 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixels to Principles: Probing Intuitive Physics Understanding in Multimodal Language Models
Jul 22, 2025This paper presents a systematic evaluation of state-of-the-art multimodal large language models (MLLMs) on intuitive physics tasks using the GRASP and IntPhys 2 datasets. We assess the open-source models InternVL 2.5, Qwen 2.5 VL, LLaVA-OneVision, and the proprietary Gemini 2.0 Flash Thinking, finding that even the latest models struggle to reliably distinguish physically plausible from implausible scenarios. To go beyond performance metrics, we conduct a probing analysis of model embeddings, extracting intermediate representations at key processing stages to examine how well task-relevant information is preserved. Our results show that, depending on task difficulty, a critical vision-language misalignment can emerge: vision encoders successfully capture physical plausibility cues, but this information is not effectively utilized by the language model, leading to failures in reasoning. This misalignment suggests that the primary limitation of MLLMs in intuitive physics tasks is not the vision component but the ineffective integration of visual and linguistic information. Our findings highlight vision-language alignment as a key area for improvement, offering insights for future MLLMs development.
iVISPAR -- An Interactive Visual-Spatial Reasoning Benchmark for VLMs
Feb 05, 2025Vision-Language Models (VLMs) are known to struggle with spatial reasoning and visual alignment. To help overcome these limitations, we introduce iVISPAR, an interactive multi-modal benchmark designed to evaluate the spatial reasoning capabilities of VLMs acting as agents. iVISPAR is based on a variant of the sliding tile puzzle-a classic problem that demands logical planning, spatial awareness, and multi-step reasoning. The benchmark supports visual 2D, 3D, and text-based input modalities, enabling comprehensive assessments of VLMs' planning and reasoning skills. We evaluate a broad suite of state-of-the-art open-source and closed-source VLMs, comparing their performance while also providing optimal path solutions and a human baseline to assess the task's complexity and feasibility for humans. Results indicate that while some VLMs perform well on simple spatial tasks, they encounter difficulties with more complex configurations and problem properties. Notably, while VLMs generally perform better in 2D vision compared to 3D or text-based representations, they consistently fall short of human performance, illustrating the persistent challenge of visual alignment. This highlights critical gaps in current VLM capabilities, highlighting their limitations in achieving human-level cognition.
GRASP: A novel benchmark for evaluating language GRounding And Situated Physics understanding in multimodal language models
Nov 15, 2023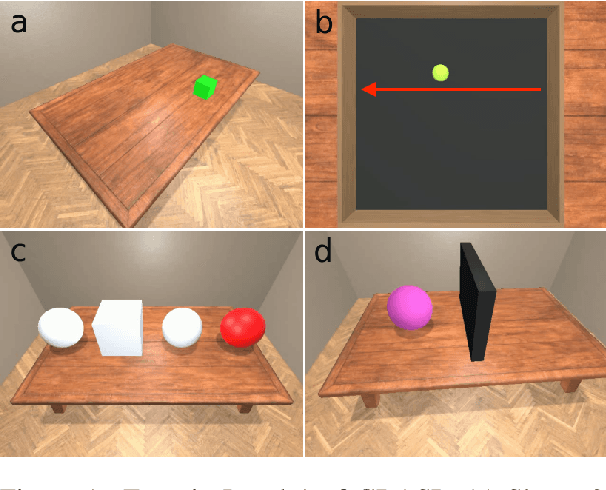
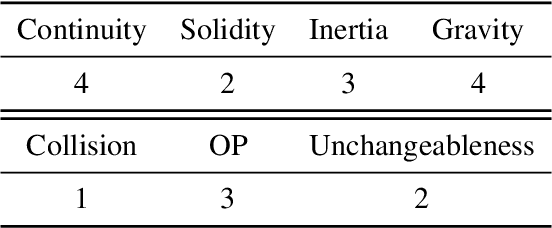

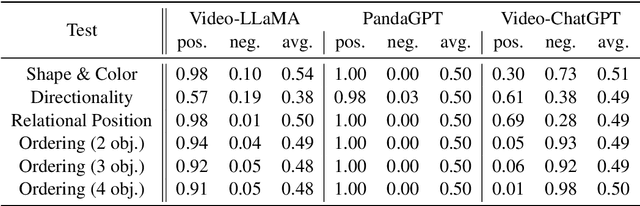
This paper presents GRASP, a novel benchmark to evaluate the language grounding and physical understanding capabilities of video-based multimodal large language models (LLMs). This evaluation is accomplished via a two-tier approach leveraging Unity simulations. The initial level tests for language grounding by assessing a model's ability to relate simple textual descriptions with visual information. The second level evaluates the model's understanding of 'Intuitive Physics' principles, such as object permanence and continuity. In addition to releasing the benchmark, we use it to evaluate several state-of-the-art multimodal LLMs. Our evaluation reveals significant shortcomings in current models' language grounding and intuitive physics. These identified limitations underline the importance of benchmarks like GRASP to monitor the progress of future models in developing these competencies.