 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Self-Supervised Learning of Speech Representation via Invariance and Redundancy Reduction
Paper and Code
Sep 07, 2023


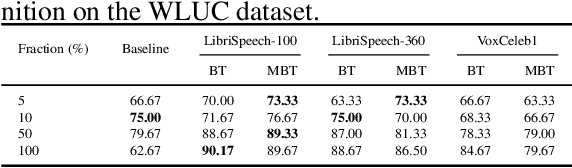
The choice of the objective function is crucial in emerging high-quality representations from self-supervised learning. This paper investigates how different formulations of the Barlow Twins (BT) objective impact downstream task performance for speech data. We propose Modified Barlow Twins (MBT) with normalized latents to enforce scale-invariance and evaluate on speaker identification, gender recognition and keyword spotting tasks. Our results show MBT improves representation generalization over original BT, especially when fine-tuning with limited target data. This highlights the importance of designing objectives that encourage invariant and transferable representations. Our analysis provides insights into how the BT learning objective can be tailored to produce speech representations that excel when adapted to new downstream tasks. This study is an important step towards developing reusable self-supervised speech representations.