 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexandria: A Multi-Domain Dialectal Arabic Machine Translation Dataset for Culturally Inclusive and Linguistically Diverse LLMs
Jan 19, 2026Arabic is a highly diglossic language where most daily communication occurs in regional dialects rather than Modern Standard Arabic. Despite this, machine translation (MT) systems often generalize poorly to dialectal input, limiting their utility for millions of speakers. We introduce \textbf{Alexandria}, a large-scale, community-driven, human-translated dataset designed to bridge this gap. Alexandria covers 13 Arab countries and 11 high-impact domains, including health, education, and agriculture. Unlike previous resources, Alexandria provides unprecedented granularity by associating contributions with city-of-origin metadata, capturing authentic local varieties beyond coarse regional labels. The dataset consists of multi-turn conversational scenarios annotated with speaker-addressee gender configurations, enabling the study of gender-conditioned variation in dialectal use. Comprising 107K total samples, Alexandria serves as both a training resource and a rigorous benchmark for evaluating MT and Large Language Models (LLMs). Our automatic and human evaluation of Arabic-aware LLMs benchmarks current capabilities in translating across diverse Arabic dialects and sub-dialects, while exposing significant persistent challenges.
Pixels to Principles: Probing Intuitive Physics Understanding in Multimodal Language Models
Jul 22, 2025This paper presents a systematic evaluation of state-of-the-art multimodal large language models (MLLMs) on intuitive physics tasks using the GRASP and IntPhys 2 datasets. We assess the open-source models InternVL 2.5, Qwen 2.5 VL, LLaVA-OneVision, and the proprietary Gemini 2.0 Flash Thinking, finding that even the latest models struggle to reliably distinguish physically plausible from implausible scenarios. To go beyond performance metrics, we conduct a probing analysis of model embeddings, extracting intermediate representations at key processing stages to examine how well task-relevant information is preserved. Our results show that, depending on task difficulty, a critical vision-language misalignment can emerge: vision encoders successfully capture physical plausibility cues, but this information is not effectively utilized by the language model, leading to failures in reasoning. This misalignment suggests that the primary limitation of MLLMs in intuitive physics tasks is not the vision component but the ineffective integration of visual and linguistic information. Our findings highlight vision-language alignment as a key area for improvement, offering insights for future MLLMs development.
iVISPAR -- An Interactive Visual-Spatial Reasoning Benchmark for VLMs
Feb 05, 2025Vision-Language Models (VLMs) are known to struggle with spatial reasoning and visual alignment. To help overcome these limitations, we introduce iVISPAR, an interactive multi-modal benchmark designed to evaluate the spatial reasoning capabilities of VLMs acting as agents. iVISPAR is based on a variant of the sliding tile puzzle-a classic problem that demands logical planning, spatial awareness, and multi-step reasoning. The benchmark supports visual 2D, 3D, and text-based input modalities, enabling comprehensive assessments of VLMs' planning and reasoning skills. We evaluate a broad suite of state-of-the-art open-source and closed-source VLMs, comparing their performance while also providing optimal path solutions and a human baseline to assess the task's complexity and feasibility for humans. Results indicate that while some VLMs perform well on simple spatial tasks, they encounter difficulties with more complex configurations and problem properties. Notably, while VLMs generally perform better in 2D vision compared to 3D or text-based representations, they consistently fall short of human performance, illustrating the persistent challenge of visual alignment. This highlights critical gaps in current VLM capabilities, highlighting their limitations in achieving human-level cognition.
Show Me How It's Done: The Role of Explanations in Fine-Tuning Language Models
Feb 12, 2024



