 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable, real-time neural decoding with hybrid state-space models
Jun 05, 2025Real-time decoding of neural activity is central to neuroscience and neurotechnology applications, from closed-loop experiments to brain-computer interfaces, where models are subject to strict latency constraints. Traditional methods, including simple recurrent neural networks, are fast and lightweight but often struggle to generalize to unseen data. In contrast, recent Transformer-based approaches leverage large-scale pretraining for strong generalization performance, but typically have much larger computational requirements and are not always suitable for low-resource or real-time settings. To address these shortcomings, we present POSSM, a novel hybrid architecture that combines individual spike tokenization via a cross-attention module with a recurrent state-space model (SSM) backbone to enable (1) fast and causal online prediction on neural activity and (2) efficient generalization to new sessions, individuals, and tasks through multi-dataset pretraining. We evaluate POSSM's decoding performance and inference speed on intracortical decoding of monkey motor tasks, and show that it extends to clinical applications, namely handwriting and speech decoding in human subjects. Notably, we demonstrate that pretraining on monkey motor-cortical recordings improves decoding performance on the human handwriting task, highlighting the exciting potential for cross-species transfer. In all of these tasks, we find that POSSM achieves decoding accuracy comparable to state-of-the-art Transformers, at a fraction of the inference cost (up to 9x faster on GPU). These results suggest that hybrid SSMs are a promising approach to bridging the gap between accuracy, inference speed, and generalization when training neural decoders for real-time, closed-loop applications.
Expressivity of Neural Networks with Random Weights and Learned Biases
Jul 02, 2024



Landmark universal function approximation results for neural networks with trained weights and biases provided impetus for the ubiquitous use of neural networks as learning models in Artificial Intelligence (AI) and neuroscience. Recent work has pushed the bounds of universal approximation by showing that arbitrary functions can similarly be learned by tuning smaller subsets of parameters, for example the output weights, within randomly initialized networks. Motivated by the fact that biases can be interpreted as biologically plausible mechanisms for adjusting unit outputs in neural networks, such as tonic inputs or activation thresholds, we investigate the expressivity of neural networks with random weights where only biases are optimized. We provide theoretical and numerical evidence demonstrating that feedforward neural networks with fixed random weights can be trained to perform multiple tasks by learning biases only. We further show that an equivalent result holds for recurrent neural networks predicting dynamical system trajectories. Our results are relevant to neuroscience, where they demonstrate the potential for behaviourally relevant changes in dynamics without modifying synaptic weights, as well as for AI, where they shed light on multi-task methods such as bias fine-tuning and unit masking.
A Unified, Scalable Framework for Neural Population Decoding
Oct 24, 2023



Our ability to use deep learning approaches to decipher neural activity would likely benefit from greater scale, in terms of both model size and datasets. However, the integration of many neural recordings into one unified model is challenging, as each recording contains the activity of different neurons from different individual animals. In this paper, we introduce a training framework and architecture designed to model the population dynamics of neural activity across diverse, large-scale neural recordings. Our method first tokenizes individual spikes within the dataset to build an efficient representation of neural events that captures the fine temporal structure of neural activity. We then employ cross-attention and a PerceiverIO backbone to further construct a latent tokenization of neural population activities. Utilizing this architecture and training framework, we construct a large-scale multi-session model trained on large datasets from seven nonhuman primates, spanning over 158 different sessions of recording from over 27,373 neural units and over 100 hours of recordings. In a number of different tasks, we demonstrate that our pretrained model can be rapidly adapted to new, unseen sessions with unspecified neuron correspondence, enabling few-shot performance with minimal labels. This work presents a powerful new approach for building deep learning tools to analyze neural data and stakes out a clear path to training at scale.
