 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixels to Principles: Probing Intuitive Physics Understanding in Multimodal Language Models
Jul 22, 2025This paper presents a systematic evaluation of state-of-the-art multimodal large language models (MLLMs) on intuitive physics tasks using the GRASP and IntPhys 2 datasets. We assess the open-source models InternVL 2.5, Qwen 2.5 VL, LLaVA-OneVision, and the proprietary Gemini 2.0 Flash Thinking, finding that even the latest models struggle to reliably distinguish physically plausible from implausible scenarios. To go beyond performance metrics, we conduct a probing analysis of model embeddings, extracting intermediate representations at key processing stages to examine how well task-relevant information is preserved. Our results show that, depending on task difficulty, a critical vision-language misalignment can emerge: vision encoders successfully capture physical plausibility cues, but this information is not effectively utilized by the language model, leading to failures in reasoning. This misalignment suggests that the primary limitation of MLLMs in intuitive physics tasks is not the vision component but the ineffective integration of visual and linguistic information. Our findings highlight vision-language alignment as a key area for improvement, offering insights for future MLLMs development.
iVISPAR -- An Interactive Visual-Spatial Reasoning Benchmark for VLMs
Feb 05, 2025Vision-Language Models (VLMs) are known to struggle with spatial reasoning and visual alignment. To help overcome these limitations, we introduce iVISPAR, an interactive multi-modal benchmark designed to evaluate the spatial reasoning capabilities of VLMs acting as agents. iVISPAR is based on a variant of the sliding tile puzzle-a classic problem that demands logical planning, spatial awareness, and multi-step reasoning. The benchmark supports visual 2D, 3D, and text-based input modalities, enabling comprehensive assessments of VLMs' planning and reasoning skills. We evaluate a broad suite of state-of-the-art open-source and closed-source VLMs, comparing their performance while also providing optimal path solutions and a human baseline to assess the task's complexity and feasibility for humans. Results indicate that while some VLMs perform well on simple spatial tasks, they encounter difficulties with more complex configurations and problem properties. Notably, while VLMs generally perform better in 2D vision compared to 3D or text-based representations, they consistently fall short of human performance, illustrating the persistent challenge of visual alignment. This highlights critical gaps in current VLM capabilities, highlighting their limitations in achieving human-level cognition.
Emergent Language in Open-Ended Environments
Aug 26, 2024Emergent language research has made significant progress in recent years, but still largely fails to explore how communication emerges in more complex and situated multi-agent systems. Existing setups often employ a reference game, which limits the range of language emergence phenomena that can be studied, as the game consists of a single, purely language-based interaction between the agents. In this paper, we address these limitations and explore the emergence and utility of token-based communication in open-ended multi-agent environments, where situated agents interact with the environment through movement and communication over multiple time-steps. Specifically, we introduce two novel cooperative environments: Multi-Agent Pong and Collectors. These environments are interesting because optimal performance requires the emergence of a communication protocol, but moderate success can be achieved without one. By employing various methods from explainable AI research, such as saliency maps, perturbation, and diagnostic classifiers, we are able to track and interpret the agents' language channel use over time. We find that the emerging communication is sparse, with the agents only generating meaningful messages and acting upon incoming messages in states where they cannot succeed without coordination.
A Review of Nine Physics Engines for Reinforcement Learning Research
Jul 11, 2024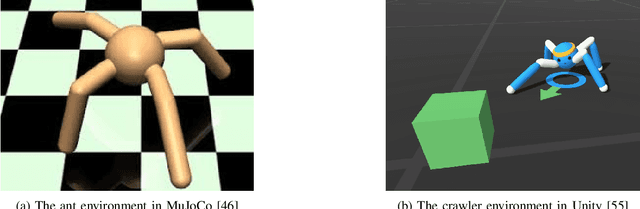



