 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent cooperation through learning-aware policy gradients
Oct 24, 2024
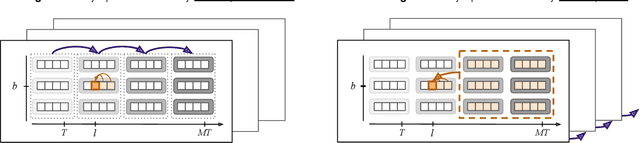
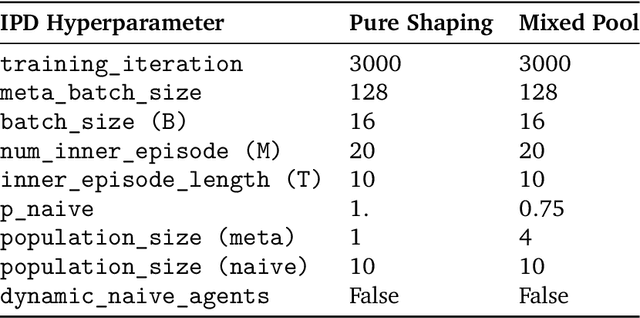

Self-interested individuals often fail to cooperate, posing a fundamental challenge for multi-agent learning. How can we achieve cooperation among self-interested, independent learning agents? Promising recent work has shown that in certain tasks cooperation can be established between learning-aware agents who model the learning dynamics of each other. Here, we present the first unbiased, higher-derivative-free policy gradient algorithm for learning-aware reinforcement learning, which takes into account that other agents are themselves learning through trial and error based on multiple noisy trials. We then leverage efficient sequence models to condition behavior on long observation histories that contain traces of the learning dynamics of other agents. Training long-context policies with our algorithm leads to cooperative behavior and high returns on standard social dilemmas, including a challenging environment where temporally-extended action coordination is required. Finally, we derive from the iterated prisoner's dilemma a novel explanation for how and when cooperation arises among self-interested learning-aware agents.
Towards a "universal translator" for neural dynamics at single-cell, single-spike resolution
Jul 23, 2024Neuroscience research has made immense progress over the last decade, but our understanding of the brain remains fragmented and piecemeal: the dream of probing an arbitrary brain region and automatically reading out the information encoded in its neural activity remains out of reach. In this work, we build towards a first foundation model for neural spiking data that can solve a diverse set of tasks across multiple brain areas. We introduce a novel self-supervised modeling approach for population activity in which the model alternates between masking out and reconstructing neural activity across different time steps, neurons, and brain regions. To evaluate our approach, we design unsupervised and supervised prediction tasks using the International Brain Laboratory repeated site dataset, which is comprised of Neuropixels recordings targeting the same brain locations across 48 animals and experimental sessions. The prediction tasks include single-neuron and region-level activity prediction, forward prediction, and behavior decoding. We demonstrate that our multi-task-masking (MtM) approach significantly improves the performance of current state-of-the-art population models and enables multi-task learning. We also show that by training on multiple animals, we can improve the generalization ability of the model to unseen animals, paving the way for a foundation model of the brain at single-cell, single-spike resolution.
Interpretability in Action: Exploratory Analysis of VPT, a Minecraft Agent
Jul 16, 2024Understanding the mechanisms behind decisions taken by large foundation models in sequential decision making tasks is critical to ensuring that such systems operate transparently and safely. In this work, we perform exploratory analysis on the Video PreTraining (VPT) Minecraft playing agent, one of the largest open-source vision-based agents. We aim to illuminate its reasoning mechanisms by applying various interpretability techniques. First, we analyze the attention mechanism while the agent solves its training task - crafting a diamond pickaxe. The agent pays attention to the last four frames and several key-frames further back in its six-second memory. This is a possible mechanism for maintaining coherence in a task that takes 3-10 minutes, despite the short memory span. Secondly, we perform various interventions, which help us uncover a worrying case of goal misgeneralization: VPT mistakenly identifies a villager wearing brown clothes as a tree trunk when the villager is positioned stationary under green tree leaves, and punches it to death.
