 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre We Asking the Right Questions? On Ambiguity in Natural Language Queries for Tabular Data Analysis
Nov 06, 2025Natural language interfaces to tabular data must handle ambiguities inherent to queries. Instead of treating ambiguity as a deficiency, we reframe it as a feature of cooperative interaction, where the responsibility of query specification is shared among the user and the system. We develop a principled framework distinguishing cooperative queries, i.e., queries that yield a resolvable interpretation, from uncooperative queries that cannot be resolved. Applying the framework to evaluations for tabular question answering and analysis, we analyze the queries in 15 popular datasets, and observe an uncontrolled mixing of query types neither adequate for evaluating a system's execution accuracy nor for evaluating interpretation capabilities. Our framework and analysis of queries shifts the perspective from fixing ambiguity to embracing cooperation in resolving queries. This reflection enables more informed design and evaluation for natural language interfaces for tabular data, for which we outline implications and directions for future research.
How well do LLMs reason over tabular data, really?
May 12, 2025Large Language Models (LLMs) excel in natural language tasks, but less is known about their reasoning capabilities over tabular data. Prior analyses devise evaluation strategies that poorly reflect an LLM's realistic performance on tabular queries. Moreover, we have a limited understanding of the robustness of LLMs towards realistic variations in tabular inputs. Therefore, we ask: Can general-purpose LLMs reason over tabular data, really?, and focus on two questions 1) are tabular reasoning capabilities of general-purpose LLMs robust to real-world characteristics of tabular inputs, and 2) how can we realistically evaluate an LLM's performance on analytical tabular queries? Building on a recent tabular reasoning benchmark, we first surface shortcomings of its multiple-choice prompt evaluation strategy, as well as commonly used free-form text metrics such as SacreBleu and BERT-score. We show that an LLM-as-a-judge procedure yields more reliable performance insights and unveil a significant deficit in tabular reasoning performance of LLMs. We then extend the tabular inputs reflecting three common characteristics in practice: 1) missing values, 2) duplicate entities, and 3) structural variations. Experiments show that the tabular reasoning capabilities of general-purpose LLMs suffer from these variations, stressing the importance of improving their robustness for realistic tabular inputs.
Emergent Language in Open-Ended Environments
Aug 26, 2024Emergent language research has made significant progress in recent years, but still largely fails to explore how communication emerges in more complex and situated multi-agent systems. Existing setups often employ a reference game, which limits the range of language emergence phenomena that can be studied, as the game consists of a single, purely language-based interaction between the agents. In this paper, we address these limitations and explore the emergence and utility of token-based communication in open-ended multi-agent environments, where situated agents interact with the environment through movement and communication over multiple time-steps. Specifically, we introduce two novel cooperative environments: Multi-Agent Pong and Collectors. These environments are interesting because optimal performance requires the emergence of a communication protocol, but moderate success can be achieved without one. By employing various methods from explainable AI research, such as saliency maps, perturbation, and diagnostic classifiers, we are able to track and interpret the agents' language channel use over time. We find that the emerging communication is sparse, with the agents only generating meaningful messages and acting upon incoming messages in states where they cannot succeed without coordination.
A Review of Nine Physics Engines for Reinforcement Learning Research
Jul 11, 2024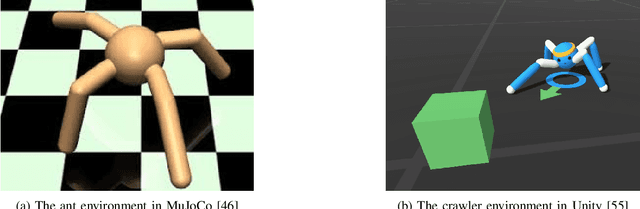



We present a review of popular simulation engines and frameworks used in reinforcement learning (RL) research, aiming to guide researchers in selecting tools for creating simulated physical environments for RL and training setups. It evaluates nine frameworks (Brax, Chrono, Gazebo, MuJoCo, ODE, PhysX, PyBullet, Webots, and Unity) based on their popularity, feature range, quality, usability, and RL capabilities. We highlight the challenges in selecting and utilizing physics engines for RL research, including the need for detailed comparisons and an understanding of each framework's capabilities. Key findings indicate MuJoCo as the leading framework due to its performance and flexibility, despite usability challenges. Unity is noted for its ease of use but lacks scalability and simulation fidelity. The study calls for further development to improve simulation engines' usability and performance and stresses the importance of transparency and reproducibility in RL research. This review contributes to the RL community by offering insights into the selection process for simulation engines, facilitating informed decision-making.
GRASP: A novel benchmark for evaluating language GRounding And Situated Physics understanding in multimodal language models
Nov 15, 2023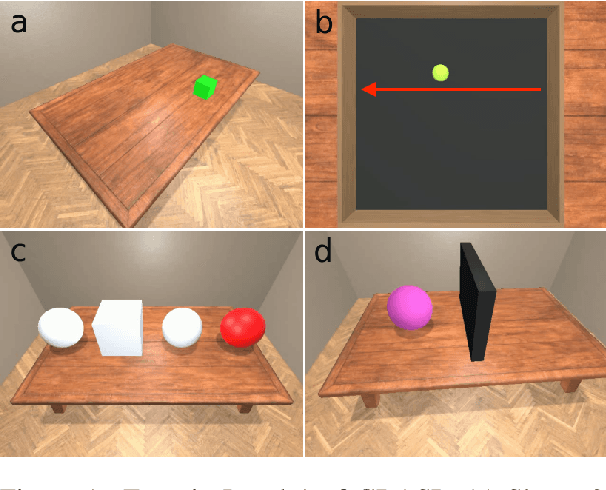
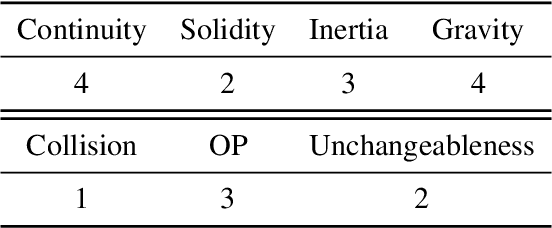

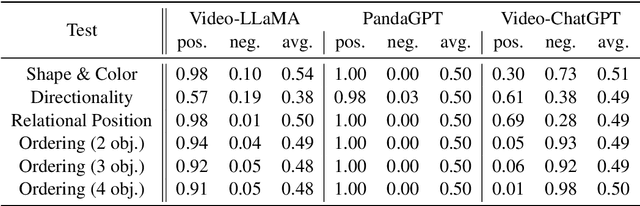
This paper presents GRASP, a novel benchmark to evaluate the language grounding and physical understanding capabilities of video-based multimodal large language models (LLMs). This evaluation is accomplished via a two-tier approach leveraging Unity simulations. The initial level tests for language grounding by assessing a model's ability to relate simple textual descriptions with visual information. The second level evaluates the model's understanding of 'Intuitive Physics' principles, such as object permanence and continuity. In addition to releasing the benchmark, we use it to evaluate several state-of-the-art multimodal LLMs. Our evaluation reveals significant shortcomings in current models' language grounding and intuitive physics. These identified limitations underline the importance of benchmarks like GRASP to monitor the progress of future models in developing these competencies.