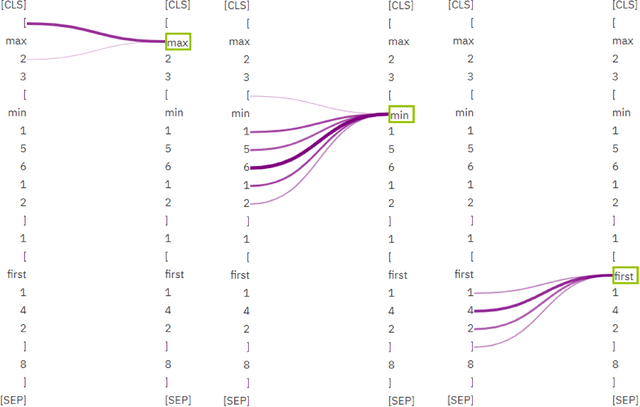
Investigating deep learning language models has always been a significant research area due to the ``black box" nature of most advanced models. With the recent advancements in pre-trained language models based on transformers and their increasing integration into daily life, addressing this issue has become more pressing. In order to achieve an explainable AI model, it is essential to comprehend the procedural steps involved and compare them with human thought processes. Thus, in this paper, we use simple, well-understood non-language tasks to explore these models' inner workings. Specifically, we apply a pre-trained language model to constrained arithmetic problems with hierarchical structure, to analyze their attention weight scores and hidden states. The investigation reveals promising results, with the model addressing hierarchical problems in a moderately structured manner, similar to human problem-solving strategies. Additionally, by inspecting the attention weights layer by layer, we uncover an unconventional finding that layer 10, rather than the model's final layer, is the optimal layer to unfreeze for the least parameter-intensive approach to fine-tune the model. We support these findings with entropy analysis and token embeddings similarity analysis. The attention analysis allows us to hypothesize that the model can generalize to longer sequences in ListOps dataset, a conclusion later confirmed through testing on sequences longer than those in the training set. Lastly, by utilizing a straightforward task in which the model predicts the winner of a Tic Tac Toe game, we identify limitations in attention analysis, particularly its inability to capture 2D patterns.
Should You Go Deeper? Optimizing Convolutional Neural Network Architectures without Training by Receptive Field Analysis
Jun 23, 2021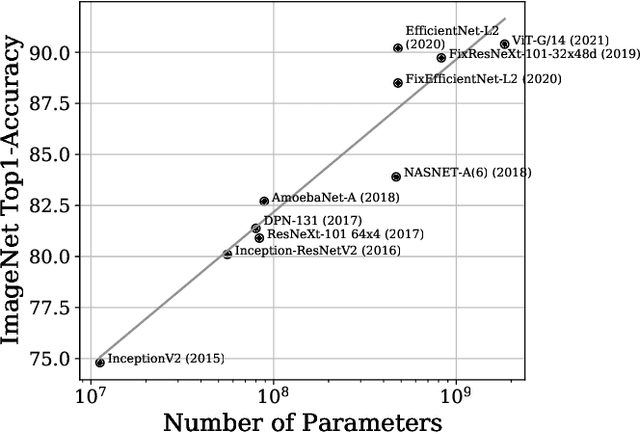
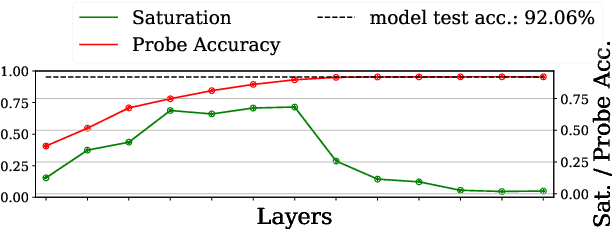
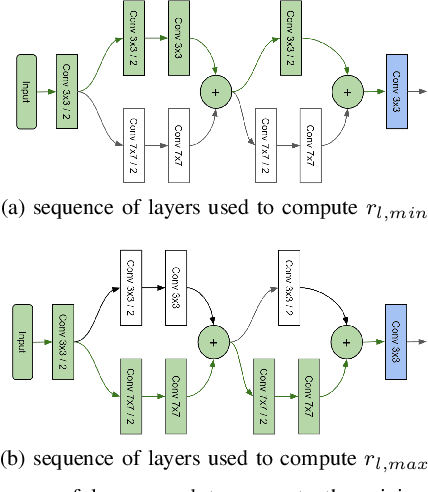
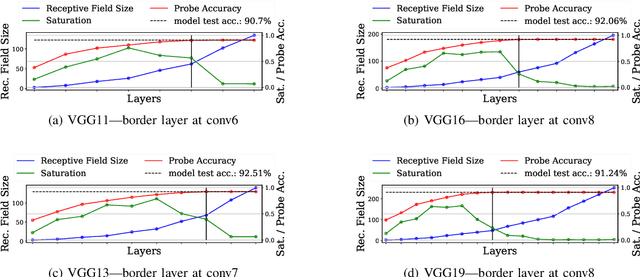
Applying artificial neural networks (ANN) to specific tasks, researchers, programmers, and other specialists usually overshot the number of convolutional layers in their designs. By implication, these ANNs hold too many parameters, which needed unnecessarily trained without impacting the result. The features, a convolutional layer can process, are strictly limited by its receptive field. By layer-wise analyzing the expansion of the receptive fields, we can reliably predict sequences of layers that will not contribute qualitatively to the inference in thegiven ANN architecture. Based on these analyses, we propose design strategies to resolve these inefficiencies, optimizing the explainability and the computational performance of ANNs. Since neither the strategies nor the analysis requires training of the actual model, these insights allow for a very efficient design process of ANNs architectures which might be automated in the future.
