 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Language in Open-Ended Environments
Aug 26, 2024Emergent language research has made significant progress in recent years, but still largely fails to explore how communication emerges in more complex and situated multi-agent systems. Existing setups often employ a reference game, which limits the range of language emergence phenomena that can be studied, as the game consists of a single, purely language-based interaction between the agents. In this paper, we address these limitations and explore the emergence and utility of token-based communication in open-ended multi-agent environments, where situated agents interact with the environment through movement and communication over multiple time-steps. Specifically, we introduce two novel cooperative environments: Multi-Agent Pong and Collectors. These environments are interesting because optimal performance requires the emergence of a communication protocol, but moderate success can be achieved without one. By employing various methods from explainable AI research, such as saliency maps, perturbation, and diagnostic classifiers, we are able to track and interpret the agents' language channel use over time. We find that the emerging communication is sparse, with the agents only generating meaningful messages and acting upon incoming messages in states where they cannot succeed without coordination.
From Form to Meaning: Probing the Semantic Depths of Language Models Using Multisense Consistency
Apr 18, 2024



The staggering pace with which the capabilities of large language models (LLMs) are increasing, as measured by a range of commonly used natural language understanding (NLU) benchmarks, raises many questions regarding what "understanding" means for a language model and how it compares to human understanding. This is especially true since many LLMs are exclusively trained on text, casting doubt on whether their stellar benchmark performances are reflective of a true understanding of the problems represented by these benchmarks, or whether LLMs simply excel at uttering textual forms that correlate with what someone who understands the problem would say. In this philosophically inspired work, we aim to create some separation between form and meaning, with a series of tests that leverage the idea that world understanding should be consistent across presentational modes - inspired by Fregean senses - of the same meaning. Specifically, we focus on consistency across languages as well as paraphrases. Taking GPT-3.5 as our object of study, we evaluate multisense consistency across five different languages and various tasks. We start the evaluation in a controlled setting, asking the model for simple facts, and then proceed with an evaluation on four popular NLU benchmarks. We find that the model's multisense consistency is lacking and run several follow-up analyses to verify that this lack of consistency is due to a sense-dependent task understanding. We conclude that, in this aspect, the understanding of LLMs is still quite far from being consistent and human-like, and deliberate on how this impacts their utility in the context of learning about human language and understanding.
GRASP: A novel benchmark for evaluating language GRounding And Situated Physics understanding in multimodal language models
Nov 15, 2023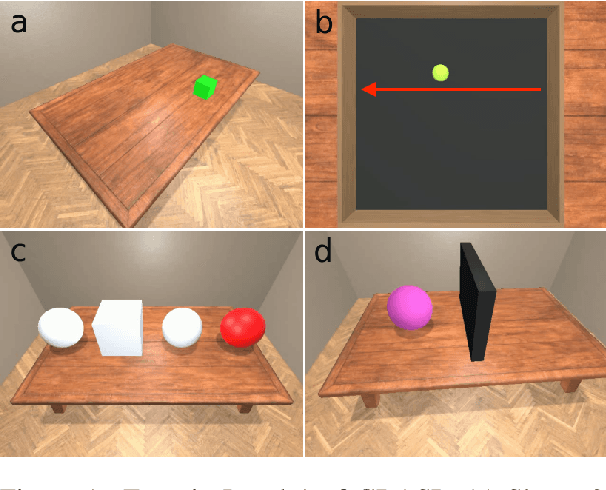
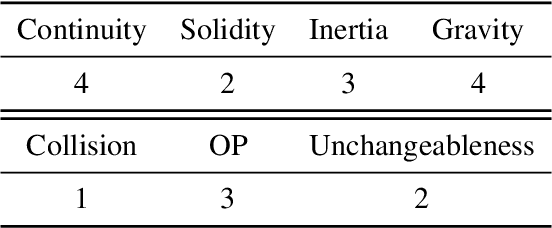