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
Apr 02, 2024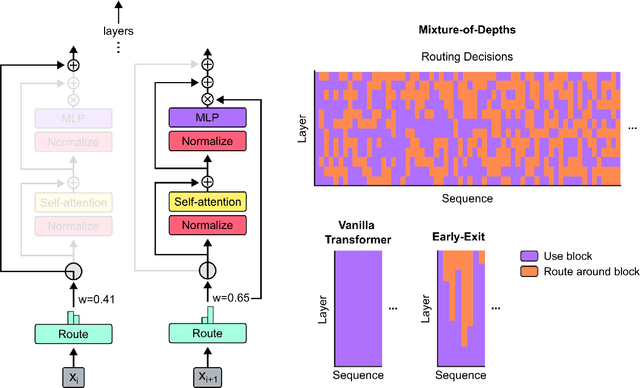
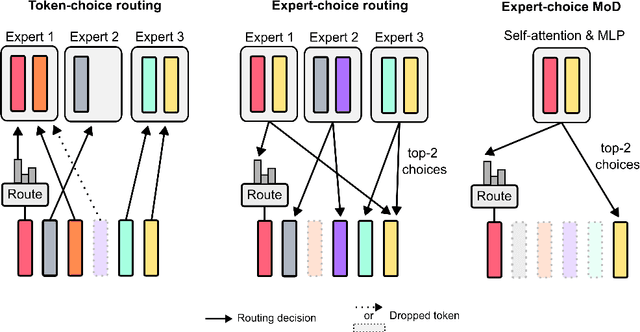
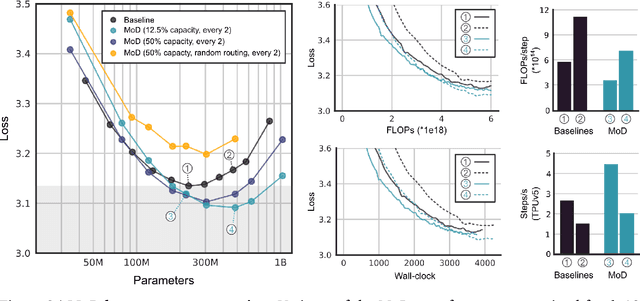
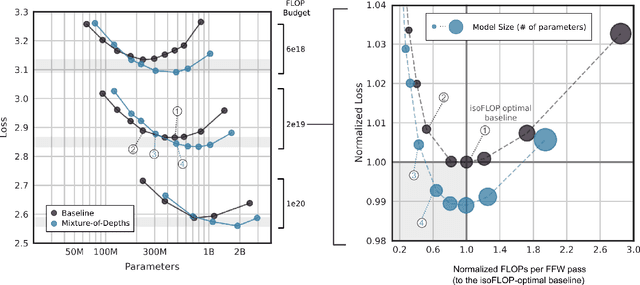
Transformer-based language models spread FLOPs uniformly across input sequences. In this work we demonstrate that transformers can instead learn to dynamically allocate FLOPs (or compute) to specific positions in a sequence, optimising the allocation along the sequence for different layers across the model depth. Our method enforces a total compute budget by capping the number of tokens ($k$) that can participate in the self-attention and MLP computations at a given layer. The tokens to be processed are determined by the network using a top-$k$ routing mechanism. Since $k$ is defined a priori, this simple procedure uses a static computation graph with known tensor sizes, unlike other conditional computation techniques. Nevertheless, since the identities of the $k$ tokens are fluid, this method can expend FLOPs non-uniformly across the time and model depth dimensions. Thus, compute expenditure is entirely predictable in sum total, but dynamic and context-sensitive at the token-level. Not only do models trained in this way learn to dynamically allocate compute, they do so efficiently. These models match baseline performance for equivalent FLOPS and wall-clock times to train, but require a fraction of the FLOPs per forward pass, and can be upwards of 50\% faster to step during post-training sampling.
