 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovenant-72B: Pre-Training a 72B LLM with Trustless Peers Over-the-Internet
Mar 10, 2026Recently, there has been increased interest in globally distributed training, which has the promise to both reduce training costs and democratize participation in building large-scale foundation models. However, existing models trained in a globally distributed manner are relatively small in scale and have only been trained with whitelisted participants. Therefore, they do not yet realize the full promise of democratized participation. In this report, we describe Covenant-72B, an LLM produced by the largest collaborative globally distributed pre-training run (in terms of both compute and model scale), which simultaneously allowed open, permissionless participation supported by a live blockchain protocol. We utilized a state-of-the-art communication-efficient optimizer, SparseLoCo, supporting dynamic participation with peers joining and leaving freely. Our model, pre-trained on approximately 1.1T tokens, performs competitively with fully centralized models pre-trained on similar or higher compute budgets, demonstrating that fully democratized, non-whitelisted participation is not only feasible, but can be achieved at unprecedented scale for a globally distributed pre-training run.
MuLoCo: Muon is a practical inner optimizer for DiLoCo
May 29, 2025DiLoCo is a powerful framework for training large language models (LLMs) under networking constraints with advantages for increasing parallelism and accelerator utilization in data center settings. Despite significantly reducing communication frequency, however, DiLoCo's communication steps still involve all-reducing a complete copy of the model's parameters. While existing works have explored ways to reduce communication in DiLoCo, the role of error feedback accumulators and the effect of the inner-optimizer on compressibility remain under-explored. In this work, we investigate the effectiveness of standard compression methods including Top-k sparsification and quantization for reducing the communication overhead of DiLoCo when paired with two local optimizers (AdamW and Muon). Our experiments pre-training decoder-only transformer language models (LMs) reveal that leveraging Muon as the inner optimizer for DiLoCo along with an error-feedback accumulator allows to aggressively compress the communicated delta to 2-bits with next to no performance degradation. Crucially, MuLoCo (Muon inner optimizer DiLoCo) significantly outperforms DiLoCo while communicating 8X less and having identical memory complexity.
Beyond Cosine Decay: On the effectiveness of Infinite Learning Rate Schedule for Continual Pre-training
Mar 06, 2025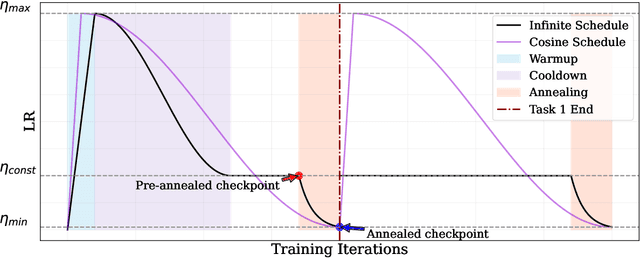

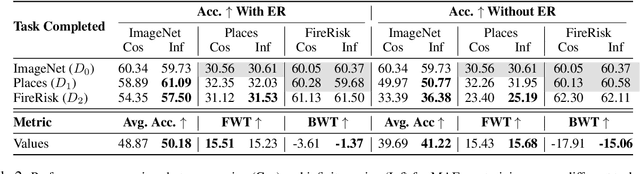
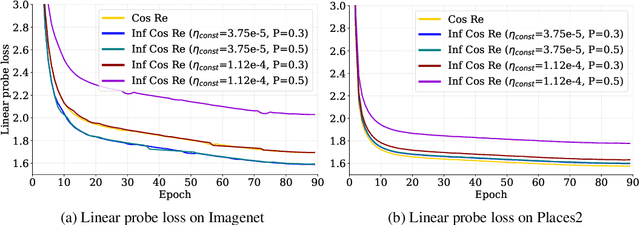
The ever-growing availability of unlabeled data presents both opportunities and challenges for training artificial intelligence systems. While self-supervised learning (SSL) has emerged as a powerful paradigm for extracting meaningful representations from vast amounts of unlabeled data, existing methods still struggle to adapt to the non-stationary, non-IID nature of real-world data streams without forgetting previously learned knowledge. Recent works have adopted a repeated cosine annealing schedule for large-scale continual pre-training; however, these schedules (1) inherently cause forgetting during the re-warming phase and (2) have not been systematically compared to existing continual SSL methods. In this work, we systematically compare the widely used cosine schedule with the recently proposed infinite learning rate schedule and empirically find the latter to be a more effective alternative. Our extensive empirical evaluation across diverse image and language datasets demonstrates that the infinite learning rate schedule consistently enhances continual pre-training performance compared to a repeated cosine decay without being restricted to a fixed iteration budget. For instance, in a small-scale MAE pre-training setup, it outperforms several strong baselines from the literature. We then scale up our experiments to larger MAE pre-training and autoregressive language model pre-training. Our results show that the infinite learning rate schedule remains effective at scale, surpassing repeated cosine decay for both MAE pre-training and zero-shot LM benchmarks.
