 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobin: a Suite of Multi-Scale Vision-Language Models and the CHIRP Evaluation Benchmark
Jan 16, 2025



The proliferation of Vision-Language Models (VLMs) in the past several years calls for rigorous and comprehensive evaluation methods and benchmarks. This work analyzes existing VLM evaluation techniques, including automated metrics, AI-based assessments, and human evaluations across diverse tasks. We first introduce Robin - a novel suite of VLMs that we built by combining Large Language Models (LLMs) and Vision Encoders (VEs) at multiple scales, and use Robin to identify shortcomings of current evaluation approaches across scales. Next, to overcome the identified limitations, we introduce CHIRP - a new long form response benchmark we developed for more robust and complete VLM evaluation. We provide open access to the Robin training code, model suite, and CHIRP benchmark to promote reproducibility and advance VLM research.
Interpretability in Action: Exploratory Analysis of VPT, a Minecraft Agent
Jul 16, 2024Understanding the mechanisms behind decisions taken by large foundation models in sequential decision making tasks is critical to ensuring that such systems operate transparently and safely. In this work, we perform exploratory analysis on the Video PreTraining (VPT) Minecraft playing agent, one of the largest open-source vision-based agents. We aim to illuminate its reasoning mechanisms by applying various interpretability techniques. First, we analyze the attention mechanism while the agent solves its training task - crafting a diamond pickaxe. The agent pays attention to the last four frames and several key-frames further back in its six-second memory. This is a possible mechanism for maintaining coherence in a task that takes 3-10 minutes, despite the short memory span. Secondly, we perform various interventions, which help us uncover a worrying case of goal misgeneralization: VPT mistakenly identifies a villager wearing brown clothes as a tree trunk when the villager is positioned stationary under green tree leaves, and punches it to death.
Lag-Llama: Towards Foundation Models for Time Series Forecasting
Oct 12, 2023
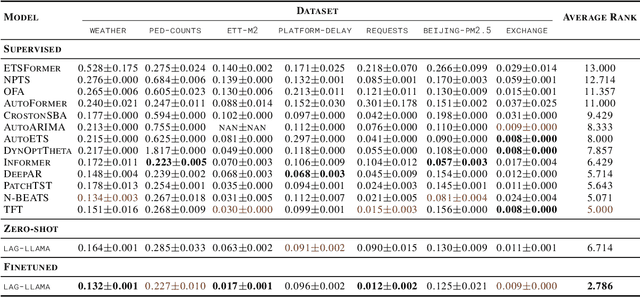

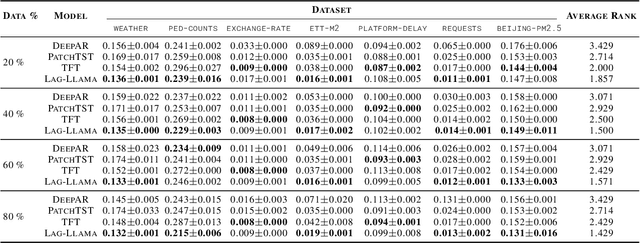
Aiming to build foundation models for time-series forecasting and study their scaling behavior, we present here our work-in-progress on Lag-Llama, a general-purpose univariate probabilistic time-series forecasting model trained on a large collection of time-series data. The model shows good zero-shot prediction capabilities on unseen "out-of-distribution" time-series datasets, outperforming supervised baselines. We use smoothly broken power-laws to fit and predict model scaling behavior. The open source code is made available at https://github.com/kashif/pytorch-transformer-ts.