Addressing Sample Inefficiency in Multi-View Representation Learning
Dec 17, 2023



Non-contrastive self-supervised learning (NC-SSL) methods like BarlowTwins and VICReg have shown great promise for label-free representation learning in computer vision. Despite the apparent simplicity of these techniques, researchers must rely on several empirical heuristics to achieve competitive performance, most notably using high-dimensional projector heads and two augmentations of the same image. In this work, we provide theoretical insights on the implicit bias of the BarlowTwins and VICReg loss that can explain these heuristics and guide the development of more principled recommendations. Our first insight is that the orthogonality of the features is more critical than projector dimensionality for learning good representations. Based on this, we empirically demonstrate that low-dimensional projector heads are sufficient with appropriate regularization, contrary to the existing heuristic. Our second theoretical insight suggests that using multiple data augmentations better represents the desiderata of the SSL objective. Based on this, we demonstrate that leveraging more augmentations per sample improves representation quality and trainability. In particular, it improves optimization convergence, leading to better features emerging earlier in the training. Remarkably, we demonstrate that we can reduce the pretraining dataset size by up to 4x while maintaining accuracy and improving convergence simply by using more data augmentations. Combining these insights, we present practical pretraining recommendations that improve wall-clock time by 2x and improve performance on CIFAR-10/STL-10 datasets using a ResNet-50 backbone. Thus, this work provides a theoretical insight into NC-SSL and produces practical recommendations for enhancing its sample and compute efficiency.
A Unified, Scalable Framework for Neural Population Decoding
Oct 24, 2023



Our ability to use deep learning approaches to decipher neural activity would likely benefit from greater scale, in terms of both model size and datasets. However, the integration of many neural recordings into one unified model is challenging, as each recording contains the activity of different neurons from different individual animals. In this paper, we introduce a training framework and architecture designed to model the population dynamics of neural activity across diverse, large-scale neural recordings. Our method first tokenizes individual spikes within the dataset to build an efficient representation of neural events that captures the fine temporal structure of neural activity. We then employ cross-attention and a PerceiverIO backbone to further construct a latent tokenization of neural population activities. Utilizing this architecture and training framework, we construct a large-scale multi-session model trained on large datasets from seven nonhuman primates, spanning over 158 different sessions of recording from over 27,373 neural units and over 100 hours of recordings. In a number of different tasks, we demonstrate that our pretrained model can be rapidly adapted to new, unseen sessions with unspecified neuron correspondence, enabling few-shot performance with minimal labels. This work presents a powerful new approach for building deep learning tools to analyze neural data and stakes out a clear path to training at scale.
Synaptic Weight Distributions Depend on the Geometry of Plasticity
May 30, 2023



Most learning algorithms in machine learning rely on gradient descent to adjust model parameters, and a growing literature in computational neuroscience leverages these ideas to study synaptic plasticity in the brain. However, the vast majority of this work ignores a critical underlying assumption: the choice of distance for synaptic changes (i.e. the geometry of synaptic plasticity). Gradient descent assumes that the distance is Euclidean, but many other distances are possible, and there is no reason that biology necessarily uses Euclidean geometry. Here, using the theoretical tools provided by mirror descent, we show that, regardless of the loss being minimized, the distribution of synaptic weights will depend on the geometry of synaptic plasticity. We use these results to show that experimentally-observed log-normal weight distributions found in several brain areas are not consistent with standard gradient descent (i.e. a Euclidean geometry), but rather with non-Euclidean distances. Finally, we show that it should be possible to experimentally test for different synaptic geometries by comparing synaptic weight distributions before and after learning. Overall, this work shows that the current paradigm in theoretical work on synaptic plasticity that assumes Euclidean synaptic geometry may be misguided and that it should be possible to experimentally determine the true geometry of synaptic plasticity in the brain.
Transfer Entropy Bottleneck: Learning Sequence to Sequence Information Transfer
Nov 29, 2022When presented with a data stream of two statistically dependent variables, predicting the future of one of the variables (the target stream) can benefit from information about both its history and the history of the other variable (the source stream). For example, fluctuations in temperature at a weather station can be predicted using both temperatures and barometric readings. However, a challenge when modelling such data is that it is easy for a neural network to rely on the greatest joint correlations within the target stream, which may ignore a crucial but small information transfer from the source to the target stream. As well, there are often situations where the target stream may have previously been modelled independently and it would be useful to use that model to inform a new joint model. Here, we develop an information bottleneck approach for conditional learning on two dependent streams of data. Our method, which we call Transfer Entropy Bottleneck (TEB), allows one to learn a model that bottlenecks the directed information transferred from the source variable to the target variable, while quantifying this information transfer within the model. As such, TEB provides a useful new information bottleneck approach for modelling two statistically dependent streams of data in order to make predictions about one of them.