Exploring the Properties and Evolution of Neural Network Eigenspaces during Training
Jun 18, 2021
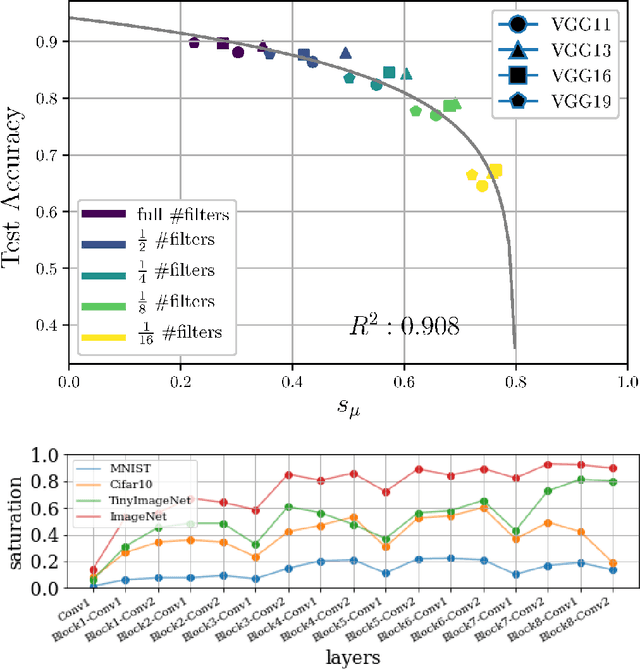
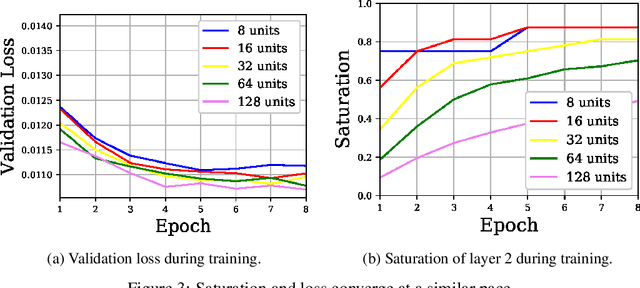
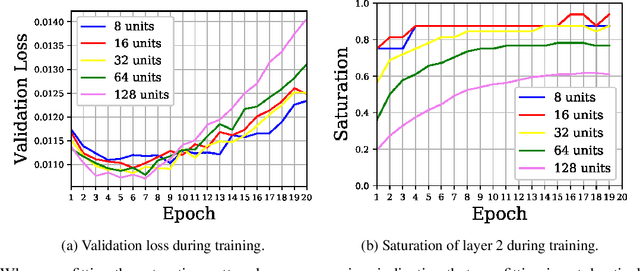
In this work we explore the information processing inside neural networks using logistic regression probes \cite{probes} and the saturation metric \cite{featurespace_saturation}. We show that problem difficulty and neural network capacity affect the predictive performance in an antagonistic manner, opening the possibility of detecting over- and under-parameterization of neural networks for a given task. We further show that the observed effects are independent from previously reported pathological patterns like the ``tail pattern'' described in \cite{featurespace_saturation}. Finally we are able to show that saturation patterns converge early during training, allowing for a quicker cycle time during analysis
Size Matters
Feb 09, 2021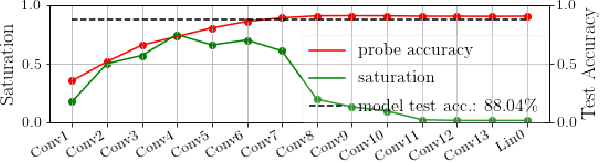
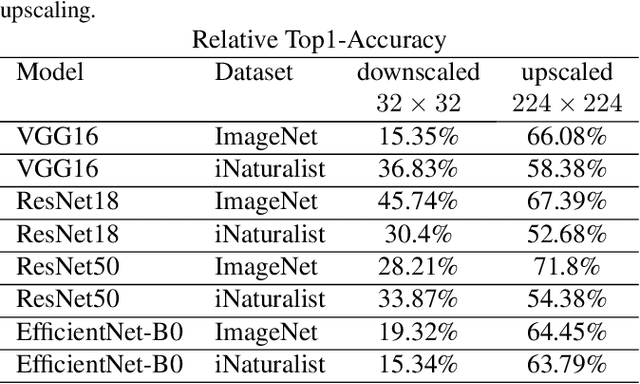