Our research demonstrates the significant benefits of using fine-tuning with explanations to enhance the performance of language models. Unlike prompting, which maintains the model's parameters, fine-tuning allows the model to learn and update its parameters during a training phase. In this study, we applied fine-tuning to various sized language models using data that contained explanations of the output rather than merely presenting the answers. We found that even smaller language models with as few as 60 million parameters benefited substantially from this approach. Interestingly, our results indicated that the detailed explanations were more beneficial to smaller models than larger ones, with the latter gaining nearly the same advantage from any form of explanation, irrespective of its length. Additionally, we demonstrate that the inclusion of explanations enables the models to solve tasks that they were not able to solve without explanations. Lastly, we argue that despite the challenging nature of adding explanations, samples that contain explanations not only reduce the volume of data required for training but also promote a more effective generalization by the model. In essence, our findings suggest that fine-tuning with explanations significantly bolsters the performance of large language models.
Investigating Pre-trained Language Models on Cross-Domain Datasets, a Step Closer to General AI
Jun 21, 2023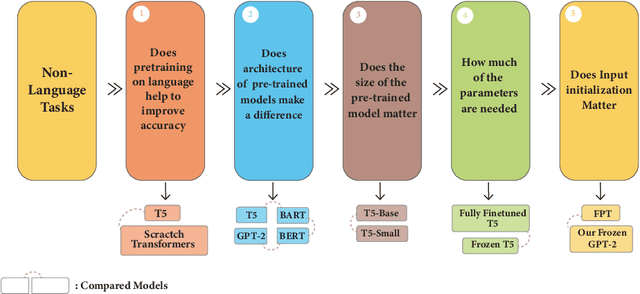

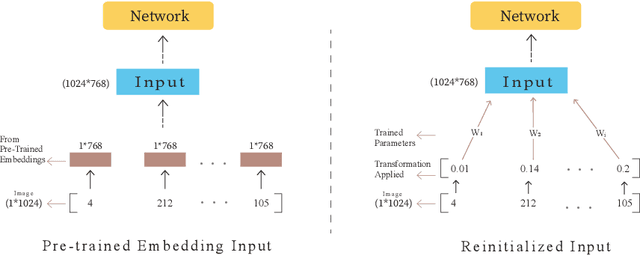

Pre-trained language models have recently emerged as a powerful tool for fine-tuning a variety of language tasks. Ideally, when models are pre-trained on large amount of data, they are expected to gain implicit knowledge. In this paper, we investigate the ability of pre-trained language models to generalize to different non-language tasks. In particular, we test them on tasks from different domains such as computer vision, reasoning on hierarchical data, and protein fold prediction. The four pre-trained models that we used, T5, BART, BERT, and GPT-2 achieve outstanding results. They all have similar performance and they outperform transformers that are trained from scratch by a large margin. For instance, pre-trained language models perform better on the Listops dataset, with an average accuracy of 58.7\%, compared to transformers trained from scratch, which have an average accuracy of 29.0\%. The significant improvement demonstrated across three types of datasets suggests that pre-training on language helps the models to acquire general knowledge, bringing us a step closer to general AI. We also showed that reducing the number of parameters in pre-trained language models does not have a great impact as the performance drops slightly when using T5-Small instead of T5-Base. In fact, when using only 2\% of the parameters, we achieved a great improvement compared to training from scratch. Finally, in contrast to prior work, we find out that using pre-trained embeddings for the input layer is necessary to achieve the desired results.
Opening the Black Box: Analyzing Attention Weights and Hidden States in Pre-trained Language Models for Non-language Tasks
Jun 21, 2023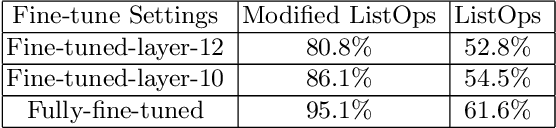


