 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCelo2: Towards Learned Optimization Free Lunch
Feb 22, 2026Learned optimizers are powerful alternatives to hand-designed update rules like Adam, yet they have seen limited practical adoption since they often fail to meta-generalize beyond their training distribution and incur high meta-training cost. For instance, prior work, VeLO, scaled meta-training to 4,000 TPU months ($\sim$10$\times$ GPT-3 compute) to meta-train a general-purpose optimizer but it failed to generalize beyond 600M parameters tasks. In this work, we present a surprising finding: by crafting a simple normalized optimizer architecture and augmenting meta-training, it becomes feasible to meta-train a performant general-purpose learned update rule on a tiny fraction of VeLO compute, 4.5 GPU hours to be precise. Our learned update rule scales stably to a billion-scale pretraining task (GPT-3 XL 1.3B) which is six orders of magnitude larger than its meta-training distribution. Furthermore, it shows strong performance across diverse out-of-distribution tasks and is compatible with modern optimization harness that includes orthogonalization, distinct update rules for input-output and hidden weights, and decoupled weight decay. In all, this work paves the way for practically applicable learnable optimization algorithms, unlocking exploration of richer meta-training and data curation recipes to further improve performance.
AIRS-Bench: a Suite of Tasks for Frontier AI Research Science Agents
Feb 09, 2026LLM agents hold significant promise for advancing scientific research. To accelerate this progress, we introduce AIRS-Bench (the AI Research Science Benchmark), a suite of 20 tasks sourced from state-of-the-art machine learning papers. These tasks span diverse domains, including language modeling, mathematics, bioinformatics, and time series forecasting. AIRS-Bench tasks assess agentic capabilities over the full research lifecycle -- including idea generation, experiment analysis and iterative refinement -- without providing baseline code. The AIRS-Bench task format is versatile, enabling easy integration of new tasks and rigorous comparison across different agentic frameworks. We establish baselines using frontier models paired with both sequential and parallel scaffolds. Our results show that agents exceed human SOTA in four tasks but fail to match it in sixteen others. Even when agents surpass human benchmarks, they do not reach the theoretical performance ceiling for the underlying tasks. These findings indicate that AIRS-Bench is far from saturated and offers substantial room for improvement. We open-source the AIRS-Bench task definitions and evaluation code to catalyze further development in autonomous scientific research.
Understanding Input Selectivity in Mamba: Impact on Approximation Power, Memorization, and Associative Recall Capacity
Jun 13, 2025State-Space Models (SSMs), and particularly Mamba, have recently emerged as a promising alternative to Transformers. Mamba introduces input selectivity to its SSM layer (S6) and incorporates convolution and gating into its block definition. While these modifications do improve Mamba's performance over its SSM predecessors, it remains largely unclear how Mamba leverages the additional functionalities provided by input selectivity, and how these interact with the other operations in the Mamba architecture. In this work, we demystify the role of input selectivity in Mamba, investigating its impact on function approximation power, long-term memorization, and associative recall capabilities. In particular: (i) we prove that the S6 layer of Mamba can represent projections onto Haar wavelets, providing an edge over its Diagonal SSM (S4D) predecessor in approximating discontinuous functions commonly arising in practice; (ii) we show how the S6 layer can dynamically counteract memory decay; (iii) we provide analytical solutions to the MQAR associative recall task using the Mamba architecture with different mixers -- Mamba, Mamba-2, and S4D. We demonstrate the tightness of our theoretical constructions with empirical results on concrete tasks. Our findings offer a mechanistic understanding of Mamba and reveal opportunities for improvement.