Continual Pre-training of MoEs: How robust is your router?
Mar 06, 2025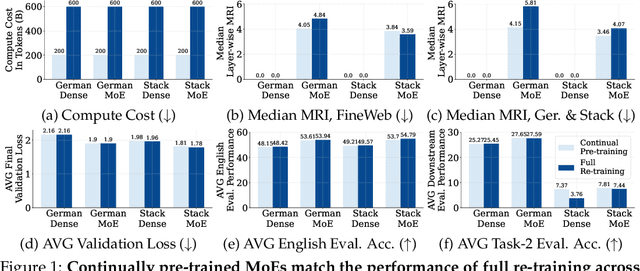
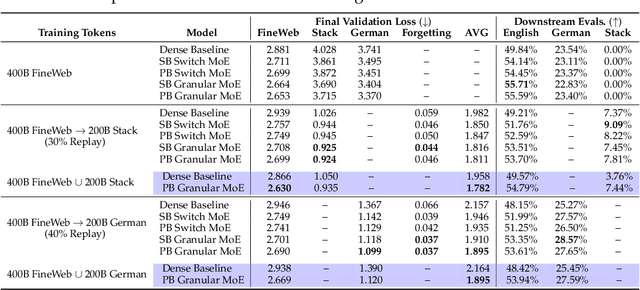
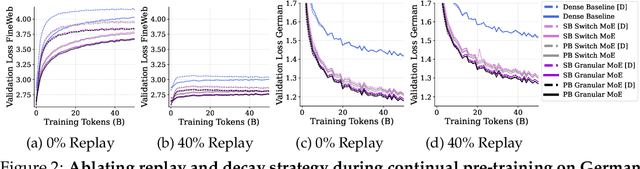
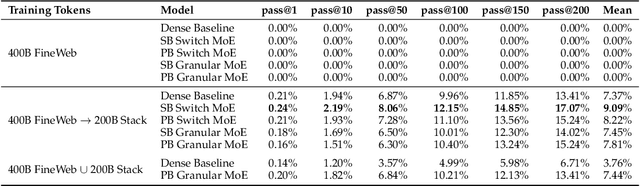
Sparsely-activated Mixture of Experts (MoE) transformers are promising architectures for foundation models. Compared to dense transformers that require the same amount of floating point operations (FLOPs) per forward pass, MoEs benefit from improved sample efficiency at training time and achieve much stronger performance. Many closed-source and open-source frontier language models have thus adopted an MoE architecture. Naturally, practitioners will want to extend the capabilities of these models with large amounts of newly collected data without completely re-training them. Prior work has shown that a simple combination of replay and learning rate re-warming and re-decaying can enable the continual pre-training (CPT) of dense decoder-only transformers with minimal performance degradation compared to full re-training. In the case of decoder-only MoE transformers, however, it is unclear how the routing algorithm will impact continual pre-training performance: 1) do the MoE transformer's routers exacerbate forgetting relative to a dense model?; 2) do the routers maintain a balanced load on previous distributions after CPT?; 3) are the same strategies applied to dense models sufficient to continually pre-train MoE LLMs? In what follows, we conduct a large-scale (>2B parameter switch and DeepSeek MoE LLMs trained for 600B tokens) empirical study across four MoE transformers to answer these questions. Our results establish a surprising robustness to distribution shifts for both Sinkhorn-Balanced and Z-and-Aux-loss-balanced routing algorithms, even in MoEs continually pre-trained without replay. Moreover, we show that MoE LLMs maintain their sample efficiency (relative to a FLOP-matched dense model) during CPT and that they can match the performance of a fully re-trained MoE at a fraction of the cost.
