 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Disentangled Speech Representations
Paper and Code
Nov 04, 2023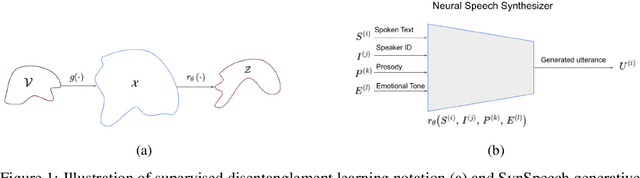
Disentangled representation learning from speech remains limited despite its importance in many application domains. A key challenge is the lack of speech datasets with known generative factors to evaluate methods. This paper proposes SynSpeech: a novel synthetic speech dataset with ground truth factors enabling research on disentangling speech representations. We plan to present a comprehensive study evaluating supervised techniques using established supervised disentanglement metrics. This benchmark dataset and framework address the gap in the rigorous evaluation of state-of-the-art disentangled speech representation learning methods. Our findings will provide insights to advance this underexplored area and enable more robust speech representations.