PyLO: Towards Accessible Learned Optimizers in PyTorch
Jun 12, 2025Learned optimizers have been an active research topic over the past decade, with increasing progress toward practical, general-purpose optimizers that can serve as drop-in replacements for widely used methods like Adam. However, recent advances -- such as VeLO, which was meta-trained for 4000 TPU-months -- remain largely inaccessible to the broader community, in part due to their reliance on JAX and the absence of user-friendly packages for applying the optimizers after meta-training. To address this gap, we introduce PyLO, a PyTorch-based library that brings learned optimizers to the broader machine learning community through familiar, widely adopted workflows. Unlike prior work focused on synthetic or convex tasks, our emphasis is on applying learned optimization to real-world large-scale pre-training tasks. Our release includes a CUDA-accelerated version of the small_fc_lopt learned optimizer architecture from (Metz et al., 2022a), delivering substantial speedups -- from 39.36 to 205.59 samples/sec throughput for training ViT B/16 with batch size 32. PyLO also allows us to easily combine learned optimizers with existing optimization tools such as learning rate schedules and weight decay. When doing so, we find that learned optimizers can substantially benefit. Our code is available at https://github.com/Belilovsky-Lab/pylo
Accelerating Training with Neuron Interaction and Nowcasting Networks
Sep 06, 2024



Neural network training can be accelerated when a learnable update rule is used in lieu of classic adaptive optimizers (e.g. Adam). However, learnable update rules can be costly and unstable to train and use. A simpler recently proposed approach to accelerate training is to use Adam for most of the optimization steps and periodically, only every few steps, nowcast (predict future) parameters. We improve this approach by Neuron interaction and Nowcasting (NiNo) networks. NiNo leverages neuron connectivity and graph neural networks to more accurately nowcast parameters by learning in a supervised way from a set of training trajectories over multiple tasks. We show that in some networks, such as Transformers, neuron connectivity is non-trivial. By accurately modeling neuron connectivity, we allow NiNo to accelerate Adam training by up to 50\% in vision and language tasks.
Can We Learn Communication-Efficient Optimizers?
Dec 02, 2023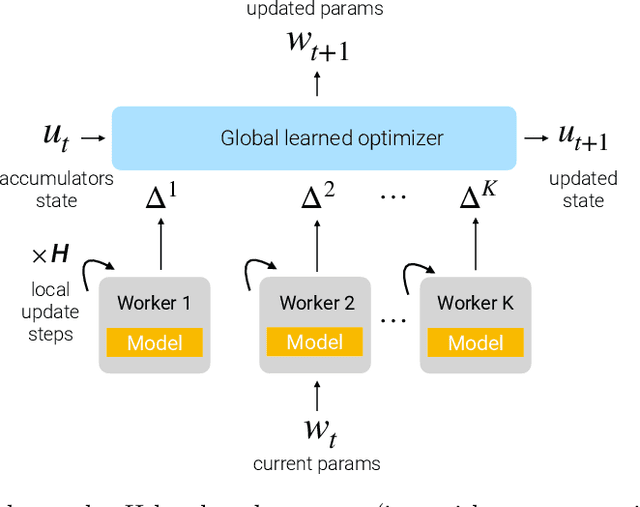

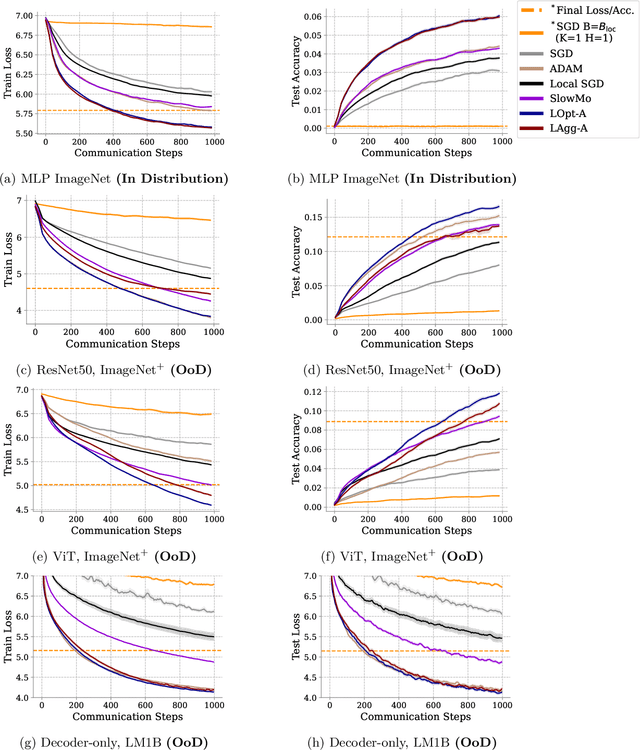
Communication-efficient variants of SGD, specifically local SGD, have received a great deal of interest in recent years. These approaches compute multiple gradient steps locally, that is on each worker, before averaging model parameters, helping relieve the critical communication bottleneck in distributed deep learning training. Although many variants of these approaches have been proposed, they can sometimes lag behind state-of-the-art adaptive optimizers for deep learning. In this work, we investigate if the recent progress in the emerging area of learned optimizers can potentially close this gap while remaining communication-efficient. Specifically, we meta-learn how to perform global updates given an update from local SGD iterations. Our results demonstrate that learned optimizers can substantially outperform local SGD and its sophisticated variants while maintaining their communication efficiency. Learned optimizers can even generalize to unseen and much larger datasets and architectures, including ImageNet and ViTs, and to unseen modalities such as language modeling. We therefore demonstrate the potential of learned optimizers for improving communication-efficient distributed learning.