$μ$LO: Compute-Efficient Meta-Generalization of Learned Optimizers
May 31, 2024



Learned optimizers (LOs) can significantly reduce the wall-clock training time of neural networks, substantially reducing training costs. However, they often suffer from poor meta-generalization, especially when training networks larger than those seen during meta-training. To address this, we use the recently proposed Maximal Update Parametrization ($\mu$P), which allows zero-shot generalization of optimizer hyperparameters from smaller to larger models. We extend $\mu$P theory to learned optimizers, treating the meta-training problem as finding the learned optimizer under $\mu$P. Our evaluation shows that LOs meta-trained with $\mu$P substantially improve meta-generalization as compared to LOs trained under standard parametrization (SP). Notably, when applied to large-width models, our best $\mu$LO, trained for 103 GPU-hours, matches or exceeds the performance of VeLO, the largest publicly available learned optimizer, meta-trained with 4000 TPU-months of compute. Moreover, $\mu$LOs demonstrate better generalization than their SP counterparts to deeper networks and to much longer training horizons (25 times longer) than those seen during meta-training.
Simple and Scalable Strategies to Continually Pre-train Large Language Models
Mar 26, 2024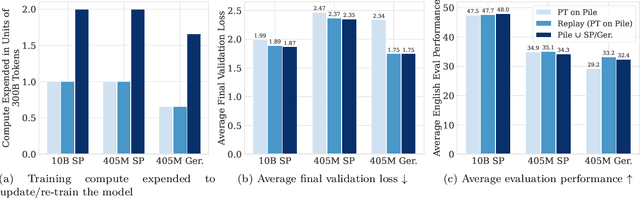
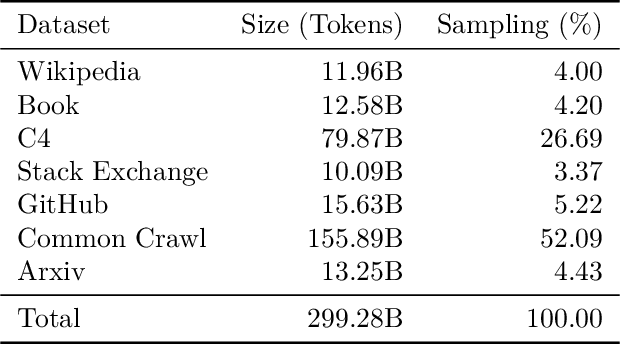
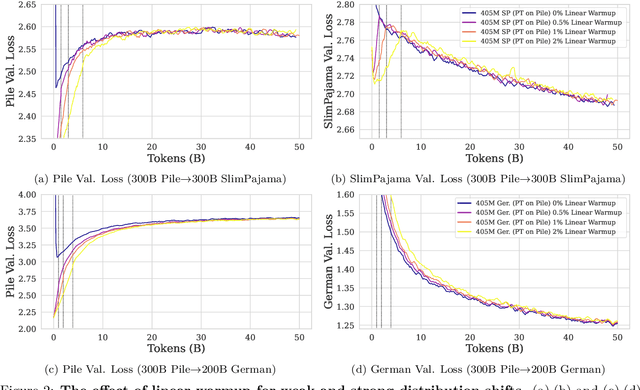
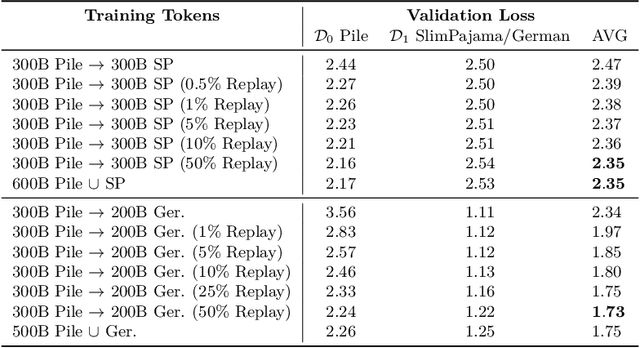
Large language models (LLMs) are routinely pre-trained on billions of tokens, only to start the process over again once new data becomes available. A much more efficient solution is to continually pre-train these models, saving significant compute compared to re-training. However, the distribution shift induced by new data typically results in degraded performance on previous data or poor adaptation to the new data. In this work, we show that a simple and scalable combination of learning rate (LR) re-warming, LR re-decaying, and replay of previous data is sufficient to match the performance of fully re-training from scratch on all available data, as measured by the final loss and the average score on several language model (LM) evaluation benchmarks. Specifically, we show this for a weak but realistic distribution shift between two commonly used LLM pre-training datasets (English$\rightarrow$English) and a stronger distribution shift (English$\rightarrow$German) at the $405$M parameter model scale with large dataset sizes (hundreds of billions of tokens). Selecting the weak but realistic shift for larger-scale experiments, we also find that our continual learning strategies match the re-training baseline for a 10B parameter LLM. Our results demonstrate that LLMs can be successfully updated via simple and scalable continual learning strategies, matching the re-training baseline using only a fraction of the compute. Finally, inspired by previous work, we propose alternatives to the cosine learning rate schedule that help circumvent forgetting induced by LR re-warming and that are not bound to a fixed token budget.