Toward Next-Generation Artificial Intelligence: Catalyzing the NeuroAI Revolution
Oct 15, 2022Neuroscience has long been an important driver of progress in artificial intelligence (AI). We propose that to accelerate progress in AI, we must invest in fundamental research in NeuroAI.
Contrastive introspection (ConSpec) to rapidly identify invariant steps for success
Oct 12, 2022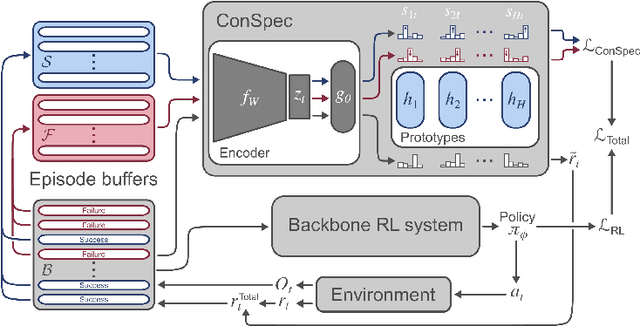
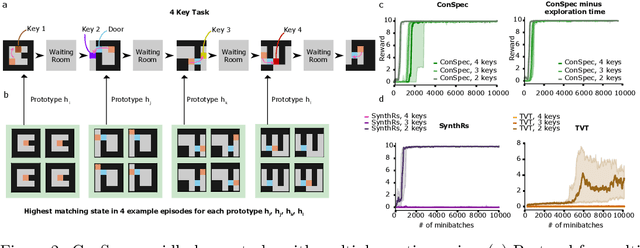
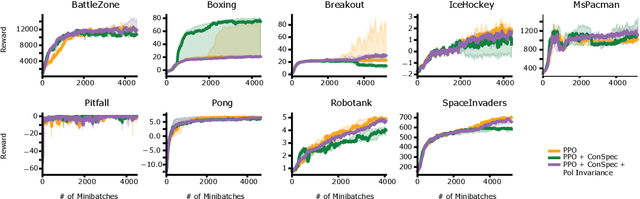
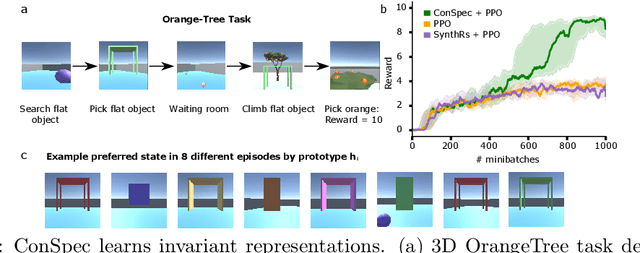
Reinforcement learning (RL) algorithms have achieved notable success in recent years, but still struggle with fundamental issues in long-term credit assignment. It remains difficult to learn in situations where success is contingent upon multiple critical steps that are distant in time from each other and from a sparse reward; as is often the case in real life. Moreover, how RL algorithms assign credit in these difficult situations is typically not coded in a way that can rapidly generalize to new situations. Here, we present an approach using offline contrastive learning, which we call contrastive introspection (ConSpec), that can be added to any existing RL algorithm and addresses both issues. In ConSpec, a contrastive loss is used during offline replay to identify invariances among successful episodes. This takes advantage of the fact that it is easier to retrospectively identify the small set of steps that success is contingent upon than it is to prospectively predict reward at every step taken in the environment. ConSpec stores this knowledge in a collection of prototypes summarizing the intermediate states required for success. During training, arrival at any state that matches these prototypes generates an intrinsic reward that is added to any external rewards. As well, the reward shaping provided by ConSpec can be made to preserve the optimal policy of the underlying RL agent. The prototypes in ConSpec provide two key benefits for credit assignment: (1) They enable rapid identification of all the critical states. (2) They do so in a readily interpretable manner, enabling out of distribution generalization when sensory features are altered. In summary, ConSpec is a modular system that can be added to any existing RL algorithm to improve its long-term credit assignment.