 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified, Scalable Framework for Neural Population Decoding
Oct 24, 2023



Our ability to use deep learning approaches to decipher neural activity would likely benefit from greater scale, in terms of both model size and datasets. However, the integration of many neural recordings into one unified model is challenging, as each recording contains the activity of different neurons from different individual animals. In this paper, we introduce a training framework and architecture designed to model the population dynamics of neural activity across diverse, large-scale neural recordings. Our method first tokenizes individual spikes within the dataset to build an efficient representation of neural events that captures the fine temporal structure of neural activity. We then employ cross-attention and a PerceiverIO backbone to further construct a latent tokenization of neural population activities. Utilizing this architecture and training framework, we construct a large-scale multi-session model trained on large datasets from seven nonhuman primates, spanning over 158 different sessions of recording from over 27,373 neural units and over 100 hours of recordings. In a number of different tasks, we demonstrate that our pretrained model can be rapidly adapted to new, unseen sessions with unspecified neuron correspondence, enabling few-shot performance with minimal labels. This work presents a powerful new approach for building deep learning tools to analyze neural data and stakes out a clear path to training at scale.
Half-Hop: A graph upsampling approach for slowing down message passing
Aug 17, 2023
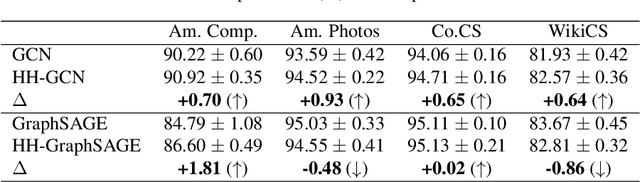

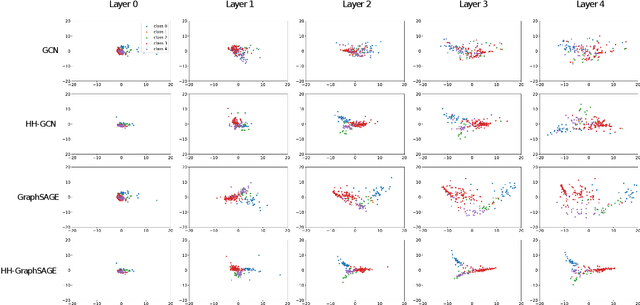
Message passing neural networks have shown a lot of success on graph-structured data. However, there are many instances where message passing can lead to over-smoothing or fail when neighboring nodes belong to different classes. In this work, we introduce a simple yet general framework for improving learning in message passing neural networks. Our approach essentially upsamples edges in the original graph by adding "slow nodes" at each edge that can mediate communication between a source and a target node. Our method only modifies the input graph, making it plug-and-play and easy to use with existing models. To understand the benefits of slowing down message passing, we provide theoretical and empirical analyses. We report results on several supervised and self-supervised benchmarks, and show improvements across the board, notably in heterophilic conditions where adjacent nodes are more likely to have different labels. Finally, we show how our approach can be used to generate augmentations for self-supervised learning, where slow nodes are randomly introduced into different edges in the graph to generate multi-scale views with variable path lengths.
Accelerating Genetic Programming using GPUs
Oct 15, 2021


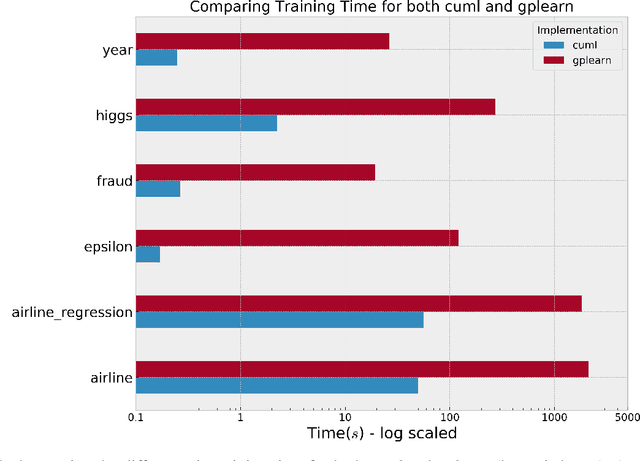
Genetic Programming (GP), an evolutionary learning technique, has multiple applications in machine learning such as curve fitting, data modelling, feature selection, classification etc. GP has several inherent parallel steps, making it an ideal candidate for GPU based parallelization. This paper describes a GPU accelerated stack-based variant of the generational GP algorithm which can be used for symbolic regression and binary classification. The selection and evaluation steps of the generational GP algorithm are parallelized using CUDA. We introduce representing candidate solution expressions as prefix lists, which enables evaluation using a fixed-length stack in GPU memory. CUDA based matrix vector operations are also used for computation of the fitness of population programs. We evaluate our algorithm on synthetic datasets for the Pagie Polynomial (ranging in size from $4096$ to $16$ million points), profiling training times of our algorithm with other standard symbolic regression libraries viz. gplearn, TensorGP and KarooGP. In addition, using $6$ large-scale regression and classification datasets usually used for comparing gradient boosting algorithms, we run performance benchmarks on our algorithm and gplearn, profiling the training time, test accuracy, and loss. On an NVIDIA DGX-A100 GPU, our algorithm outperforms all the previously listed frameworks, and in particular, achieves average speedups of $119\times$ and $40\times$ against gplearn on the synthetic and large scale datasets respectively.