Can We Learn Communication-Efficient Optimizers?
Dec 02, 2023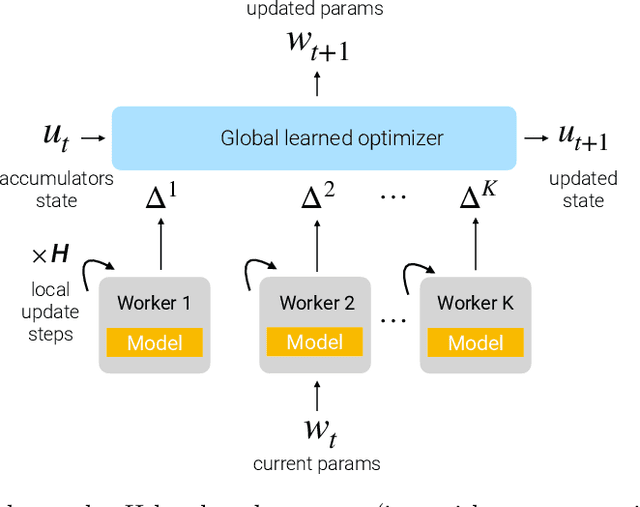

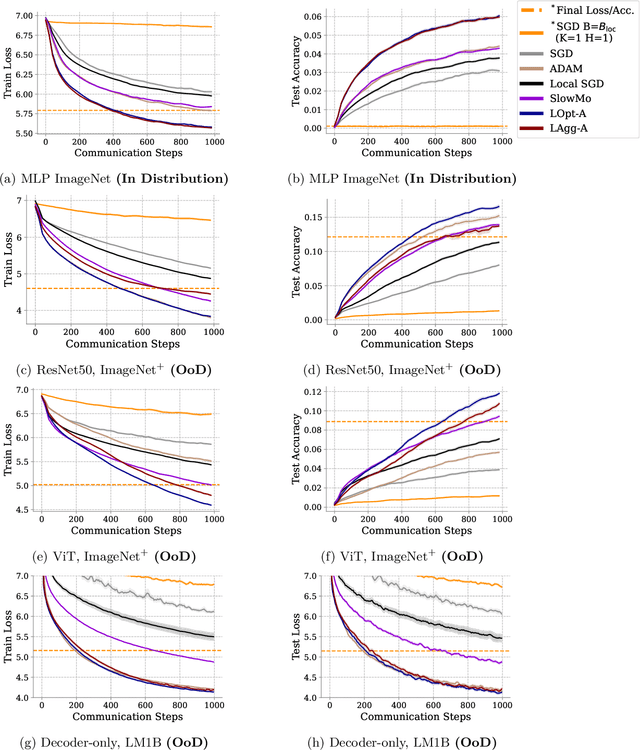
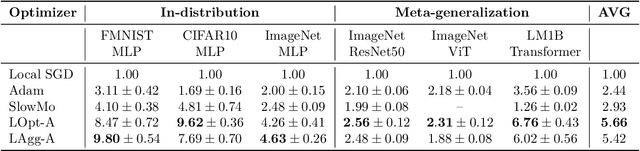
Communication-efficient variants of SGD, specifically local SGD, have received a great deal of interest in recent years. These approaches compute multiple gradient steps locally, that is on each worker, before averaging model parameters, helping relieve the critical communication bottleneck in distributed deep learning training. Although many variants of these approaches have been proposed, they can sometimes lag behind state-of-the-art adaptive optimizers for deep learning. In this work, we investigate if the recent progress in the emerging area of learned optimizers can potentially close this gap while remaining communication-efficient. Specifically, we meta-learn how to perform global updates given an update from local SGD iterations. Our results demonstrate that learned optimizers can substantially outperform local SGD and its sophisticated variants while maintaining their communication efficiency. Learned optimizers can even generalize to unseen and much larger datasets and architectures, including ImageNet and ViTs, and to unseen modalities such as language modeling. We therefore demonstrate the potential of learned optimizers for improving communication-efficient distributed learning.