We present a review of popular simulation engines and frameworks used in reinforcement learning (RL) research, aiming to guide researchers in selecting tools for creating simulated physical environments for RL and training setups. It evaluates nine frameworks (Brax, Chrono, Gazebo, MuJoCo, ODE, PhysX, PyBullet, Webots, and Unity) based on their popularity, feature range, quality, usability, and RL capabilities. We highlight the challenges in selecting and utilizing physics engines for RL research, including the need for detailed comparisons and an understanding of each framework's capabilities. Key findings indicate MuJoCo as the leading framework due to its performance and flexibility, despite usability challenges. Unity is noted for its ease of use but lacks scalability and simulation fidelity. The study calls for further development to improve simulation engines' usability and performance and stresses the importance of transparency and reproducibility in RL research. This review contributes to the RL community by offering insights into the selection process for simulation engines, facilitating informed decision-making.
Interpretability of Language Models via Task Spaces
Jun 10, 2024



The usual way to interpret language models (LMs) is to test their performance on different benchmarks and subsequently infer their internal processes. In this paper, we present an alternative approach, concentrating on the quality of LM processing, with a focus on their language abilities. To this end, we construct 'linguistic task spaces' -- representations of an LM's language conceptualisation -- that shed light on the connections LMs draw between language phenomena. Task spaces are based on the interactions of the learning signals from different linguistic phenomena, which we assess via a method we call 'similarity probing'. To disentangle the learning signals of linguistic phenomena, we further introduce a method called 'fine-tuning via gradient differentials' (FTGD). We apply our methods to language models of three different scales and find that larger models generalise better to overarching general concepts for linguistic tasks, making better use of their shared structure. Further, the distributedness of linguistic processing increases with pre-training through increased parameter sharing between related linguistic tasks. The overall generalisation patterns are mostly stable throughout training and not marked by incisive stages, potentially explaining the lack of successful curriculum strategies for LMs.
From Form to Meaning: Probing the Semantic Depths of Language Models Using Multisense Consistency
Apr 18, 2024



The staggering pace with which the capabilities of large language models (LLMs) are increasing, as measured by a range of commonly used natural language understanding (NLU) benchmarks, raises many questions regarding what "understanding" means for a language model and how it compares to human understanding. This is especially true since many LLMs are exclusively trained on text, casting doubt on whether their stellar benchmark performances are reflective of a true understanding of the problems represented by these benchmarks, or whether LLMs simply excel at uttering textual forms that correlate with what someone who understands the problem would say. In this philosophically inspired work, we aim to create some separation between form and meaning, with a series of tests that leverage the idea that world understanding should be consistent across presentational modes - inspired by Fregean senses - of the same meaning. Specifically, we focus on consistency across languages as well as paraphrases. Taking GPT-3.5 as our object of study, we evaluate multisense consistency across five different languages and various tasks. We start the evaluation in a controlled setting, asking the model for simple facts, and then proceed with an evaluation on four popular NLU benchmarks. We find that the model's multisense consistency is lacking and run several follow-up analyses to verify that this lack of consistency is due to a sense-dependent task understanding. We conclude that, in this aspect, the understanding of LLMs is still quite far from being consistent and human-like, and deliberate on how this impacts their utility in the context of learning about human language and understanding.
The ICL Consistency Test
Dec 08, 2023Just like the previous generation of task-tuned models, large language models (LLMs) that are adapted to tasks via prompt-based methods like in-context-learning (ICL) perform well in some setups but not in others. This lack of consistency in prompt-based learning hints at a lack of robust generalisation. We here introduce the ICL consistency test -- a contribution to the GenBench collaborative benchmark task (CBT) -- which evaluates how consistent a model makes predictions across many different setups while using the same data. The test is based on different established natural language inference tasks. We provide preprocessed data constituting 96 different 'setups' and a metric that estimates model consistency across these setups. The metric is provided on a fine-grained level to understand what properties of a setup render predictions unstable and on an aggregated level to compare overall model consistency. We conduct an empirical analysis of eight state-of-the-art models, and our consistency metric reveals how all tested LLMs lack robust generalisation.
GRASP: A novel benchmark for evaluating language GRounding And Situated Physics understanding in multimodal language models
Nov 15, 2023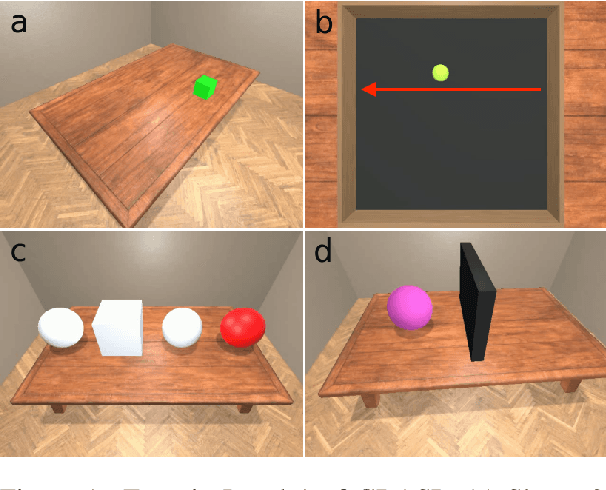
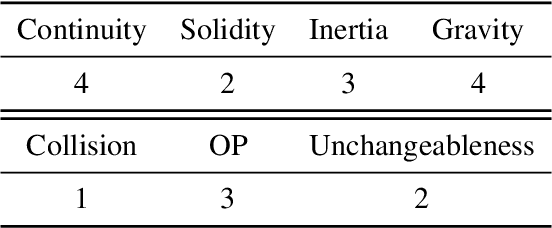