Towards Scaling Difference Target Propagation by Learning Backprop Targets
Jan 31, 2022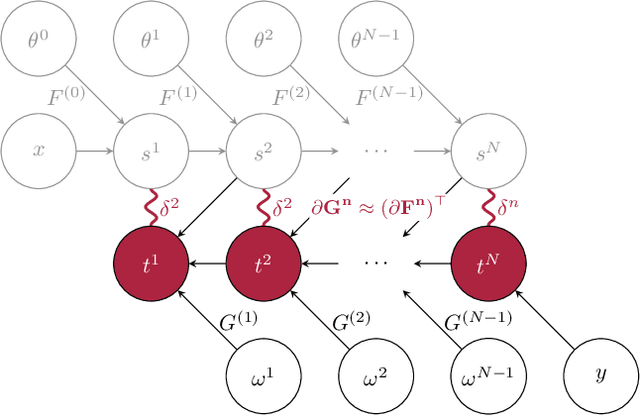

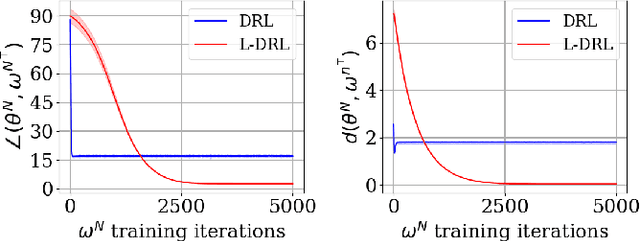

The development of biologically-plausible learning algorithms is important for understanding learning in the brain, but most of them fail to scale-up to real-world tasks, limiting their potential as explanations for learning by real brains. As such, it is important to explore learning algorithms that come with strong theoretical guarantees and can match the performance of backpropagation (BP) on complex tasks. One such algorithm is Difference Target Propagation (DTP), a biologically-plausible learning algorithm whose close relation with Gauss-Newton (GN) optimization has been recently established. However, the conditions under which this connection rigorously holds preclude layer-wise training of the feedback pathway synaptic weights (which is more biologically plausible). Moreover, good alignment between DTP weight updates and loss gradients is only loosely guaranteed and under very specific conditions for the architecture being trained. In this paper, we propose a novel feedback weight training scheme that ensures both that DTP approximates BP and that layer-wise feedback weight training can be restored without sacrificing any theoretical guarantees. Our theory is corroborated by experimental results and we report the best performance ever achieved by DTP on CIFAR-10 and ImageNet 32$\times$32
SOAT: A Scene- and Object-Aware Transformer for Vision-and-Language Navigation
Oct 27, 2021
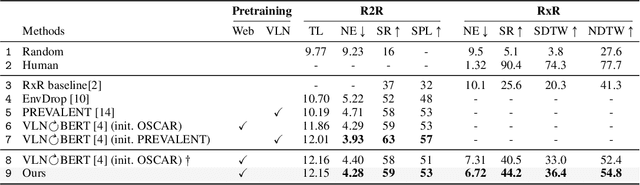
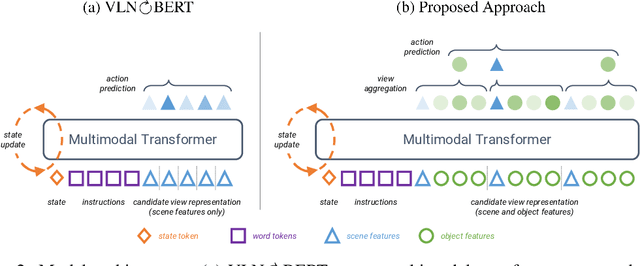
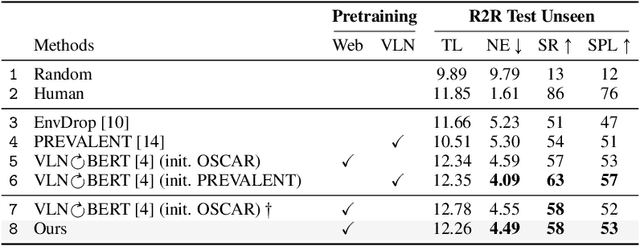