Continual Pre-Training of Large Language Models: How to (re)warm your model?
Aug 08, 2023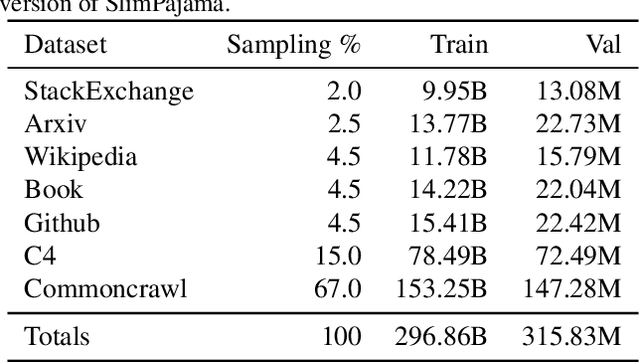
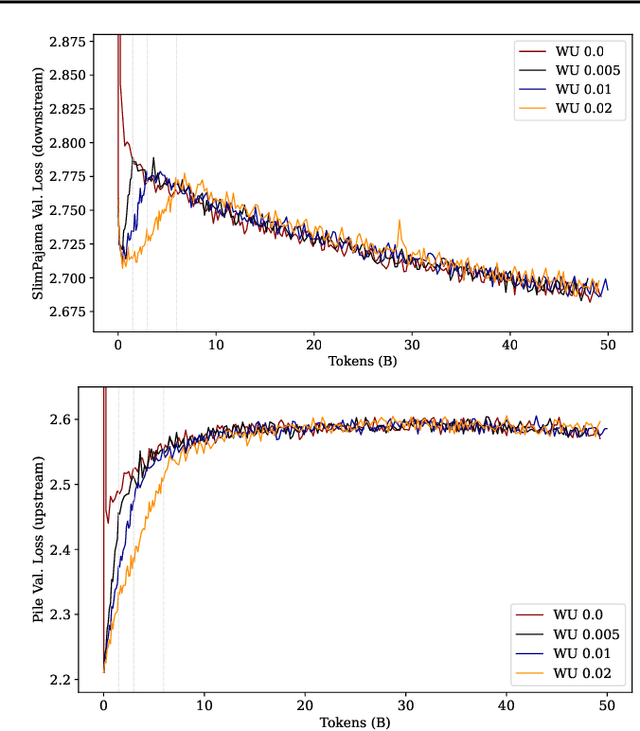
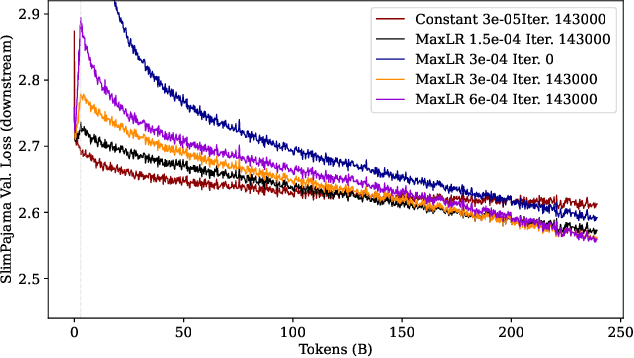
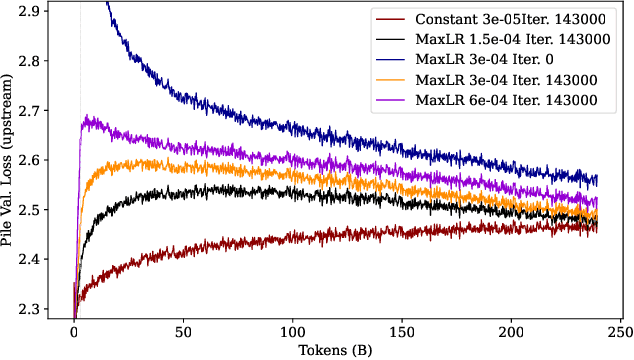
Large language models (LLMs) are routinely pre-trained on billions of tokens, only to restart the process over again once new data becomes available. A much cheaper and more efficient solution would be to enable the continual pre-training of these models, i.e. updating pre-trained models with new data instead of re-training them from scratch. However, the distribution shift induced by novel data typically results in degraded performance on past data. Taking a step towards efficient continual pre-training, in this work, we examine the effect of different warm-up strategies. Our hypothesis is that the learning rate must be re-increased to improve compute efficiency when training on a new dataset. We study the warmup phase of models pre-trained on the Pile (upstream data, 300B tokens) as we continue to pre-train on SlimPajama (downstream data, 297B tokens), following a linear warmup and cosine decay schedule. We conduct all experiments on the Pythia 410M language model architecture and evaluate performance through validation perplexity. We experiment with different pre-training checkpoints, various maximum learning rates, and various warmup lengths. Our results show that while rewarming models first increases the loss on upstream and downstream data, in the longer run it improves the downstream performance, outperforming models trained from scratch$\unicode{x2013}$even for a large downstream dataset.