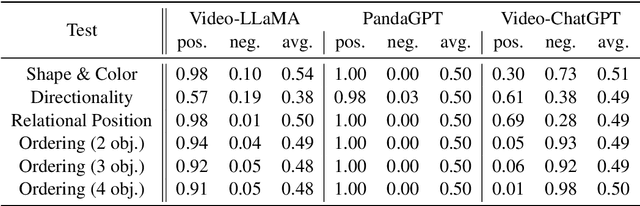
This paper presents GRASP, a novel benchmark to evaluate the language grounding and physical understanding capabilities of video-based multimodal large language models (LLMs). This evaluation is accomplished via a two-tier approach leveraging Unity simulations. The initial level tests for language grounding by assessing a model's ability to relate simple textual descriptions with visual information. The second level evaluates the model's understanding of 'Intuitive Physics' principles, such as object permanence and continuity. In addition to releasing the benchmark, we use it to evaluate several state-of-the-art multimodal LLMs. Our evaluation reveals significant shortcomings in current models' language grounding and intuitive physics. These identified limitations underline the importance of benchmarks like GRASP to monitor the progress of future models in developing these competencies.
On the Relationship between Skill Neurons and Robustness in Prompt Tuning
Sep 21, 2023



Prompt Tuning is a popular parameter-efficient finetuning method for pre-trained large language models (PLMs). Recently, based on experiments with RoBERTa, it has been suggested that Prompt Tuning activates specific neurons in the transformer's feed-forward networks, that are highly predictive and selective for the given task. In this paper, we study the robustness of Prompt Tuning in relation to these "skill neurons", using RoBERTa and T5. We show that prompts tuned for a specific task are transferable to tasks of the same type but are not very robust to adversarial data, with higher robustness for T5 than RoBERTa. At the same time, we replicate the existence of skill neurons in RoBERTa and further show that skill neurons also seem to exist in T5. Interestingly, the skill neurons of T5 determined on non-adversarial data are also among the most predictive neurons on the adversarial data, which is not the case for RoBERTa. We conclude that higher adversarial robustness may be related to a model's ability to activate the relevant skill neurons on adversarial data.
Separating form and meaning: Using self-consistency to quantify task understanding across multiple senses
May 23, 2023At the staggering pace with which the capabilities of large language models (LLMs) are increasing, creating future-proof evaluation sets to assess their understanding becomes more and more challenging. In this paper, we propose a novel paradigm for evaluating LLMs which leverages the idea that correct world understanding should be consistent across different (Fregean) senses of the same meaning. Accordingly, we measure understanding not in terms of correctness but by evaluating consistency across multiple senses that are generated by the model itself. We showcase our approach by instantiating a test where the different senses are different languages, hence using multilingual self-consistency as a litmus test for the model's understanding and simultaneously addressing the important topic of multilingualism. Taking one of the latest versions of ChatGPT as our object of study, we evaluate multilingual consistency for two different tasks across three different languages. We show that its multilingual consistency is still lacking, and that its task and world understanding are thus not language-independent. As our approach does not require any static evaluation corpora in languages other than English, it can easily and cheaply be extended to different languages and tasks and could become an integral part of future benchmarking efforts.
Emergence of hierarchical reference systems in multi-agent communication
Mar 24, 2022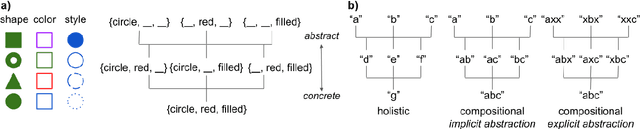

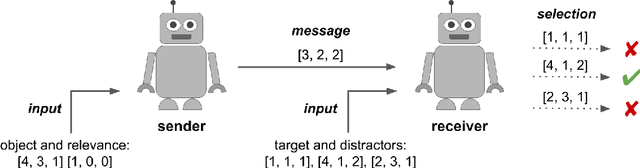
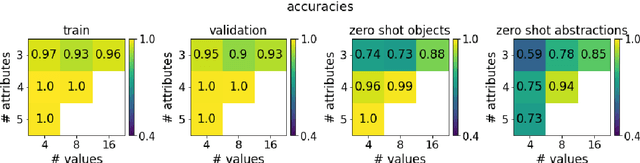
In natural language, referencing objects at different levels of specificity is a fundamental pragmatic mechanism for efficient communication in context. We develop a novel communication game, the hierarchical reference game, to study the emergence of such reference systems in artificial agents. We consider a simplified world, in which concepts are abstractions over a set of primitive attributes (e.g., color, style, shape). Depending on how many attributes are combined, concepts are more general ("circle") or more specific ("red dotted circle"). Based on the context, the agents have to communicate at different levels of this hierarchy. Our results show, that the agents learn to play the game successfully and can even generalize to novel concepts. To achieve abstraction, they use implicit (omitting irrelevant information) and explicit (indicating that attributes are irrelevant) strategies. In addition, the compositional structure underlying the concept hierarchy is reflected in the emergent protocols, indicating that the need to develop hierarchical reference systems supports the emergence of compositionality.