 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphFM: A Scalable Framework for Multi-Graph Pretraining
Paper and Code
Jul 16, 2024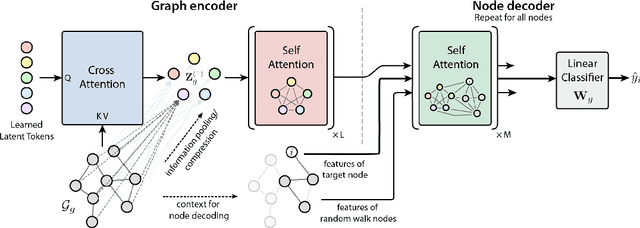
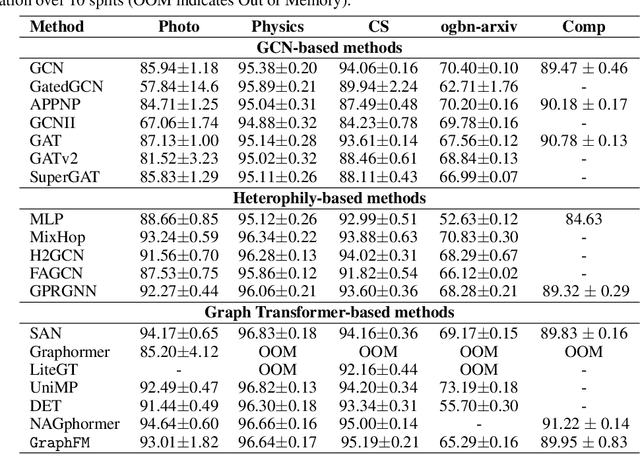
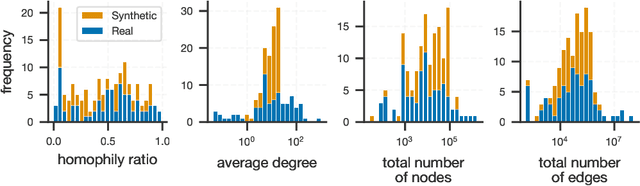
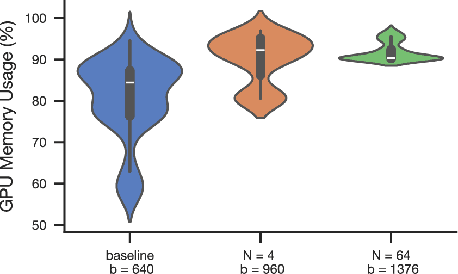
Graph neural networks are typically trained on individual datasets, often requiring highly specialized models and extensive hyperparameter tuning. This dataset-specific approach arises because each graph dataset often has unique node features and diverse connectivity structures, making it difficult to build a generalist model. To address these challenges, we introduce a scalable multi-graph multi-task pretraining approach specifically tailored for node classification tasks across diverse graph datasets from different domains. Our method, Graph Foundation Model (GraphFM), leverages a Perceiver-based encoder that employs learned latent tokens to compress domain-specific features into a common latent space. This approach enhances the model's ability to generalize across different graphs and allows for scaling across diverse data. We demonstrate the efficacy of our approach by training a model on 152 different graph datasets comprising over 7.4 million nodes and 189 million edges, establishing the first set of scaling laws for multi-graph pretraining on datasets spanning many domains (e.g., molecules, citation and product graphs). Our results show that pretraining on a diverse array of real and synthetic graphs improves the model's adaptability and stability, while performing competitively with state-of-the-art specialist models. This work illustrates that multi-graph pretraining can significantly reduce the burden imposed by the current graph training paradigm, unlocking new capabilities for the field of graph neural networks by creating a single generalist model that performs competitively across a wide range of datasets and tasks.