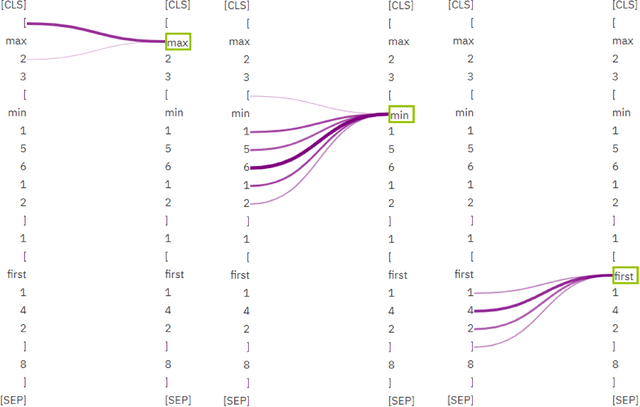
Investigating deep learning language models has always been a significant research area due to the ``black box" nature of most advanced models. With the recent advancements in pre-trained language models based on transformers and their increasing integration into daily life, addressing this issue has become more pressing. In order to achieve an explainable AI model, it is essential to comprehend the procedural steps involved and compare them with human thought processes. Thus, in this paper, we use simple, well-understood non-language tasks to explore these models' inner workings. Specifically, we apply a pre-trained language model to constrained arithmetic problems with hierarchical structure, to analyze their attention weight scores and hidden states. The investigation reveals promising results, with the model addressing hierarchical problems in a moderately structured manner, similar to human problem-solving strategies. Additionally, by inspecting the attention weights layer by layer, we uncover an unconventional finding that layer 10, rather than the model's final layer, is the optimal layer to unfreeze for the least parameter-intensive approach to fine-tune the model. We support these findings with entropy analysis and token embeddings similarity analysis. The attention analysis allows us to hypothesize that the model can generalize to longer sequences in ListOps dataset, a conclusion later confirmed through testing on sequences longer than those in the training set. Lastly, by utilizing a straightforward task in which the model predicts the winner of a Tic Tac Toe game, we identify limitations in attention analysis, particularly its inability to capture 2D patterns.
The benefits of synthetic data for action categorization
Jan 20, 2020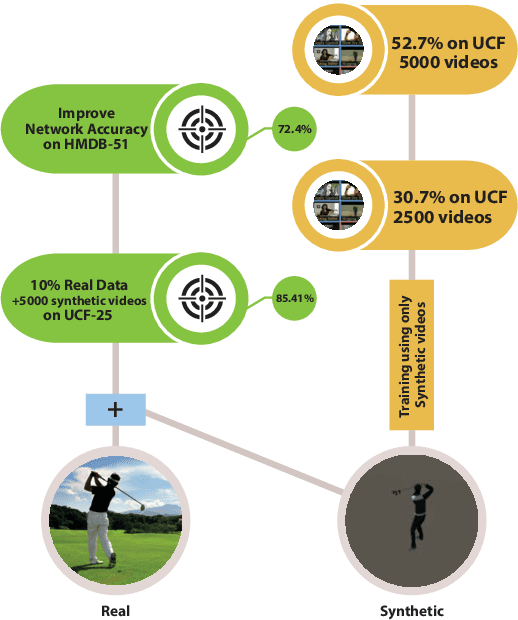

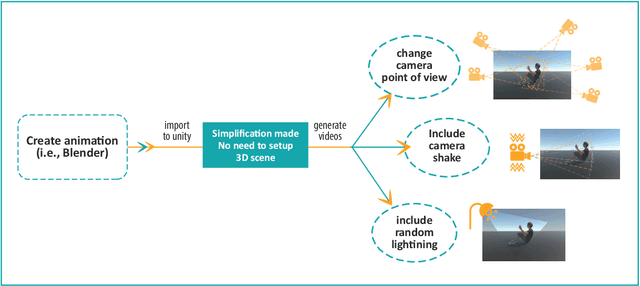
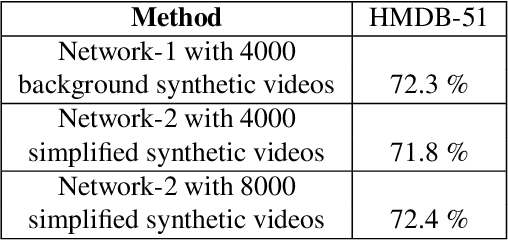
In this paper, we study the value of using synthetically produced videos as training data for neural networks used for action categorization. Motivated by the fact that texture and background of a video play little to no significant roles in optical flow, we generated simplified texture-less and background-less videos and utilized the synthetic data to train a Temporal Segment Network (TSN). The results demonstrated that augmenting TSN with simplified synthetic data improved the original network accuracy (68.5%), achieving 71.8% on HMDB-51 when adding 4,000 videos and 72.4% when adding 8,000 videos. Also, training using simplified synthetic videos alone on 25 classes of UCF-101 achieved 30.71% when trained on 2500 videos and 52.7% when trained on 5000 videos. Finally, results showed that when reducing the number of real videos of UCF-25 to 10% and combining them with synthetic videos, the accuracy drops to only 85.41%, compared to a drop to 77.4% when no synthetic data is added.