Capturing cross-session neural population variability through self-supervised identification of consistent neuron ensembles
May 19, 2022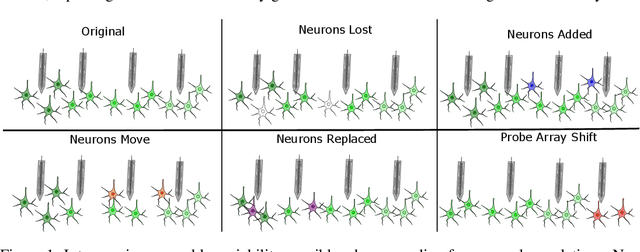


Decoding stimuli or behaviour from recorded neural activity is a common approach to interrogate brain function in research, and an essential part of brain-computer and brain-machine interfaces. Reliable decoding even from small neural populations is possible because high dimensional neural population activity typically occupies low dimensional manifolds that are discoverable with suitable latent variable models. Over time however, drifts in activity of individual neurons and instabilities in neural recording devices can be substantial, making stable decoding over days and weeks impractical. While this drift cannot be predicted on an individual neuron level, population level variations over consecutive recording sessions such as differing sets of neurons and varying permutations of consistent neurons in recorded data may be learnable when the underlying manifold is stable over time. Classification of consistent versus unfamiliar neurons across sessions and accounting for deviations in the order of consistent recording neurons in recording datasets over sessions of recordings may then maintain decoding performance. In this work we show that self-supervised training of a deep neural network can be used to compensate for this inter-session variability. As a result, a sequential autoencoding model can maintain state-of-the-art behaviour decoding performance for completely unseen recording sessions several days into the future. Our approach only requires a single recording session for training the model, and is a step towards reliable, recalibration-free brain computer interfaces.