Natural language instructions for visual navigation often use scene descriptions (e.g., "bedroom") and object references (e.g., "green chairs") to provide a breadcrumb trail to a goal location. This work presents a transformer-based vision-and-language navigation (VLN) agent that uses two different visual encoders -- a scene classification network and an object detector -- which produce features that match these two distinct types of visual cues. In our method, scene features contribute high-level contextual information that supports object-level processing. With this design, our model is able to use vision-and-language pretraining (i.e., learning the alignment between images and text from large-scale web data) to substantially improve performance on the Room-to-Room (R2R) and Room-Across-Room (RxR) benchmarks. Specifically, our approach leads to improvements of 1.8% absolute in SPL on R2R and 3.7% absolute in SR on RxR. Our analysis reveals even larger gains for navigation instructions that contain six or more object references, which further suggests that our approach is better able to use object features and align them to references in the instructions.
Contrast and Classify: Alternate Training for Robust VQA
Oct 13, 2020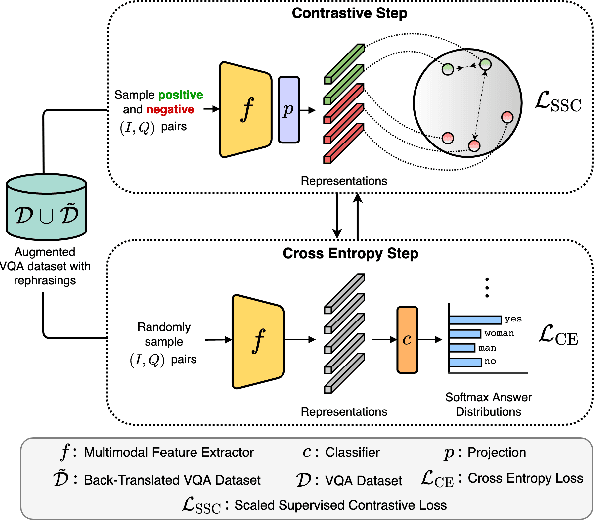
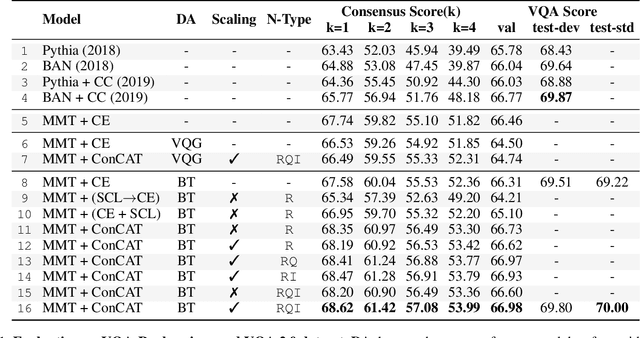
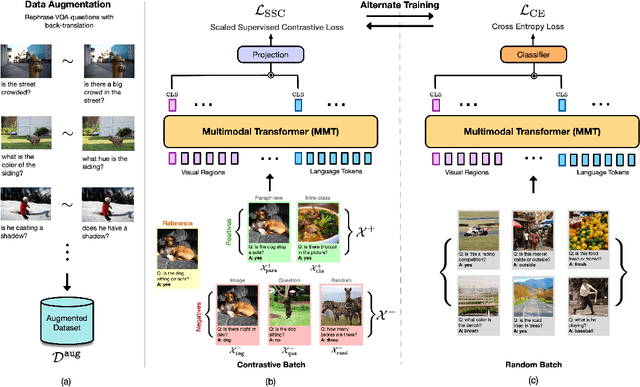
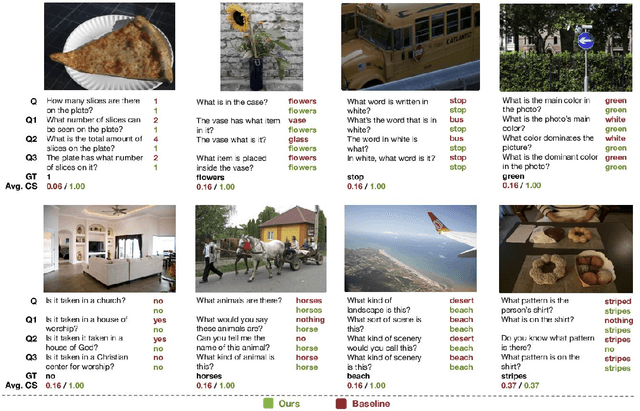
Recent Visual Question Answering (VQA) models have shown impressive performance on the VQA benchmark but remain sensitive to small linguistic variations in input questions. Existing approaches address this by augmenting the dataset with question paraphrases from visual question generation models or adversarial perturbations. These approaches use the combined data to learn an answer classifier by minimizing the standard cross-entropy loss. To more effectively leverage the augmented data, we build on the recent