Towards Object Re-Identification from Point Clouds for 3D MOT
May 17, 2023In this work, we study the problem of object re-identification (ReID) in a 3D multi-object tracking (MOT) context, by learning to match pairs of objects from cropped (e.g., using their predicted 3D bounding boxes) point cloud observations. We are not concerned with SOTA performance for 3D MOT, however. Instead, we seek to answer the following question: In a realistic tracking by-detection context, how does object ReID from point clouds perform relative to ReID from images? To enable such a study, we propose a lightweight matching head that can be concatenated to any set or sequence processing backbone (e.g., PointNet or ViT), creating a family of comparable object ReID networks for both modalities. Run in siamese style, our proposed point-cloud ReID networks can make thousands of pairwise comparisons in real-time (10 hz). Our findings demonstrate that their performance increases with higher sensor resolution and approaches that of image ReID when observations are sufficiently dense. Additionally, we investigate our network's ability to enhance 3D multi-object tracking (MOT), showing that our point-cloud ReID networks can successfully re-identify objects which led a strong motion-based tracker into error. To our knowledge, we are the first to study real-time object re-identification from point clouds in a 3D multi-object tracking context.
A Closer Look at Robustness to L-infinity and Spatial Perturbations and their Composition
Oct 05, 2022
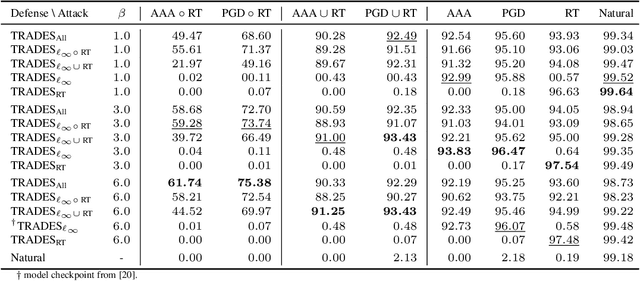
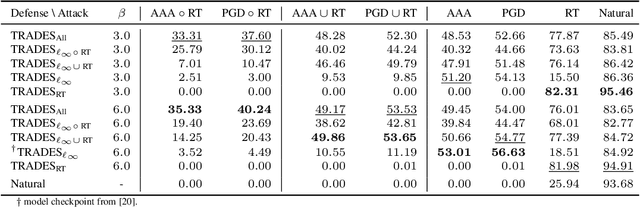
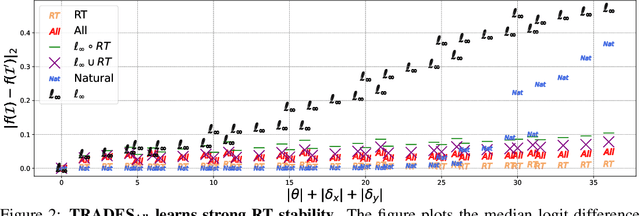
In adversarial machine learning, the popular $\ell_\infty$ threat model has been the focus of much previous work. While this mathematical definition of imperceptibility successfully captures an infinite set of additive image transformations that a model should be robust to, this is only a subset of all transformations which leave the semantic label of an image unchanged. Indeed, previous work also considered robustness to spatial attacks as well as other semantic transformations; however, designing defense methods against the composition of spatial and $\ell_{\infty}$ perturbations remains relatively underexplored. In the following, we improve the understanding of this seldom investigated compositional setting. We prove theoretically that no linear classifier can achieve more than trivial accuracy against a composite adversary in a simple statistical setting, illustrating its difficulty. We then investigate how state-of-the-art $\ell_{\infty}$ defenses can be adapted to this novel threat model and study their performance against compositional attacks. We find that our newly proposed TRADES$_{\text{All}}$ strategy performs the strongest of all. Analyzing its logit's Lipschitz constant for RT transformations of different sizes, we find that TRADES$_{\text{All}}$ remains stable over a wide range of RT transformations with and without $\ell_\infty$ perturbations.