 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Temporal and Structural Context in Graph Transformers for Relational Deep Learning
Nov 06, 2025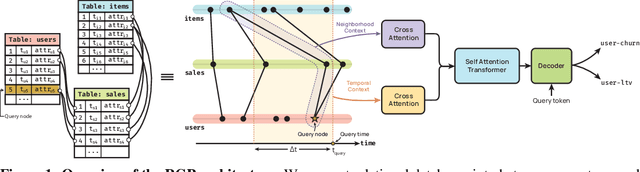
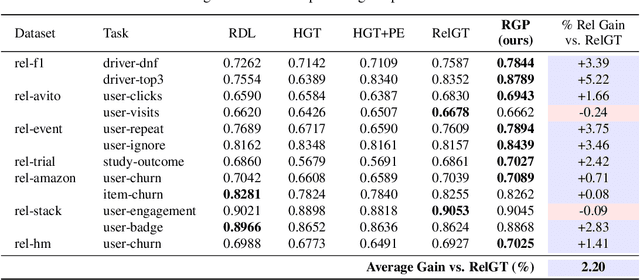
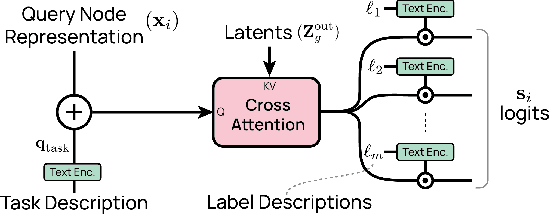

In domains such as healthcare, finance, and e-commerce, the temporal dynamics of relational data emerge from complex interactions-such as those between patients and providers, or users and products across diverse categories. To be broadly useful, models operating on these data must integrate long-range spatial and temporal dependencies across diverse types of entities, while also supporting multiple predictive tasks. However, existing graph models for relational data primarily focus on spatial structure, treating temporal information merely as a filtering constraint to exclude future events rather than a modeling signal, and are typically designed for single-task prediction. To address these gaps, we introduce a temporal subgraph sampler that enhances global context by retrieving nodes beyond the immediate neighborhood to capture temporally relevant relationships. In addition, we propose the Relational Graph Perceiver (RGP), a graph transformer architecture for relational deep learning that leverages a cross-attention-based latent bottleneck to efficiently integrate information from both structural and temporal contexts. This latent bottleneck integrates signals from different node and edge types into a common latent space, enabling the model to build global context across the entire relational system. RGP also incorporates a flexible cross-attention decoder that supports joint learning across tasks with disjoint label spaces within a single model. Experiments on RelBench, SALT, and CTU show that RGP delivers state-of-the-art performance, offering a general and scalable solution for relational deep learning with support for diverse predictive tasks.
GraphFM: A Scalable Framework for Multi-Graph Pretraining
Jul 16, 2024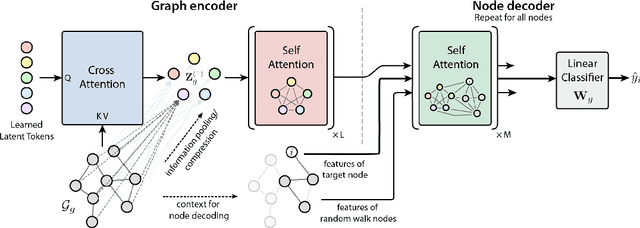
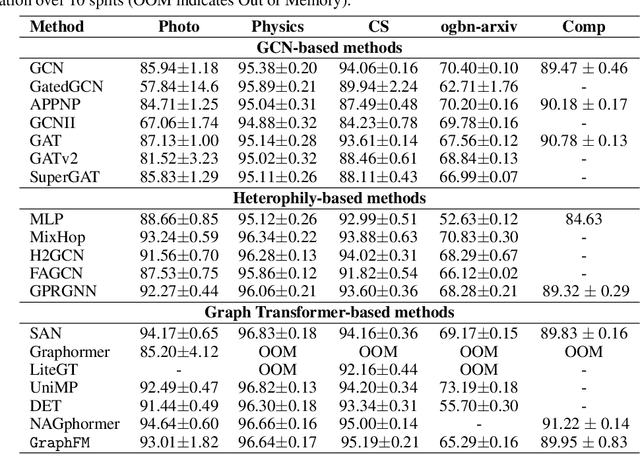
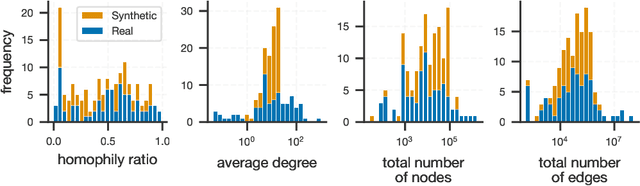
Graph neural networks are typically trained on individual datasets, often requiring highly specialized models and extensive hyperparameter tuning. This dataset-specific approach arises because each graph dataset often has unique node features and diverse connectivity structures, making it difficult to build a generalist model. To address these challenges, we introduce a scalable multi-graph multi-task pretraining approach specifically tailored for node classification tasks across diverse graph datasets from different domains. Our method, Graph Foundation Model (GraphFM), leverages a Perceiver-based encoder that employs learned latent tokens to compress domain-specific features into a common latent space. This approach enhances the model's ability to generalize across different graphs and allows for scaling across diverse data. We demonstrate the efficacy of our approach by training a model on 152 different graph datasets comprising over 7.4 million nodes and 189 million edges, establishing the first set of scaling laws for multi-graph pretraining on datasets spanning many domains (e.g., molecules, citation and product graphs). Our results show that pretraining on a diverse array of real and synthetic graphs improves the model's adaptability and stability, while performing competitively with state-of-the-art specialist models. This work illustrates that multi-graph pretraining can significantly reduce the burden imposed by the current graph training paradigm, unlocking new capabilities for the field of graph neural networks by creating a single generalist model that performs competitively across a wide range of datasets and tasks.
A Unified, Scalable Framework for Neural Population Decoding
Oct 24, 2023



Our ability to use deep learning approaches to decipher neural activity would likely benefit from greater scale, in terms of both model size and datasets. However, the integration of many neural recordings into one unified model is challenging, as each recording contains the activity of different neurons from different individual animals. In this paper, we introduce a training framework and architecture designed to model the population dynamics of neural activity across diverse, large-scale neural recordings. Our method first tokenizes individual spikes within the dataset to build an efficient representation of neural events that captures the fine temporal structure of neural activity. We then employ cross-attention and a PerceiverIO backbone to further construct a latent tokenization of neural population activities. Utilizing this architecture and training framework, we construct a large-scale multi-session model trained on large datasets from seven nonhuman primates, spanning over 158 different sessions of recording from over 27,373 neural units and over 100 hours of recordings. In a number of different tasks, we demonstrate that our pretrained model can be rapidly adapted to new, unseen sessions with unspecified neuron correspondence, enabling few-shot performance with minimal labels. This work presents a powerful new approach for building deep learning tools to analyze neural data and stakes out a clear path to training at scale.