 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpening the Black Box: Analyzing Attention Weights and Hidden States in Pre-trained Language Models for Non-language Tasks
Paper and Code
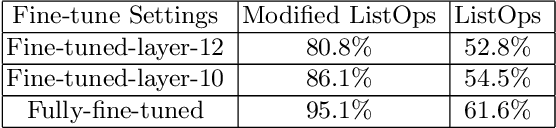


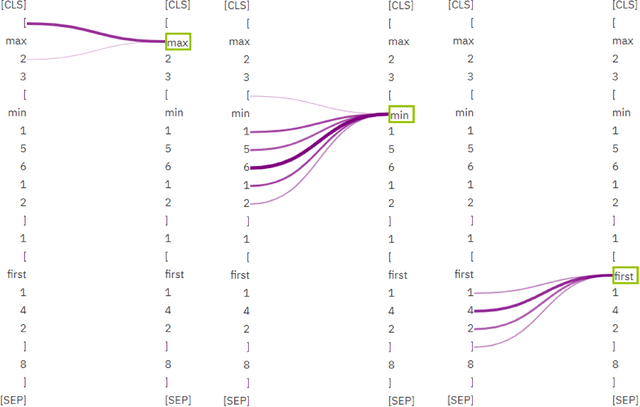
Investigating deep learning language models has always been a significant research area due to the ``black box" nature of most advanced models. With the recent advancements in pre-trained language models based on transformers and their increasing integration into daily life, addressing this issue has become more pressing. In order to achieve an explainable AI model, it is essential to comprehend the procedural steps involved and compare them with human thought processes. Thus, in this paper, we use simple, well-understood non-language tasks to explore these models' inner workings. Specifically, we apply a pre-trained language model to constrained arithmetic problems with hierarchical structure, to analyze their attention weight scores and hidden states. The investigation reveals promising results, with the model addressing hierarchical problems in a moderately structured manner, similar to human problem-solving strategies. Additionally, by inspecting the attention weights layer by layer, we uncover an unconventional finding that layer 10, rather than the model's final layer, is the optimal layer to unfreeze for the least parameter-intensive approach to fine-tune the model. We support these findings with entropy analysis and token embeddings similarity analysis. The attention analysis allows us to hypothesize that the model can generalize to longer sequences in ListOps dataset, a conclusion later confirmed through testing on sequences longer than those in the training set. Lastly, by utilizing a straightforward task in which the model predicts the winner of a Tic Tac Toe game, we identify limitations in attention analysis, particularly its inability to capture 2D patterns.