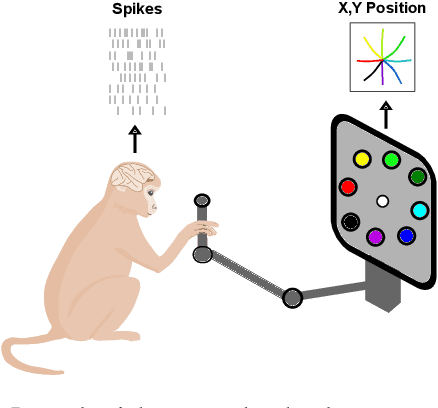
Machine learning for neural decoding
May 04, 2018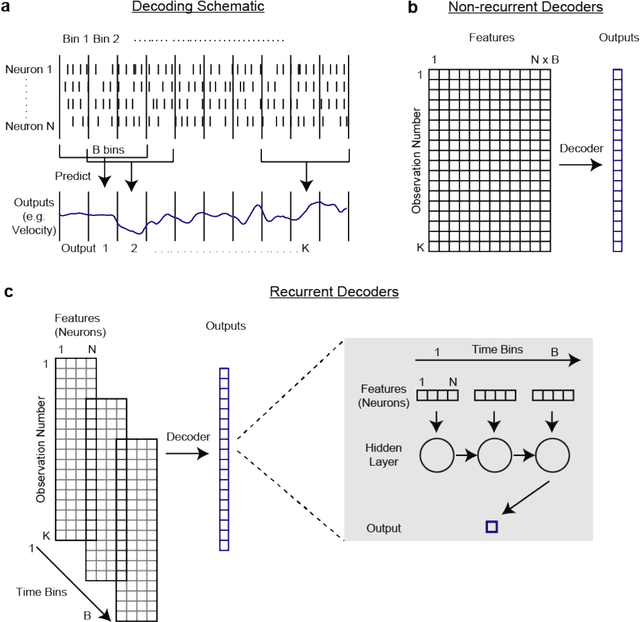

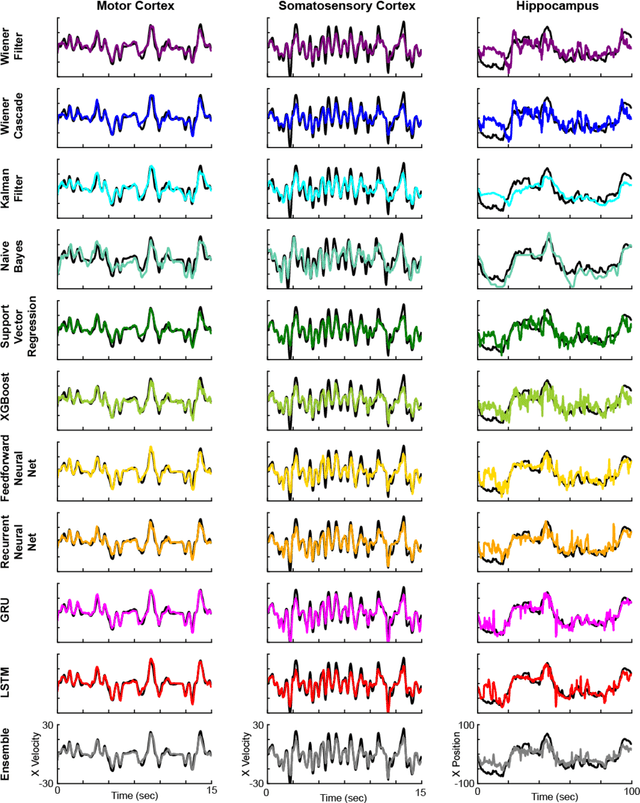
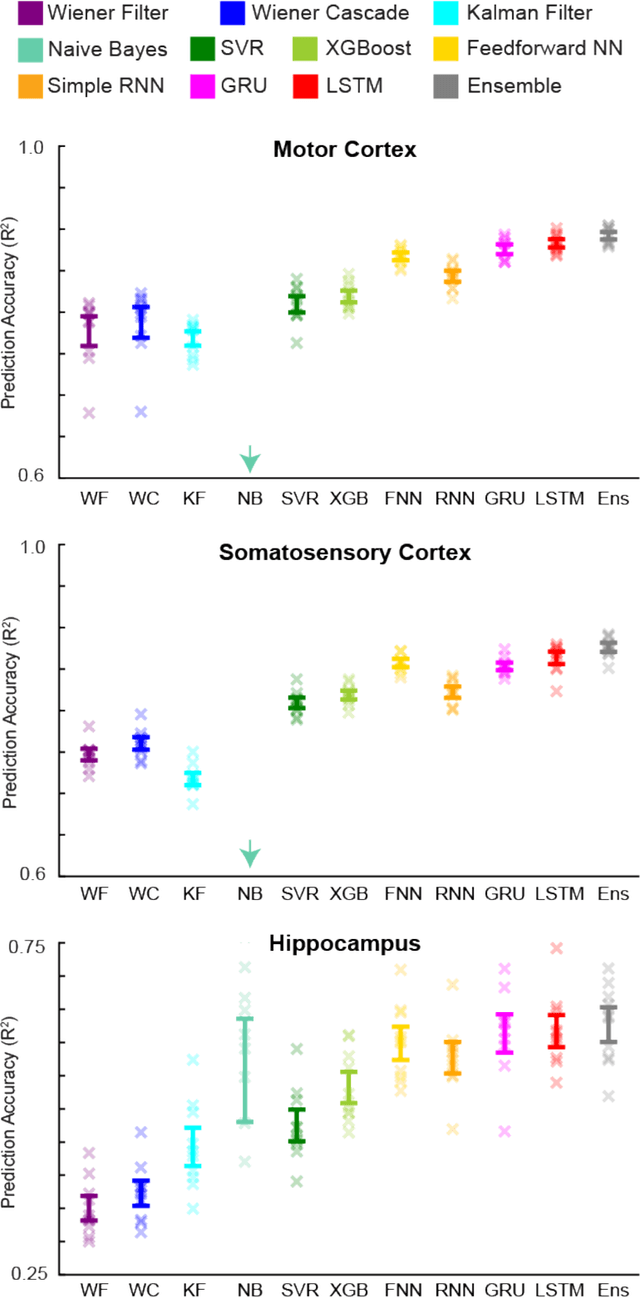
Despite rapid advances in machine learning tools, the majority of neural decoding approaches still use traditional methods. Improving the performance of neural decoding algorithms allows us to better understand the information contained in a neural population, and can help advance engineering applications such as brain machine interfaces. Here, we apply modern machine learning techniques, including neural networks and gradient boosting, to decode from spiking activity in 1) motor cortex, 2) somatosensory cortex, and 3) hippocampus. We compare the predictive ability of these modern methods with traditional decoding methods such as Wiener and Kalman filters. Modern methods, in particular neural networks and ensembles, significantly outperformed the traditional approaches. For instance, for all of the three brain areas, an LSTM decoder explained over 40% of the unexplained variance from a Wiener filter. These results suggest that modern machine learning techniques should become the standard methodology for neural decoding. We provide a tutorial and code to facilitate wider implementation of these methods.