 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Pre-trained Language Models on Cross-Domain Datasets, a Step Closer to General AI
Paper and Code
Jun 21, 2023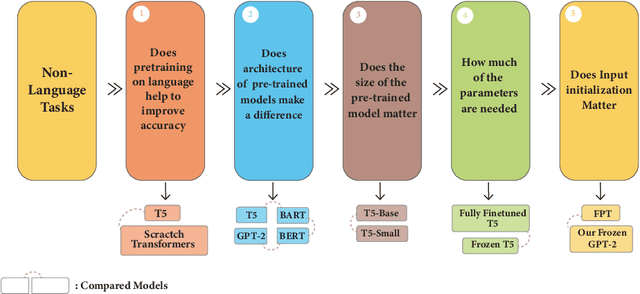

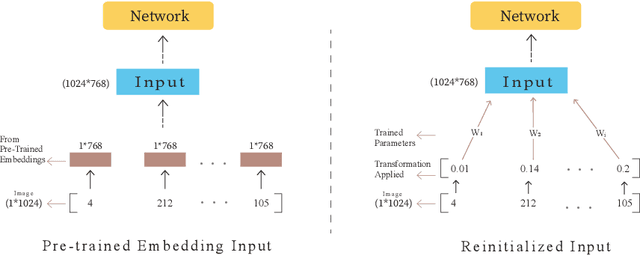

Pre-trained language models have recently emerged as a powerful tool for fine-tuning a variety of language tasks. Ideally, when models are pre-trained on large amount of data, they are expected to gain implicit knowledge. In this paper, we investigate the ability of pre-trained language models to generalize to different non-language tasks. In particular, we test them on tasks from different domains such as computer vision, reasoning on hierarchical data, and protein fold prediction. The four pre-trained models that we used, T5, BART, BERT, and GPT-2 achieve outstanding results. They all have similar performance and they outperform transformers that are trained from scratch by a large margin. For instance, pre-trained language models perform better on the Listops dataset, with an average accuracy of 58.7\%, compared to transformers trained from scratch, which have an average accuracy of 29.0\%. The significant improvement demonstrated across three types of datasets suggests that pre-training on language helps the models to acquire general knowledge, bringing us a step closer to general AI. We also showed that reducing the number of parameters in pre-trained language models does not have a great impact as the performance drops slightly when using T5-Small instead of T5-Base. In fact, when using only 2\% of the parameters, we achieved a great improvement compared to training from scratch. Finally, in contrast to prior work, we find out that using pre-trained embeddings for the input layer is necessary to achieve the desired results.