success in contrastive learning. We propose a novel training paradigm (ConCAT) that alternately optimizes cross-entropy and contrastive losses. The contrastive loss encourages representations to be robust to linguistic variations in questions while the cross-entropy loss preserves the discriminative power of the representations for answer classification. We find that alternately optimizing both losses is key to effective training. VQA models trained with ConCAT achieve higher consensus scores on the VQA-Rephrasings dataset as well as higher VQA accuracy on the VQA 2.0 dataset compared to existing approaches across a variety of data augmentation strategies.
Exploring 3 R's of Long-term Tracking: Re-detection, Recovery and Reliability
Oct 27, 2019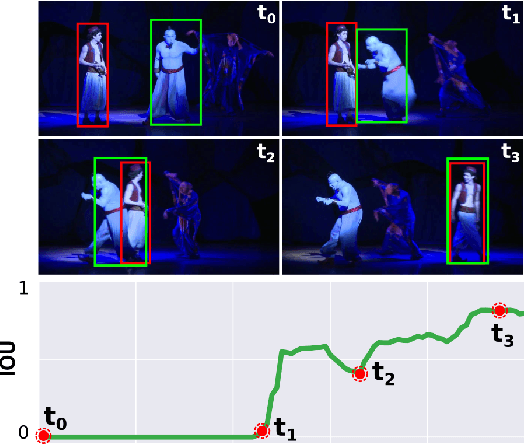

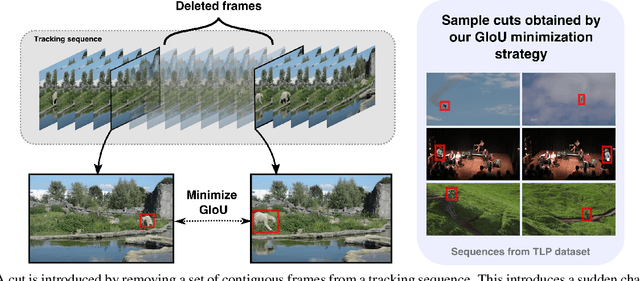
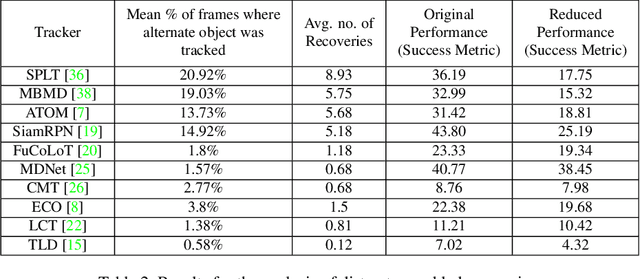
Recent works have proposed several long term tracking benchmarks and highlight the importance of moving towards long-duration tracking to bridge the gap with application requirements. The current evaluation methodologies, however, do not focus on several aspects that are crucial in a long term perspective like Re-detection, Recovery, and Reliability. In this paper, we propose novel evaluation strategies for a more in-depth analysis of trackers from a long-term perspective. More specifically, (a) we test re-detection capability of the trackers in the wild by simulating virtual cuts, (b) we investigate the role of chance in the recovery of tracker after failure and (c) we propose a novel metric allowing visual inference on the ability of a tracker to track contiguously (without any failure) at a given accuracy. We present several original insights derived from an extensive set of quantitative and qualitative experiments.