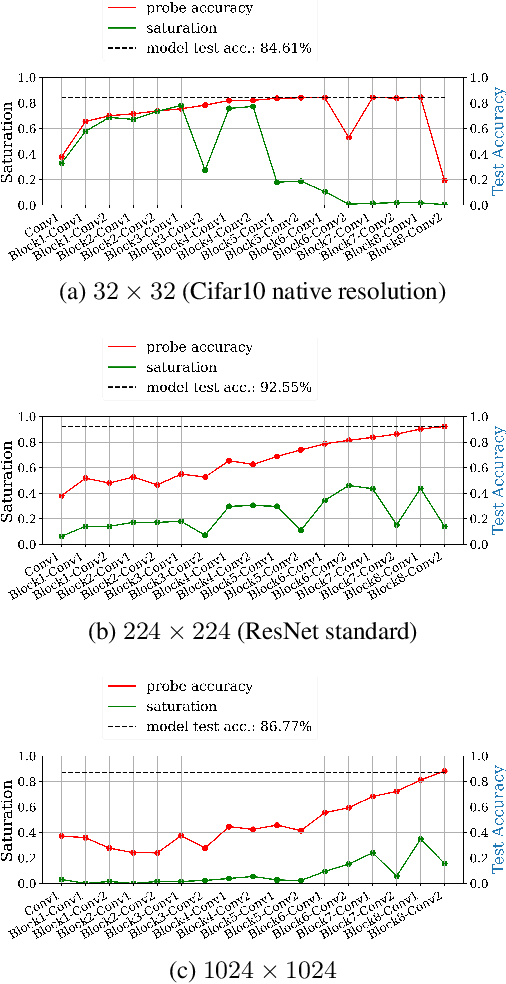
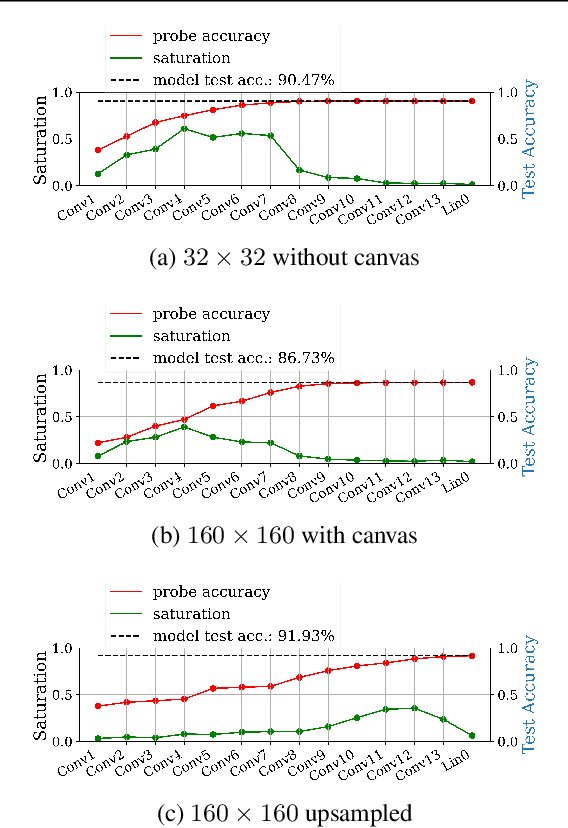
Fully convolutional neural networks can process input of arbitrary size by applying a combination of downsampling and pooling. However, we find that fully convolutional image classifiers are not agnostic to the input size but rather show significant differences in performance: presenting the same image at different scales can result in different outcomes. A closer look reveals that there is no simple relationship between input size and model performance (no `bigger is better'), but that each each network has a preferred input size, for which it shows best results. We investigate this phenomenon by applying different methods, including spectral analysis of layer activations and probe classifiers, showing that there are characteristic features depending on the network architecture. From this we find that the size of discriminatory features is critically influencing how the inference process is distributed among the layers.