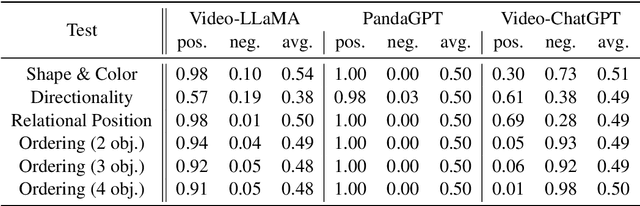
This paper presents GRASP, a novel benchmark to evaluate the language grounding and physical understanding capabilities of video-based multimodal large language models (LLMs). This evaluation is accomplished via a two-tier approach leveraging Unity simulations. The initial level tests for language grounding by assessing a model's ability to relate simple textual descriptions with visual information. The second level evaluates the model's understanding of 'Intuitive Physics' principles, such as object permanence and continuity. In addition to releasing the benchmark, we use it to evaluate several state-of-the-art multimodal LLMs. Our evaluation reveals significant shortcomings in current models' language grounding and intuitive physics. These identified limitations underline the importance of benchmarks like GRASP to monitor the progress of future models in developing these competencies.
Mind the instructions: a holistic evaluation of consistency and interactions in prompt-based learning
Oct 20, 2023



Finding the best way of adapting pre-trained language models to a task is a big challenge in current NLP. Just like the previous generation of task-tuned models (TT), models that are adapted to tasks via in-context-learning (ICL) are robust in some setups but not in others. Here, we present a detailed analysis of which design choices cause instabilities and inconsistencies in LLM predictions. First, we show how spurious correlations between input distributions and labels -- a known issue in TT models -- form only a minor problem for prompted models. Then, we engage in a systematic, holistic evaluation of different factors that have been found to influence predictions in a prompting setup. We test all possible combinations of a range of factors on both vanilla and instruction-tuned (IT) LLMs of different scale and statistically analyse the results to show which factors are the most influential, interactive or stable. Our results show which factors can be used without precautions and which should be avoided or handled with care in most settings.
Curriculum Learning with Adam: The Devil Is in the Wrong Details
Aug 23, 2023Curriculum learning (CL) posits that machine learning models -- similar to humans -- may learn more efficiently from data that match their current learning progress. However, CL methods are still poorly understood and, in particular for natural language processing (NLP), have achieved only limited success. In this paper, we explore why. Starting from an attempt to replicate and extend a number of recent curriculum methods, we find that their results are surprisingly brittle when applied to NLP. A deep dive into the (in)effectiveness of the curricula in some scenarios shows us why: when curricula are employed in combination with the popular Adam optimisation algorithm, they oftentimes learn to adapt to suboptimally chosen optimisation parameters for this algorithm. We present a number of different case studies with different common hand-crafted and automated CL approaches to illustrate this phenomenon, and we find that none of them outperforms optimisation with only Adam with well-chosen hyperparameters. As such, our results contribute to understanding why CL methods work, but at the same time urge caution when claiming positive results.